
1. 数据库引擎
1.1 INNODB AND MYISAM
| MYISAM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持(InnoDB 1.2.x版本开始支持全文检索) |
| 表空间的大小 | 较小 | 较大,2倍左右 |
常规使用操作:
- MYISAM:节约空间,速度较快
- INNODB:安全性高,事务的处理,多表多用户操作
在屋里控件的位置:
- 所有数据库文件都存在data目录下
- 本质还是文件的存储
MySQL引擎在物理文件上的区别
- InnoDB在数据库表中只有一个*.frm文件,以及上级目录下的ibdata1文件(MySQL8.0之前)
- MYISAM对应文件
- *.frm -表结构的定义文件
- *.MYD 数据文件(data)
- *.MYI 索引文件(index)
设置数据库表的字符集编码 ---- CHARSET=utf8mb4
不设置的话,会是MySQL默认的字符集编码~(不支持中文!)
MySQL的默认编码是Latin1,不支持中文
在my.ini中配置默认的编码
2. DQL查询数据
SELECT语法
SELECT [ALL | DISTINCT]
{* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[LEFT | RIGHT | INNER JOIN table_name2] -- 联合查询
[ON table1.column_name=table2.column_name] -- 联合查询等值判断,与JOIN一起使用
[WHERE column_name operator value] -- 指定结果需满足的条件
[GROUP BY column_name] -- 指定结果按照哪几个字段来分组
[HAVING aggregate_function(column_name) operator value] -- 过滤分组的记录必须满足的次要条件
[ORDER BY column_name,column_name ASC|DESC] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- 指定查询的记录从哪条至哪条
注意:[]代表可选,{}代表必选
2.1 DQL(Data Query Language)
- 所有的查询操作都用它 Select
- 简单的查询,复杂的查询它都能做
- 数据库中最核心的语言,最重要的语句
- 使用频率最高的语句
2.2 查询数据
SELECT * FROM table_name; -- 查询整张表
SELECT column_name,[...column_name]
FROM table_name; -- 查询指定数据
SELECT column_name AS xxx
FROM table_name AS xxx; -- 给表或者字段起别名
SELECT CONCAT(param, column_name) AS xxx
FROM table_name; -- 将字段与其他字符串等结合形成新的字符串
SELECT DISTINCT column_name
FROM table_name; -- 去掉查询数据重复的部分
SELECT @@auto_increment_increment; -- 查询自增步长
SELECT 表达式(1 + 1之类的) AS Result; -- 简单的计算
SELECT column_name + 1
FROM table_name; -- 实现增加减少
2.3 WHERE子句
作用:检索数据中符合条件的数据
- 逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | a and b a && b | 逻辑与,两个都为真,结果为真 |
| or | ||
| not ! | not a !a | 逻辑非,真为假,假为真 |
SELECT column_name, [...column_name]
FROM table_name
WHERE column_name >= xx AND(&&) column_name <= xx;
SELECT column_name, [...column_name]
FROM table_name
WHERE column_name BETWEEN xx AND xx;
SELECT column_name, [...column_name]
FROM table_name
WHERE column_name != xx;
SELECT column_name, [...column_name]
FROM table_name
WHERE NOT column_name = xx;
- 模糊查询(比较运算符)
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为NULL,结果为真 |
| IS NOT NULL | a is not null | 如果操作符不为null,结果为真 |
| BETWEEN | a between b and c | 若a在b和c之间,则结果为真 |
| LIKE | a like b | SQL匹配,如果a匹配b,则结果为真 |
