
分治法是将规模较大的问题分解为规模较小的子问题,解决各个子问题然后合并得到原问题的答案。
常见的树分治方法:
- 点分治
- 边分治
- 链分治
- link cut tree
- top tree
其中链分治就是树链剖分,静态链分治是 dsu on tree。
这里主要介绍点分治和边分治,link cut tree 和 top tree 以后有机会再讲。
注:
- 其实会点分治和链分治就够用了
- 实际上,
top tree是目前最通用化的树分治处理结构 - $\rm{LCT}$ 可以经过进一步拓展实现 $\rm{LCT}$ 维护子树,再进一步拓展成为 $\rm{top \ tree}$,由于 $\rm{top \ tree}$ 具有维护子树动态 $\rm{DP}$ 信息的性质,所以实质上 $\rm{top \ tree}$ 可以看做是动态化的树链剖分,即动态化的链分治
一、点分治
点分治,是一种针对可带权树上简单路径统计问题的算法。本质是一种带优化的暴力,带上一点容斥原理。
对于树上路径,并不要求这颗树是有根树,无根树不影响统计结果。
分治法的核心是分解和治理。如何分?如何治?
重心分解
数列上的分治法,通常从数列中间进行二等分,也就是说分解得到的两个子问题规模相当。如果将 $n$ 个数分解为 $1$ 个和 $n-1$ 个,那么分治法就会退化为暴力枚举。那么树怎么划分呢?
树上的划分也要尽量均衡,不要出现一个子问题太大,另一个子问题太小的情况。也就是说期望划分后每个子树的节点数不超过 $\frac{n}{2}$。
那么选择哪个节点作为划分点呢?
可以选择树的重心。树的重心是指删除该节点后得到的最大子树的节点数最少。删除重心后得到的所有子树,其节点数不然不超过 $\frac{n}{2}$。
证明:
如果 $s$ 为树的重心,即删除 $s$ 后得到的最大子树 $T_1$ 节点数最少。假设 $T_1$ 节点数 $m > \frac{n}{2}$,则 $s$ 为根的子树节点数 $< \frac{n}{2}$。如果选择 $T_1$ 的根节点 $t$ 为重心,在得到的最大子树 $T_2$ 节点数为 $m-1(m > \frac{n}{2})$,很明显 $T_2 < T_1$,显然删除 $s$ 后得到的最大子树 $T_1$ 节点数不是最少的,这与 $s$ 是树的重心矛盾。
求树的重心,只需要进行一次深度优先遍历,找删除该节点后最大子树最小的节点即可。
用 f[u] 表示删除点 $u$ 后最大子树的大小,size[u] 表示以点 $u$ 为根的子树的节点数,S 表示整颗子树的节点数。先统计点 $u$ 的所有子树中最大子树的节点数,然后与 $S-\operatorname{size}[u]$ 比较取最大值。如图所示
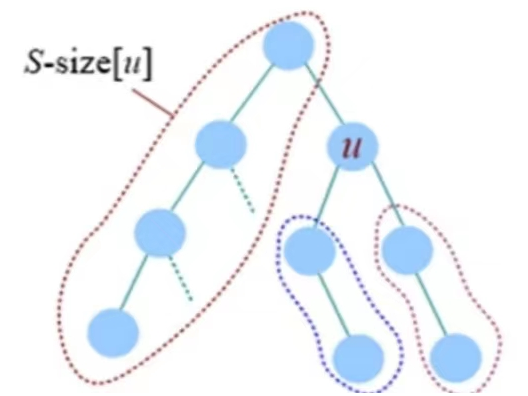
如果 $f[u] < f[root]$,则更新当前树的重心为 $root = u$ 。
例题: Fixed-Length Paths I
给定一颗含有 $N$ 颗节点的树,要求恰经过 $k$ 条边的不同路径数。
限制:
- $1 \leqslant k \leqslant n \leqslant 2 \times 10^5$
算法分析
给定一个点 $v$,我们知道树上任意一条路径或者经过点 $v$ 或者完全包含在点 $v$ 的某个孩子节点的子树中。这意味着要解决包含点 $v$ 的树上的问题,我们可以:
- 统计经过点 $v$ 的长度为 $k$ 的路径数
- 删除点 $v$ 以及树上和点 $v$ 所关联的边
- 递归地解决所形成的新树上的问题
统计经过 $v$ 的路径数
我们可以在 $O(M)$ 的时间内统计大小为 $M$ 的树中经过点 $v$ 的路径数
我们按顺序处理点 $v$ 的每个孩子节点的子树。令 $cnt_i[d]$ 表示在处理完点 $v$ 的前 $i$ 个孩子节点的子树后走 $d$ 步可到达的点数。在点 $v$ 的第 $i$ 个孩子节点的子树中,深度为 $d$ 的点将对答案贡献 $cnt_{i-1}[k-d]$ 条路径。
对每个孩子跑两个 $\operatorname{DFS}$,我们可以计算出它的贡献,然后在 $O(M)$ 的时间内更新 $cnt$ 。
应用重心分解
我们可以结合前面重心分解的思想在 $O(N\log N)$ 的时间内解决问题
当我们处理到某颗子树时,我们可以简单地把点 $v$ 作为那颗树的重心。由于重心树的深度为 $O(\log N)$,且质心树上每一层都需要花费均摊时间 $O(N)$ 来处理。所以总复杂度为 $O(N\log N)$ 。
代码实现
#include <bits/stdc++.h>
#define rep(i, n) for (int i = 0; i < (n); ++i)
using namespace std;
using ll = long long;
const int MX = 200005;
int n, k;
vector<int> to[MX];
bool used[MX];
int sz[MX];
int tfs(int v, int p=0) {
sz[v] = 1;
for (int u : to[v]) {
if (used[u] or u == p) continue;
sz[v] += tfs(u, v);
}
return sz[v];
}
int get_centroid(int desired, int v, int p=0) {
for (int u : to[v]) {
if (used[u] or u == p) continue;
if (sz[u] >= desired) {
return get_centroid(desired, u, v);
}
}
return v;
}
ll ans = 0;
int cnt[MX]{1}, mx_d;
void get_cnt(int v, int p, bool filling, int d=1) {
if (d > k) return;
mx_d = max(mx_d, d);
if (filling) cnt[d]++;
else ans += cnt[k-d];
for (int u : to[v]) {
if (used[u] or u == p) continue;
get_cnt(u, v, filling, d+1);
}
}
void centroid_decomp(int v) {
int centroid = get_centroid(tfs(v)/2, v);
used[centroid] = true;
mx_d = 0;
for (int u : to[centroid]) {
if (used[u]) continue;
get_cnt(u, centroid, false);
get_cnt(u, centroid, true);
}
fill(cnt+1, cnt+mx_d+1, 0);
for (int u : to[centroid]) if (!used[u]) centroid_decomp(u);
}
int main() {
cin.tie(nullptr) -> sync_with_stdio(false);
cin >> n >> k;
rep(i, n-1) {
int a, b;
cin >> a >> b;
to[a].push_back(b);
to[b].push_back(a);
}
centroid_decomp(1);
cout << ans << '\n';
return 0;
}
