
最短路
1. 树与图的存储
树是一种 特殊的图,与图的 存储方式 相同。
对于 无向图 中的边 ab,存储两条 有向边
add(a, b, c), add(b, a, c);
或者是
g[a][b] = g[b][a] = min(g[a][b], c);
因此我们可以只考虑有向图的存储。
朴素dijkstra算法
前置准备:
-
邻接矩阵 或 邻接表
-
邻接表要初始化 表头
memset(h, -1, sizeof h)
- 邻接矩阵要初始化 存边的数组 (爆 long long 的话,要用双重循环更新)
memset(g, 0x3f, sizeof g)
for (int i = 0; i < n; i ++ ) g[i][i] = 0; // 自己到自己的距离为 0;
- 初始化 距离数组 为一个大值, 源点的距离为 0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 也有可能是其它点
- 建立 st[] 存储每个点的最短路 是否已经确定
算法步骤:
//---------------------------------------------------------------------------\\
//Dijkstra-朴素O(n^2)
1. 使用一个 dist[] 数组用来存储从 源点 到其它点的距离。初始化 dist[1] = 0 ,其它点的 dist 值为 正无穷大(可以使用一个很大的数来表示,比如 0x3f3f3f3f)。
2. 找到一个尚未确定并且距离起点距离最近的点 t。然后标记该节点。
3. 扫描节点 t 的所有 出边(t -> j),如果 源点 到 j 的距离比源点到 t 再从 t 到 j 的距离 g[t][j] 之和大,那么就使 dist[j] = dist[t] + g[t][j]。
4. 重复步骤 2 和 3 直到所有的点都被标记。
//---------------------------------------------------------------------------\\
时间复杂是 $O(n^2+m)$, $n$ 表示点数,$m$ 表示边数
int g[N][N]; // 存储每条边
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ )
{
int t = -1; // 在还未确定最短路的点中,寻找距起点距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
堆优化dijkstra算法 (重点)
前置准备:
-
邻接表 和 小根堆
-
邻接表要初始化 表头
memset(h, -1, sizeof h)
- 初始化 距离数组 为一个大值, 源点的距离为 0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 也有可能是其它点
-
建立 st[] 存储每个点的最短路是否已经确定
-
建立小根堆
// PII 可以替换为任何一个变量类型
priority_queue<PII, greater<PII>, greater<PII> > heap;
结构体 + 小根堆 :
struct Point
{
int ...;
bool operator < (const Point &b) const {
return num < b.num;
}
}ranks[];
...
priority_queue<Point, vector<Point>, greater<Point> > heap;
算法步骤:
//---------------------------------------------------------------------------\\
Dijkstra-堆优化O(mlogm)
// 将源点的节点距离和编号加入堆中, 更新 dist[源点] = 0;
// 堆不空, 弹出距源点最短距离的点的状态
// 如果没有处理过这个点, 就将 st[] 设为处理过, 否则就返回重找
// 更新这个点的所有出边,按照 a -> c = min(a -> c, a -> b + b -> c) 的方式更新
// 如果这个点在上一步更新过就将这个点加入堆中
//---------------------------------------------------------------------------\\
时间复杂度 $O(mlogn)$ STL是 $O(mlogm)$, $n$ 表示点数,$m$ 表示边数
typedef pair<int, int> PII;
int n; // 点的数量
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储所有点到1号点的距离
bool st[N]; // 存储每个点的最短距离是否已确定
// 求1号点到n号点的最短距离,如果不存在,则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 第一个节点离自己的距离为 0
priority_queue<PII, vector<PII>, greater<PII>> heap; //建立小根堆
heap.push({0, 1}); // 0 是节点距离,1 是节点编号
while (heap.size()) // 队列不为空,还有点没有用来更新
{
auto t = heap.top(); // 先取出队列内第一个元素
heap.pop(); // 弹出第一个,下次取下一个
int ver = t.second, distance = t.first;
// second 是节点的编号, first 是节点距第一个节点的距离
if (st[ver]) continue; // 如果处理过这个点,就返回
st[ver] = true; //否则,就处理这个点
for (int i = h[ver]; i != -1; i = ne[i]){
// 从 h[ver] 开始,更新与 h[ver] 有连边的所有点的距离。
int j = e[i]; //取出当前邻边的节点
if (dist[j] > dist[ver] + w[i]){
//如果它与 h[ver] 的距离小于新更新的距离