| IN | a in b(a1,a2,a3…) | 假设a在a1,或者a2…其中的某一个值中,结果为真 |
% -- 通配符(0~任意个字符) _ -- 占位符(1个字符)
SELECT column_name,[...column_name]
FROM table_name
WHERE column_name LIKE x%; -- 查询以某个字开头的数据
SELECT column_name,[...column_name]
FROM table_name
WHERE column_name LIKE x_; -- 查询以某个字开头并且只有两个字的数据
IN
SELECT column_name
FROM table_name
WHERE column_name IN(xxx,xxx,xxx); -- 查询括号中的数据(相当于多个or),应为具体值,不能像LIKE这样;一个 IN 只能对一个字段进行范围比对,如果要指定更多字段,可以使用 AND 或 OR 逻辑运算符
SELECT column_name
FROM table_name
WHERE column_name = '' OR column_name IS NULL;
2.4 联表查询
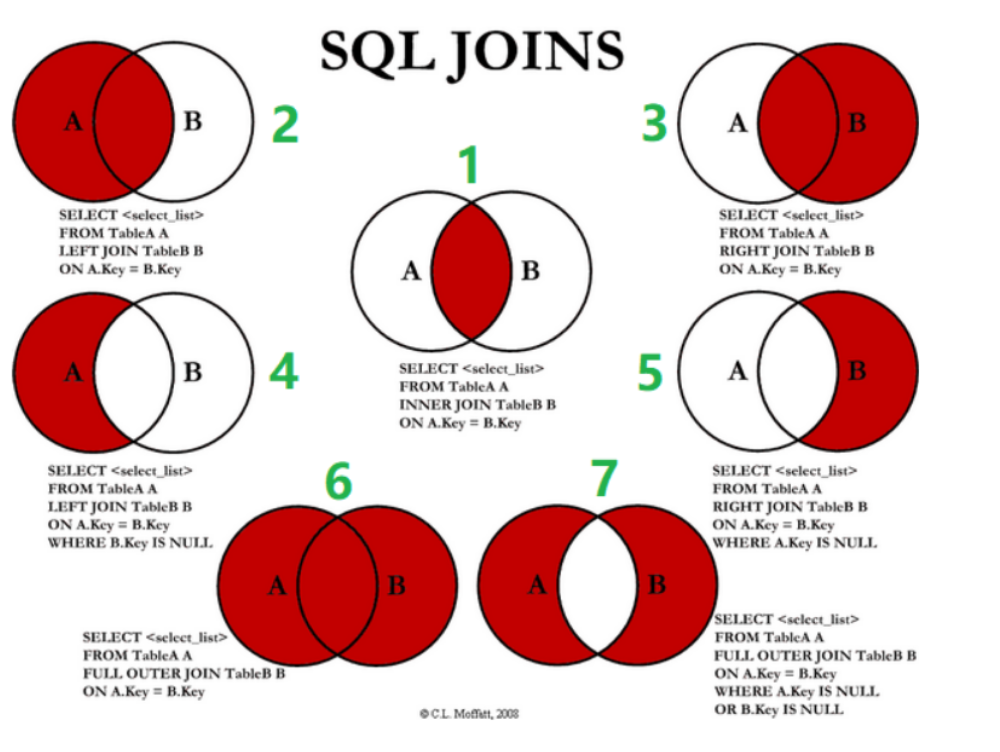
JOIN ON 连接查询 -- ON用于联表条件
WHERE 等值查询 -- WHERE用于过滤条件
-- INNER JOIN 匹配才返回
SELECT a.column_name,[...column_name]
FROM table_name AS a INNER
JOIN table1_name AS b
ON(相当于WHERE) a.column_name = b.column_name; -- 查询交集,相同的字段应该用别名区分,否则系统不能分辨
-- RIGHT JOIN 右表不管能不能匹配上条件,最终都会保留:能匹配,正确的保留; 若不能匹配,左表的字段都置NULL。
SELECT a.column_name,[...column_name]
FROM table_name AS a RIGHT
JOIN table1_name AS b
ON a.column_name = b.column_name;
-- LEFT JOIN 左表不管能不能匹配上条件,最终都会保留:能匹配,正确的保留; 若不能匹配,右表的字段都置NULL。
SELECT a.column_name,[...column_name]
FROM table_name AS a LEFT
JOIN table1_name AS b
ON a.column_name = b.column_name;
| 操作 | 描述 |
|---|---|
| INNER JOIN | 如果表中至少有一个匹配,就返回行(匹配才返回) |
| LEFT JOIN | 会从左表中返回所有的值,即使右表中没有匹配(不匹配为NULL) |
| RIGHT JOIN | 会从右表中返回所有的值,即使左表中没有匹配(不匹配为NULL) |
联表嵌套按照逻辑顺序依次进行
SELECT a.column_name,[...column_name]
FROM table_name AS a RIGHT
JOIN table1_name AS b ON a.column_name = b.column_name LEFT
JOIN table2_name AS b ON a.column_name = b.column_name;
2.5 自连接
自连接查询其实等同于连接查询,需要两张表,只不过它的左表(父表)和右表(子表)都是自己。做自连接查询的时候,是自己和自己连接,分别给父表和子表取两个不同的别名,然后附上连接条件。
简单来说就是在一个表中进行查询,这个表中的数据出现层级关系,我们可以通过他们的关系进行查询所需的数据。
SELECT a.column_name, b.column_name, [...column_name]
FROM table_name AS a, table_name AS b
WHERE a.column1_name = b.column2_name;
2.6 分页和排序
- 排序
-- ASC 升序 DESC 降序 ORDER BY要放在WHERE后
SELECT column_name, [...column_name]
FROM table_name
WHERE column1_name = xx
ORDER BY ASC(DESC);
-- 如果列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序
SELECT id, name, gender, score
FROM students
ORDER BY score
DESC, gender;
- 分页
-- LIMIT 后面的参数为限制显示几条数据 OFFSET后面的参数为起始索引(从0开始) LIMIT xx OFFSET xx 可以简写为 LIMIT xx(索引),xx(大小)
SELECT column_name, [...column_name]
FROM table_name
WHERE column1_name = xx
