
哈希入门
为了便于广大算法爱好者和本人复习,加深对算法的理解,将持续更新基础算法,希望大家有所收获hh
(我能说是被学妹逼得吗,呜呜呜~)
众所周知,比较两个字符串是否相同复杂度在最差情况下是O ( n ),虽然期望是O ( 1 ),但很容易就会被毒瘤出题人卡成O ( n ) ,于是字符串哈希就应运而生了。
来讲讲哈希的主要思想, 它就是把一个字符串中的每一个字符都可以对应一个ACSll码,于是就可以把每一个字符乘上一个进制数再取模,就像十进制一样,一个字符串s 的第i 位字符(下标从1开始)所对应的哈希值就是
s[i] * base^(n-i)
注意的是, 这里的base是我们自己定义的进制数,一般可以选233,10007等质数, 不要太小就行。同理,对每一位字符进行哈希处理并且累加,我们就得到了一串字符的哈希值
举个简单的例子
当 n = 3 的时候, hash(s) = s[1] * M^2 + s[2] * M + s[3]
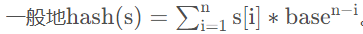
求一个字符串的哈希值代码如下:
int hash(char *s)
{
int len = strlen(s), ans = 0;
for (int i = 1; i <= len; i++)
ans = ((ll)ans * M + s[i]) % N;
return ans;
}
每次累加时模上一个大质数,大多采用1e9+7、1e9+9、998244353等,当然也可以选择自然溢出,就是不进行取模操作。
为什么选大的质数捏?
字符串哈希的基本操作
比起得到整个字符串的哈希值,更多时候我们更希望得到该字符串某一子串的哈希值,即给定区间[l,r],求这段区间内子串哈希值。或者求区间[l1, r1], [l2, r2](区间不相交)这两子串拼接以后的哈希值,又该如何操作呢?我们一个一个来看。
1.求[l, r]字串的哈希值
联系前缀表的相关知识, 我们很容易想到去制作一个前缀哈希表, h[i]的值代表区间[l,i]字串的哈希值, h[n]就代表整个字符串的哈希值
前缀表代码
//M为进制数,N为取模的大质数
for (int i = 1; i <= n; ++i)
{
h[i] = ((ll)h[i - 1] * M + s[i]) % N;
base[i] = ((ll)base[i - 1] * M) % N;
}
这里的h[i]可以联系十进制,比如在1234后面加个5, 那么就是1234 * 10 + 5, 这里的10就是对应的进制数M,
5对应新增的字符s[i] , 1234对应[1, i - 1]字符串的哈希值。 这里的base[i] 表示 M^i 对 N取模后的结果, 后面计算有用
现在我们考虑区间[l, r]字串的哈希值, 根据进制哈希的定义得到

代码如下:
int get(int l, int r)
{
return ((h[r] - (ll)hash[l - 1] * base[r - l + 1]) % N + N) % N;
}
2.求解[l1, r1], [l2, r2]字串并的哈希值

代码如下:
int merge(int l1, int r1, int l2, int r2)
{
return ((ll)get(l1, r1) * base[r2 - l2 + 1] + get(l2, r2)) % N;
}
总结:
相信看到这里, 你已经对哈希的思想已经有了初步的认识。
字符串哈希为我们比较字符串比较提供了一个高效的方向,然而字符串哈希远不止这些,还有许多值得我们去探索!
后续可以看我的下一篇

低配版简化版:unordered_map
佬说的是捏