dist[j] = dist[ver] + w[i]; // 更新距离
heap.push({dist[j], j}); // 将确定了距离的点装入堆中
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1; // 如果没有更新,即走不到
return dist[n]; // 返回值
}
Bellman-Ford算法
前置准备:
- 结构体
struct Edge
{
int a, b, c;
}edges[M];
edges[i] = {a, b, c};
- 初始化 距离数组 为一个大值, 源点的距离为 0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 也有可能是其它点
算法步骤:
//---------------------------------------------------------------------------\\
Bellman-Ford O(nm)
-
//先松弛S, P1,此时dist[P1]必然等于e[S][P1]。
//再松弛P1, P2,因为S->P1->P2是最短路的一部分,最短路的子路也是最短路(这是显然的),所以dist[P2]不可能小于dist[P1]+e[P1][P2],因此它会被更新为dist[P1]+e[P1][P2],即e[S][P1]+e[P1][P2]。
//再松弛P2, P3,……以此类推,最终dist[D]必然等于e[S][P1]+e[P1][P2]+...,这恰好就是最短路径。
//---------------------------------------------------------------------------\\

时间复杂度 $O(nm)$, $n$ 表示点数,$m$ 表示边数
int n, m; // n表示点数,m表示边数
int dist[N]; // dist[x]存储1到x的最短路距离
struct Edge // 边,a表示出点,b表示入点,w表示边的权重
{
int a, b, w;
}edges[M];
// 求1到n的最短路距离,如果无法从1走到n,则返回-1。
int bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 如果第n次迭代仍然会松弛三角不等式,就说明存在一条长度是n+1的最短路径,由抽屉原理,路径中至少存在两个相同的点,说明图中存在负权回路。
for (int i = 0; i < n; i ++ )
{
for (int j = 0; j < m; j ++ )
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] > dist[a] + w)
dist[b] = dist[a] + w;
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
spfa 算法 (重点)
前置准备:
-
邻接表 和 队列
-
邻接表要初始化 表头
memset(h, -1, sizeof h)
- 初始化 距离数组 为一个大值, 源点的距离为 0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 也有可能是其它点
- 建立 st[] 存储每个点是否在队列中
算法步骤:
//---------------------------------------------------------------------------\\
Spfa O(n)~O(nm)
//只让当前点能到达的点入队
//如果一个点已经在队列里,便不重复入队
//如果一条边未被更新,那么它的终点不入队
//---------------------------------------------------------------------------\\
时间复杂度 $O(nm)$, $n$ 表示点数,$m$ 表示边数
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储每个点到1号点的最短距离
bool st[N]; // 存储每个点是否在队列中
// 求1号点到n号点的最短路距离,如果从1号点无法走到n号点则返回-1
int spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true;
while (q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if (!st[j]) // 如果队列中已存在j,则不需要将j重复插入
{
q.push(j);
st[j] = true;
}
}
}
}
return dist[n];
}
spfa判断图中是否存在负环
时间复杂度 $O(nm)$, $n$ 表示点数,$m$ 表示边数
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N], cnt[N]; // dist[x]存储1号点到x的最短距离,cnt[x]存储1到x的最短路中经过的点数
bool st[N]; // 存储每个点是否在队列中
// 如果存在负环,则返回true,否则返回false。
bool spfa()
{
// 不需要初始化dist数组
// 原理:如果某条最短路径上有n个点(除了自己),那么加上自己之后一共有n+1个点,由抽屉原理一定有两个点相同,所以存在环。
queue<int> q;
for (int i = 1; i <= n; i ++ )
{
q.push(i);
st[i] = true;
}
while (q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true; // 如果从1号点到x的最短路中包含至少n个点(不包括自己),则说明存在环
if (!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
floyd算法
时间复杂度是 $O(n^3)$, $n$ 表示点数
// 初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