ORDER BY ASC(DESC)
LIMIT xx OFFSET xx(LIMIT xx, xx);
单独使用LIMIT进行分页查询在数据量很大的时候会变慢,应该进行优化
分页查询
2.7 子查询(嵌套查询)
嵌套查询是指在一个外层查询中包含有另一个内层查询。也就是说,一个查询的WHERE部分采用了另一个查询的得到的值作为查询条件,执行顺序是从内而外。
在一个SELECT 语句的WHERE 子句或HAVING 子句中嵌套另一个SELECT 语句的查询称为嵌套查询,又称子查询。子查询是SQL 语句的扩展,其语句形式如下:
SELECT <目标表达式1>[,…]
FROM <表或视图名1>
WHERE [表达式] (SELECT <目标表达式2>[,…]
FROM <表或视图名2>)
[GROUP BY <分组条件>
HAVING [<表达式>比较运算符] (SELECT <目标表达式2>[,…]
FROM <表或视图名2> )]
1、返回一个值的子查询
当子查询的返回值只有一个时,可以使用比较运算符如=、<、>、>=、<=、!=等将富查询和子查询连接起来。
2、返回一组值的子查询
如果子查询的返回值不止一个,而是一个集合时,则不能直接使用比较运算符,可以在比较运算符和子查询之间插入ANY、SOME或ALL。其中等值关系可以用IN操作符。
-- 子查询一般不使用排序
SELECT column_name, [...column_name]
FROM table_name
WHERE column_name = (
SELECT column_name, [...column_name]
FROM table_name
WHERE column_name = xxx
) ORDER BY column_name DESC;
2.8 分组和过滤
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name; -- 指定结果按照哪几个字段分组
HAVING column_name operator value -- 过滤分组的记录必须满足的次要条件
3. MySQL函数
3.1 常用函数
-- 数学运算
SELECT ABS(-8) --绝对值
SELECT CEILING(9.4) -- 向上取整
SELECT FLOOR(9.4) -- 向下取整
SELECT RAND() -- 返回一个 0~1之间的随机数
SELECT SIGN() -- 判断一个数的符号 0 -> 0 负数返回-1,正数返回1
-- 字符串函数
SELECT CHAR_LENGTH('SolitudeAlma') -- 字符串长度
SELECT CONCAT('I', 'LOVE', 'YOU') -- 拼接字符串
SELECT INSERT('I LOVE YOU', 1 , 1, 'He also') -- 查询替换
SELECT LOWER('I LOVE YOU') -- 转换成小写
SELECT UPPER('i love you') -- 转换成大写
SELECT INSTR('I LOVE YOU', 'Y') -- 返回目标字串第一次出现的索引
SELECT REPLACE('I LOVE YOU', 'YOU', 'ME') -- 替换指定字串
SELECT SUBSTR('I LOVE YOU', 3, 4) -- 返回指定的子字符串 param (string, offset, length)
SELECT REVERSE('你坚强伟大') -- 反转字符串
-- 时间和日期函数
SELECT CURRENT_DATE() -- 获取当前日期
SELECT CURDATE() -- 获取当前日期
SELECT NOW() -- 获取当前的时间
SELECT LOCALTIME() -- 本地时间
SELECT SYSDATE() -- 系统时间
SELECT YEAR(NOW) -- 其余类推
-- 系统
SELECT SYSTEM_USER()
SELECT USER()
SELECT VERSION()
3.2 聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| … | … |
-- COUNT
SELECT COUNT(column_name)
FROM table_name; -- 指定列,COUNT(字段)会忽略NULL值
SELECT COUNT(*)
FROM table_name; -- COUNT(*)不会忽略NULL值 本质 计算行数
SELECT COUNT(1)
FROM table_name; -- COUNT(1)不会忽略NULL值 本质 计算行数
-- SUM
SELECT SUM(column_name) AS xxx
FROM table_name;
-- AVG
SELECT AVG(column_name) AS xxx
FROM table_name;
-- MAX
SELECT MAX(column_name) AS xxx
FROM table_name;
-- MIN
SELECT MIN(column_name) AS xxx
FROM table_name;
3.3 数据库级别的MD5加密(扩展)
什么是MD5?
