
题目描述
一些生物的结构组成可以由大写字母序列来表示。
生物学家们喜欢将长序列拆分成较短序列来进行研究。
给定一个由若干短序列构成的集合 $P$,如果从中选取部分元素(可使用多次)能够拼接成一个序列 $S$,那么就说 $S$ 由 $P$ 组成。
$S$ 可以只包含 $P$ 中的部分元素,例如,序列 ABABACABAAB 就可以由集合 {A,AB,BA,CA,BBC} 组成。
$S$ 的前 $K$ 个字符称为 $S$ 的长度为 $K$ 的前缀。
现在给定一个短序列集合 $P$ 以及一个大写字母序列 $S$,请你求出可以由集合 $P$ 组成的 $S$ 的最长前缀的长度是多少。
输入格式
首先,将输入短序列集合 $P$,集合中的元素将在一行或多行中给出,每个短序列之间用空格隔开。
集合的所有元素都输入完毕后,会在独立的一行输入一个 . 表明集合已经输入完毕。
保证集合中的元素互不相同。
然后输入大写字母序列 $S$,序列可能占一行或多行,每行最多包含 $76$ 个字母,换行符不是序列的一部分。
输出格式
输出一个整数,表示可组成的最长前缀的长度。
输入样例
A AB BA CA BBC
.
ABABACABAABC
输出样例
11
DP + 字符串哈希 $Len(max(p))O(s)$
废话不多说,直接上图
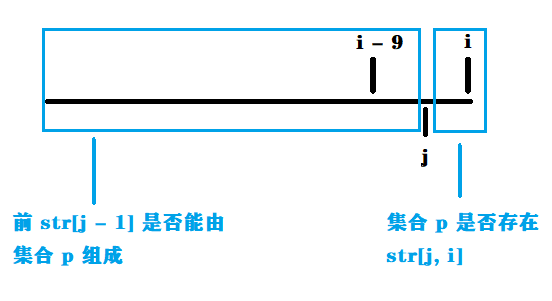
字符串匹配直接用哈希做,时间复杂度为 $O(1)$,比 kmp 快多了,我一直觉得字符串哈希比 kmp 优秀多了,又好写,而且还快。
注意越界处理,y 总视频没处理越界。
C++ 代码
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_set>
using namespace std;
typedef unsigned long long ULL;
const int N = 200010, P = 131;
string str;
bool f[N];
int main()
{
unordered_set <ULL> hash;
while (cin >> str && str != ".") {
ULL h = 0;
// 从后往前求解哈希值
for (int i = str.size() - 1; i >= 0; --i) {
h = h * P + str[i];
}
hash.insert(h);
}
str.clear();
string line;
while (cin >> line) str += line;
f[0] = true; // 空串默认能组合成功
int res = 0;
for (int i = 1; i <= str.size(); ++i) {
ULL h = 0;
for (int j = i; j > i - 10; --j) {
if (j - 1 < 0) { // 越界处理
break;
}
h = h * P + str[j - 1]; // 匹配 str 下标
if (hash.count(h) && f[j - 1]) { // 判断集合是否存在该短序列 str[j, i] 及前缀为 str[j - 1] 是否能组合上
f[i] = true;
}
}
if (f[i]) {
res = i;
}
}
cout << res << endl;
return 0;
}