朴素版prim算法
扔个图瞧瞧
前置准备:
-
邻接矩阵 或 邻接表
-
邻接表要初始化 表头
memset(h, -1, sizeof h)
- 邻接矩阵要初始化 存边的数组 (爆 long long 的话,要用双重循环更新)
memset(g, 0x3f, sizeof g)
for (int i = 0; i < n; i ++ ) g[i][i] = 0; // 自己到自己的距离为 0;
- 初始化 距离数组 为一个大值, 源点的距离为 0
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 也有可能是其它点
- 建立 st[] 存储每个点是否在生成树中
算法步骤:
//---------------------------------------------------------------------------\\
prim O(n^2+m)
//用一个数组标记节点是否属于 T
//每次从未被标记过的节点中选出 d 值最小的,把它标记(新加入 T), 同时扫描其所有的出边。
//更新另一端点的 d 值,最小生成树的权值就是 d[2]+...+d[n]
//---------------------------------------------------------------------------\\
时间复杂度是 $O(n^2+m)$, $n$ 表示点数,$m$ 表示边数
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist); //初始化距离数组为一个很大的数(10亿左右)
int res = 0;
for (int i = 0; i < n; i ++ ) //每次循环选出一个点加入到生成树
{
int t = -1;
for (int j = 1; j <= n; j ++ ) //每个节点一次判断
if (!st[j] && (t == -1 || dist[t] > dist[j]))
//如果没有在树中,且到树的距离最短,则选择该点
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];
//加入除起点外所有点到集合的权重,即最小生成树的树边权重之和。
st[t] = true; // 选择该点
for (int j = 1; j <= n; j ++ )
//更新生成树外的点到生成树的距离
dist[j] = min(dist[j], g[t][j]);
//从 t 到节点 i 的距离小于原来距离,则更新。
}
return res;
}
Kruskal算法
时间复杂度是 $O(mlogm)$, $n$ 表示点数,$m$ 表示边数
满足两个性质: 边权之和 最小且 生成树最大边权 最小…
前置准备:
- 结构体
struct Edge
{
int a, b, w;
}edges[M];
edges[i] = {a, b, w};
算法步骤:
//---------------------------------------------------------------------------\\
Kruskal O(mlogm)
//1. 建立并查集,每个点各自构成一个集合
//2. 把所有边按权值从小到大排序,依次扫描每条边(a, b, w)
//3. 若 a, b 属于同一集合,则忽略这条边,继续扫描下一条
//4. 否则,合并 a,b 所在的集合,并把 w 累加到答案中
//5. 所有边扫描完成后, 第四步中处理过的边就构成最小生成树
//---------------------------------------------------------------------------\\
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
染色法判别二分图
定理:一个图是二分图当且仅当图中不含有基数环
时间复杂度是 $O(n+m)$, $n$ 表示点数,$m$ 表示边数
int n; // n表示点数
int h[N], e[M], ne[M], idx; // 邻接表存储图
int color[N]; // 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色
bool dfs(int u, int c)
{
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (color[j] == -1)
{
if (!dfs(j, !c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
bool check()
{
memset(color, -1, sizeof color);
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (color[i] == -1)
if (!dfs(i, 0))
{
flag = false;
break;
}
return flag;
}
匈牙利算法
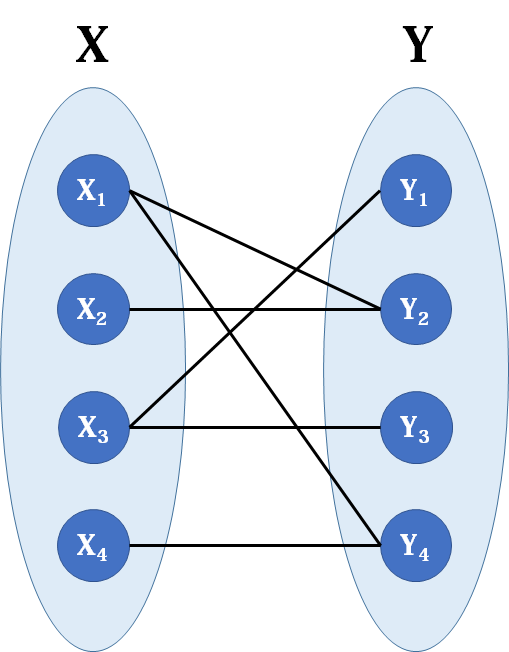
注意:只用给一个集合分配就可以了(第二个集合是被分配的)
时间复杂度是 $O(nm)$, $n$ 表示点数,$m$ 表示边数
int n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数
int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边
int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个
bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点
int res = 0;
for (int i = 1; i <= n1; i ++ ) // 易错!
{
memset(st, false, sizeof st);
if (find(i)) res ++ ;
}

%%%%%%%%%%%%%%%%%%%%