主要增强算法复杂度和不可逆性
MD5不可逆,它其实就是一个映射关系,相同的值的md5是一样的,也可能存在哈希碰撞,不同的值md5过后也是一样的,但概率较小
MD5网站的原理是他们有一张彩虹表,但是这个表不会很大,所以只有一些常见的字符串才能正确解密
INSERT INTO table_name (column_name[,column_name][,...])
VALUES(xx, xx, MD5(xx));
SELECT column_name
FROM table_name
WHERE column_name = MD5(xxx);
4. 事务
4.1 什么是事务
要么都成功,要么都失败
- SQL执行 A给B转账 A1000 —> 200 B200
- SQL执行 B收到A的钱 A800 —> B400
将一组SQL放在一个批次中去执行
事务原则性:ACID原则 原子性,一致性,隔离性,持久性 (脏读,幻读)
事务ACID理解
原子性(Atomicity)
要么都成功,要么都失败
一致性(Consistency)
事务前后的数据完整性要保持一致,1000
持久性(Durability)— 事务的提交
事务一旦提交则不可逆,被持久化到数据库中
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
隔离所导致的问题
- 脏读:指一个事务读取了另外一个事务未提交的数据。
- 不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
- 虚读(幻读):是指在一个事务内读取了别的事务插入的数据,导致前后读取不一致。
执行事务
-- MySQL是默认开启事务自动提交的
SET autocommit = 0; -- 关闭
SET autocommit = 1; -- 开启
-- 手动处理事务
SET autocommit = 0; -- 关闭自动提交
-- 事务开启
START TRANSACTION -- 标记事务的开始,从这个之后的sql都在同一个事务内
-- 提交:一旦被提交就持久化
COMMIT;
-- 回滚:回滚到原来的样子
ROLLBACK;
-- 事务结束
SET autocommit = 1; -- 开启自动提交
-- 了解
SAVEPOINT savepoint_name; -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT savepoint_name; -- 回滚到保存点
RELEASE SAVEPOINT savepoint_name; -- 删除保存点
5. 索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的本质:索引是数据结构。
5.1 索引分类
- 主键索引(PRIMARY KEY)
- 唯一的标识,主键不可重复,只有一个列作为主键
- 唯一索引(UNIQUE KEY)
- 避免重复的列,唯一索引可以重复,多个列都可以标识为唯一索引
- 常规索引(KEY/INDEX)
- 默认的,index/key关键字来设置
- 全文索引(FULLTEXT)
- 快速定位数据
基础语法
-- 索引的使用
-- 1、在创建表的时候给字段增加索引
-- 2、创建完毕后,增加索引
-- 显示所有的索引信息
SHOW INDEX FROM table_name;
-- 增加一个索引
ALTER TABLE table_name ADD index_name(column_name);
-- EXPLAIN 分析sql执行的状况
EXPLAIN SELECT * FROM table_name; -- 非全文索引
EXPLAIN SELECT * FROM table_name WHERE MATCH(column_name) AGAINST('xx'); -- 全文索引
5.2 测试索引
插入一百万条数据
--插入100w条数据
DELIMITER $$ -- 写函数之前必须写,标志
SET GLOBAL log_bin_trust_function_creators = TRUE; -- 设置之后才允许创建函数
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
-- 插入语句
INSERT INTO da(id) VALUES(i);
SET i = i + 1;
END WHILE;
RETURN i;
END;
SELECT mock_data() -- 执行此函数 生成一百万条数据
SELECT * FROM table_name WHERE column_name = '中间值,不要太靠前'; -- 时间: 0.47s
CREATE INDEX index_name ON table_name(column_name); -- 创建索引
SELECT * FROM table_name WHERE column_name = 99999; -- 时间: 0.001s
EXPLAIN SELECT * FROM table_name WHERE column_name = 99999;
EXPLAIN的结果:

索引在数据量大的时候作用很大
5.3 索引原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上
索引的数据结构
Hash类型的索引
Btree:InnoDB的默认数据结构
阅读:
https://blog.codinglabs.org/articles/theory-of-mysql-index.html https://blog.csdn.net/jiadajing267/article/details/81269067
6.权限管理和备份
6.1 用户管理
SQL命令操作
用户表:mysql.user
本质:对这张表进行增删改查
-- 创建用户
CREATE USER user_name IDENTIFIED BY 'password'; -- user_name是用户名,password是密码
-- 修改密码(修改当前用户的密码)
SET PASSWORD = PASSWORD('password');
-- 修改密码(指定用户)
SET PASSWORD FOR user_name = PASSWORD('password');
-- 重命名
RENAME USER pri_user_name TO now_user_name;
-- 用户授权
GRANT ALL PRIVILEGES ON *.* TO user_name; -- ALL PRIVILEGES所有权限(除了给别人授权,root才有) *.* 库.表
-- 查询权限
SHOW GRANTS FOR user_name -- 指定用户的权限
SHOW GRANTS FOR root@localhost
-- 撤销权限
REVOKE ALL PRIVILEGES ON *.* FROM user_name;
-- 删除用户
DROP USER user_name;
6.2 数据库备份
为什么要备份:
- 保证重要的数据不丢失
- 数据转移
MySQL数据库备份的方式
- 直接拷贝物理文件
- 在可视化工具中导出
- 使用命令行导出 –> mysqldump
-- h host_name u user_name p password database_name table_name > path
mysqldump -h localhost - u root -p password database_name table_name > path;
-- h host_name u user_name p password database_name table1_name table2_name table3_name > path
mysqldump -h localhost - u root -p password database_name table1_name table2_name table3_name> path;
-- h host_name u user_name p password database_name > path
mysqldump -h localhost - u root -p password database_name > path;
-- 导入
-- 登录的情况下,切换到指定的数据库
-- source file
source path;
mysql -u root -ppassword database_name < path;
7. 规范数据库设计
7.1 为什么需要设计
当数据库比较复杂的时候,我们就需要设计了
糟糕的数据库设计:
- 数据冗余,浪费空间
- 数据库插入和删除都会麻烦、异常
- 程序的性能差
良好的数据库设计:
- 节省内存空间
- 保证数据库的完整性
- 方便我们开发系统
软件开发中,关于数据库的设计
- 分析需求:分析业务和需要处理的数据库的需求
- 概要设计:设计关系图E-R图
设计数据库的步骤:(个人博客)
- 收集信息,分析需求
- 用户表(用户登录注销,用户的个人信息,写博客,创建分类(多人博客))
- 分类表(文章分类,谁创建的)
- 文章类(文章的信息)
- 友链表(友链信息)
- 自定义表(系统信息,某个关键的字,或者一些主字段) key:value
- 标识实体(把需求落实到每个字段)
- 标识实体之间的关系
- 写文章:user –> blog
- 创建分类:user –> category
- 关注:user –> user
- 友链:links
- 评论:user –> user –> blog
7.2 三大范式
为什么需要数据规范化?
- 信息重复
- 更新异常
- 插入异常
- 无法正常显示信息
- 删除异常
- 丢失有效的信息
三大范式
第一范式(1NF)
要求数据库表的每一列都是不可分割的原子数据项
原子性:保证每一列不可再分
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事情
第三范式(3NF)
前提:满足第二范式
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能简介相关。
规范性和性能问题
关联查询的表不能超过三个
- 考虑商业化的需求和目标,(成本、用户体验)数据库的性能更加重要
- 在规范性能的问题的时候,需要适当的考虑一下规范性
- 故意给某些表增加一些冗余的字段。(多表查询 –> 单表查询)
- 故意增加一些计算列(从大数据量降低为小数据量的查询:索引)
8. JDBC
8.1 JDBC
SUN公司为了简化开发人员的(对数据库的统一)操作,提供了一个(Java操作数据库的)规范,俗称JDBC
这些规范的实现由具体厂商去做
对于开发人员来说,我们只需要掌握JDBC接口的操作即可
java.sql
javax.sql
数据库驱动包
8.2 第一个JDBC程序
创建测试数据库
CREATE DATABASE `jdbc_study` CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
USE `jdbc_study`;
CREATE TABLE `users`(
`id` INT PRIMARY KEY,
`name` VARCHAR(40),
`password` VARCHAR(40),
`email` VARCHAR(60),
birthday DATE
);
INSERT INTO `users`(`id`,`NAME`,`PASSWORD`,`email`,`birthday`)
VALUES('1','zhangsan','123456','zs@sina.com','1980-12-04'),
('2','lisi','123456','lisi@sina.com','1981-12-04'),
('3','wangwu','123456','wangwu@sina.com','1979-12-04')
- 创建一个项目
-
导入数据库驱动
-
编写测试代码
package com.JDBC.MySQL;
import java.sql.*;
public class JDBC_TEST {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//1.加载驱动
Class.forName("com.mysql.cj.jdbc.Driver"); //固定写法,加载驱动 8.0的写法
//com.mysql.jdbc.Driver 8以下的写法
//2.用户信息和url
String url = "jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true";
String userName = "root";
String password = "";
//3.连接成功,数据库对象
Connection connection = DriverManager.getConnection(url, userName, password);
//4.执行SQL对象
Statement statement = connection.createStatement();
//5.执行SQL的对象去执行SQL,可能存在结果,查看返回结果
String sql = "SELECT * FROM users";
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
System.out.println("id:" + resultSet.getInt("id"));
System.out.println("name:" + resultSet.getString("name"));
System.out.println("password:" + resultSet.getString("password"));
System.out.println("email:" + resultSet.getString("email"));
System.out.println("birthday:" + resultSet.getString("birthday"));
}
//6.释放连接
resultSet.close();
statement.close();
connection.close();
}
}
步骤:
1. 加载驱动
2. 连接数据库Drive Manager
3. 获得执行sql的对象 Statement
4. 获得返回的结果集
5. 释放连接
DriverManager
// DriverManager.registerDriver(new com.mysql.jdbc.Driver());
Class.forName("com.mysql.cj.jdbc.Driver"); //固定写法,加载驱动 8.0的写法
Connection connection = DriverManager.getConnection(url, userName, password);
// connection 代表数据库
// 数据库设置自动提交
// 事务提交
// 事务回滚
connection.rollback();
connection.commit();
connection.setAutoCommit(true);
URL
String url = "jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true";
// mysql -- 3306
// 协议://hostname:port/database_name?param1¶m2...
//oralce -- 1521
// jdbc:oralce:thin:@localhost:1521:sid
Statement 执行SQL的对象 PrapareStatement 执行SQL的对象
String sql = "SELECT * FROM users";
statement.executeQuery();// 查询操作,返回ResultSet
statement.execute(); // 执行任何SQL
statement.executeUpdate(); // 更新、插入、删除。都是用这个,返回一个受影响的行数
ResultSet 查询的结果集:封装了所有的查询结果
获得指定的数据类型
// 未知类型
resultSet.getObject("id");
// 指定类型
resultSet.getString("id");
resultSet.getFloat("id");
resultSet.getDouble("id");
resultSet.getInt("id");
遍历(指针)
//至于为什么是行就自己百度
resultSet.next();//移动到下一个数据
resultSet.previous();//移动到上一行
resultSet.beforeFirst();//移动到第一个数据
resultSet.afterLast();//移动到最后一个数据
resultSet.absolute(row);//移动到指定行
释放资源
//释放资源
resultSet.close();
statement.close();
connection.close();
8.3 Statement对象
JDBC中的Statement对象用于向数据库发送SQL语句,想完成对数据库的增删改查,只需要通过这个对象向数据库发送增删改查语句即可。
Statement对象的executeUpdate方法,用于向数据库发送增删改的sql语句,executeUpdate执行完后,将会返回一个整数(即增删改语句导致了数据库几行数据发生了变化)。
Statement对象的executeQuery方法用于向数据库发送查询语句,executeQuery方法返回代表查询结果的ResultSet对象。
CRUD操作-create
使用executeUpdate(String sql)方法完成数据添加操作,示例操作:
Statement statement = connection.createStatement();
String sql = "INSERT INTO table_name(...)VALUES(...)";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("插入成功");
}
CRUD操作-delete
使用executeUpdate(String sql)方法完成数据删除操作,示例操作:
Statement statement = connection.createStatement();
String sql = "DELETE FROM table_name WHERE column_name = xx";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("删除成功");
}
CRUD操作-update
使用executeUpdate(String sql)方法完成数据修改操作,示例操作:
Statement statement = connection.createStatement();
String sql = "UPDATE table_name SET column_name = 'xx' WHERE column1_name = 'xx'";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("修改成功");
}
CRUD操作-read
使用executeQuery(String sql)方法完成数据查询操作,示例操作:
Statement statement = connection.createStatement();
String sql = "SELECT * FROM table_name WHERE column_name = xx";
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
//根据获取的列的数据类型,分别调用resultSet的相应方法映射到java对象中
}
代码实现
- 提取工具类
package com.JDBC.MySQL.utils;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JDBC_Utils {
private static String url = null;
private static String username = null;
private static String password = null;
static {
try {
InputStream inputStream = JDBC_Utils.class.getClassLoader().getResourceAsStream("db.properties");
Properties properties = new Properties();
properties.load(inputStream);
String driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
//驱动只需加载一次
Class.forName(driver);
} catch (Exception e) {
e.printStackTrace();
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, username, password);
}
//释放资源
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//db.properties 这个要放在src下,下面用到的也是,web项目不太一样
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true
username=root
password=
- 编写增删改
//增删改只需要修改SQL即可
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class InsertTest {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//获取数据库连接
statement = connection.createStatement();//获取SQL执行对象
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(4, 'SolitudeAlma', " +
"'123', '2333@qq.com', '2021-08-07')";
int i = statement.executeUpdate(sql);
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
- 查询
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class SelectTest {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try{
connection = JDBC_Utils.getConnection();
statement = connection.createStatement();
String sql = "SELECT * FROM users WHERE id = 1";
resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
String name = resultSet.getString("name");
System.out.println(name);
}
}catch(SQLException e) {
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
SQL注入
sql存在漏洞,会被攻击导致数据泄露 SQL可能会被拼接 OR
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class SQLInjection {
public static void main(String[] args) {
//login("zhangsan", "123456");
login("'or' 1=1", "'or' 1=1");
}
//登录
public static void login(String username, String password) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//获取数据库连接
statement = connection.createStatement();//获取SQL执行对象
// SELECT * FROM users WHERE `name` = '' or '1=1' AND `password` = '' or '1=1';
String sql = "SELECT * FROM users WHERE `name` = '" + username + "' AND `password` = '" + password + "'";
resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
String name = resultSet.getString("name");
String pwd = resultSet.getString("password");
System.out.println(name);
System.out.println(pwd);
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
8.4、PrepareStatement对象
PreparementStatement可以防止SQL注入,效率更高
- 增删改查
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.util.Date;
import java.sql.*;
public class InsertTest01 {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//获取数据库连接
//区别
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//手动给参数赋值
preparedStatement = connection.prepareStatement(sql);//预编译SQL,先写SQL,然后不执行
preparedStatement.setInt(1, 5);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//注意点: sql.Date 数据库
// util.Date Java new Date().getTime() 获取时间戳
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,preparedStatement,resultSet);
}
}
}
- SQL注入
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class SQLInjection01 {
public static void main(String[] args) {
//login("zhangsan", "123456");
login("'or' 1=1", "'or' 1=1");
}
//登录
public static void login(String username, String password) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//获取数据库连接
// PrepareStatement 防止SQL注入的本质,把传递进来的参数当作字符
// 假设其中存在转义字符,比如 ' 会被直接转义
String sql = "SELECT * FROM users WHERE `name` = ? AND `password` = ?";
preparedStatement = connection.prepareStatement(sql);//获取SQL执行对象
preparedStatement.setString(1, username);
preparedStatement.setString(2, password);
resultSet = preparedStatement.executeQuery();
while(resultSet.next()) {
String name = resultSet.getString("name");
String pwd = resultSet.getString("password");
System.out.println(name);
System.out.println(pwd);
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,preparedStatement,resultSet);
}
}
}
8.5 事务
代码实现
- 开启事务
connection.setAutoCommit(false);
- 一组业务执行完毕,提交事务
- 可以在catch语句中显示的定义回滚语句,但默认失败就会回滚
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class TransactionTest {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();
//关闭数据库的事务自动提交 自动会开启事务
connection.setAutoCommit(false);// 开启事务
String sql1 = "UPDATE account SET money = money - 100 WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.executeUpdate();
String sql2 = "UPDATE account SET money = money + 100 WHERE name = 'B'";
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
//业务完毕,提交事务
connection.commit();
System.out.println("Success");
} catch (SQLException e) {
//失败会自动回滚(默认)
try {
assert connection != null;
connection.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBC_Utils.release(connection, preparedStatement, resultSet);
}
}
}
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class TransactionTest01 {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();
//关闭数据库的事务自动提交 自动会开启事务
connection.setAutoCommit(false);// 开启事务
String sql1 = "UPDATE account SET money = money - 100 WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.executeUpdate();
String sql2 = "SELECT * FROM account WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql2);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
String name = resultSet.getString("name");
float money = resultSet.getFloat("money");
System.out.println(name + " " + money);
}
// 制造错误
int error = 1 / 0;
String sql3 = "UPDATE account SET money = money + 100 WHERE name = 'B'";
preparedStatement = connection.prepareStatement(sql3);
preparedStatement.executeUpdate();
//业务完毕,提交事务
connection.commit();
System.out.println("Success");
} catch (SQLException e) {
//失败会自动回滚(默认)
try {
assert connection != null;
connection.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBC_Utils.release(connection, preparedStatement, resultSet);
}
}
}
8.6 数据库连接池
数据库连接 – 执行完毕 – 释放
连接 –> 释放 非常浪费系统资源
池化技术:准备一些预先的资源,过来就连接预先准备好的
最小连接数:10
最大连接数:100 业务承载上限 超过排队等待
等待超时:100ms
编写连接池,实现一个接口 DataSource
开源数据源实现
DBCP
C3P0
Druid:阿里
使用了这些数据库连接池之后,我们在项目开发中就不需要编写连接数据库的代码了
DBCP
需要用到的jar包:
commons-dbcp-1.4、commons-pool-1.6
package com.JDBC.MySQL.utils;
import org.apache.commons.dbcp.BasicDataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JDBC_Utils_DBCP {
private static DataSource dataSource = null;
static {
try {
InputStream inputStream = JDBC_Utils.class.getClassLoader().getResourceAsStream("dbcpConfig.properties");
Properties properties = new Properties();
properties.load(inputStream);
//创建数据源 工厂模式 ---> 创建
dataSource = BasicDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();// 从数据源中获取连接
}
//释放资源
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//测试代码
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils_DBCP;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Date;
public class DBCP_TEST {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils_DBCP.getConnection();//获取数据库连接
//区别
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//手动给参数赋值
preparedStatement = connection.prepareStatement(sql);//预编译SQL,先写SQL,然后不执行
preparedStatement.setInt(1, 6);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//注意点: sql.Date 数据库
// util.Date Java new Date().getTime() 获取时间戳
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils_DBCP.release(connection,preparedStatement,resultSet);
}
}
}
// dbcpConfig.properties
#连接设置
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true
username=root
password=
#!-- 初始化连接 --
initialSize=10
#最大连接数量
maxActive=50
#!-- 最大空闲连接 --
maxIdle=20
#!-- 最小空闲连接 --
minIdle=5
#!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 --
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:【属性名=property;】
#注意:user 与 password 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=UTF8
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的只读(read-only)状态。
#如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix)
defaultReadOnly=
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=READ_UNCOMMITTED
C3P0
需要用到的jar包
c3p0-0.9.5.5、mchange-commons-java-0.2.20
//封装
package com.JDBC.MySQL.utils;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBC_Utils_C3P0 {
private static ComboPooledDataSource dataSource = null;
static {
try {
//代码配置
//dataSource = new ComboPooledDataSource();
//dataSource.setDriverClass();
//dataSource.setUser();
//dataSource.setPassword();
//dataSource.setJdbcUrl();
//dataSource.setMaxPoolSize();
//dataSource.setMinPoolSize();
//创建数据源 工厂模式 ---> 创建 不加参数使用默认配置
dataSource = new ComboPooledDataSource("MySQL");//配置文件写法
} catch (Exception e) {
e.printStackTrace();
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();// 从数据源中获取连接
}
//释放资源
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils_C3P0;
import com.JDBC.MySQL.utils.JDBC_Utils_DBCP;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Date;
public class C3P0_TEST {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils_C3P0.getConnection();//获取数据库连接
//区别
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//手动给参数赋值
preparedStatement = connection.prepareStatement(sql);//预编译SQL,先写SQL,然后不执行
preparedStatement.setInt(1, 7);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//注意点: sql.Date 数据库
// util.Date Java new Date().getTime() 获取时间戳
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils_C3P0.release(connection,preparedStatement,resultSet);
}
}
}
//文件名一定是c3p0-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!--
c3p0的缺省(默认)配置
如果在代码中ComboPooledDataSource ds=new ComboPooledDataSource();这样写就表示使用的是c3p0的缺省(默认)
-->
<default-config>
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=UTC</property>
<property name="user">root</property>
<property name="password">1209zyy,</property>
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">10</property>
<property name="minPoolSize">5</property>
<property name="maxPoolSize">20</property>
</default-config>
<!--
c3p0的命名配置,
如果在代码中“ComboPooledDataSource ds = new ComboPooledDataSource("MySQL");”这样写就表示使用的name是mysql的缺省(默认)
-->
<named-config name="MySQL">
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true</property>
<property name="user">root</property>
<property name="password">1209zyy,</property>
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">10</property>
<property name="minPoolSize">5</property>
<property name="maxPoolSize">20</property>
</named-config>
</c3p0-config>
结论
无论使用什么数据源,本质还是一样的,DataSource接口不会变,方法就不会变

这写玩意挺废手的吧
哈哈哈,我感觉还好,边看边写