
//函数定义用到 该数组 eg:void eg(vector<PII> &egg)//这时候形参vector可以改变实参(加了&)
vector//(变长数组),倍增的思想,支持比较运算(按字典序)
//定义::
vector<PII> p[N]; //定义了N个vector PII类型的数组 ,然后下面a可以是p[i].……
vector <int> a; //定义:一个vector数组a
vector <int> a(10); //定义:一个长度为10的vector数组a
vector <int> a(10,3); //定义:一个长度为10的vector数组a,并且所有元素都为3
常用函数::
a.size(); 返回元素个数
a.empty(); 返回是否是空(空返回ture 否则flase)
size 与empty每个容器都有,时间复杂度是O(1)
a.clear(); 清空
a.front(); 返回vector a的第一个数
a.back(); 返回vector a的最后一个数
a.push_back(); 向vector a的**最后**插入一个数//因为是往最后插入所以加了back
a.pop_back(); 把vector a的最后一个数删掉
a.begin(); vector a的第0个数
a.end(); vector a的最后一个的数的后面一个数
vector<int> a;
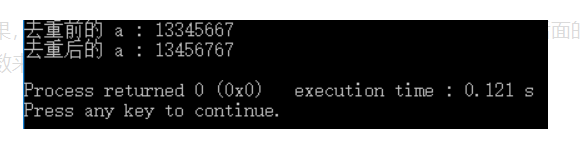
sort(a.begin(), a.end());
a.erase(unique(a.begin(), a.end()), a.end());
//经上述两个步骤后的a就是一个无重复值的有序vector
unique .有很多文章说的是,unique去重的过程是将重复的元素移到容器的后面去,实际上这种说法并不正确,应该是把不重复的元素移到前面来。 所以他确实是去重了,不过后面的那几个元素又重复了。详见图
如果用到普通数组也是可以的
其返回值是第一个重复元素的首地址 可以用它减去你放的第一个元素的下标来求新数组的长度
倍增的思想:
系统为某一程序分配空间是,所需时间,与空间大小无关,与申请次数有关
遍历方法
假设有个vector <int> a;
第一种:
for(int i = 0;i < a.size();i ++) cout<<a[i]<<" ";
第二种:(迭代器遍历)
for(vector <int>::iterator i = a.begin();i != a.end();i ++) cout<<*i<<" "; vector <int>::iterator可以写为auto
第三种:(范围遍历)
for(auto x : a) cout<<x<<" "; 此时x相当于a[i];
//排序
vector < int > vect;
//...
sort(vect.begin(), vect.end());
还可以根据字典序进行比较 444(有三3个4)>3333(有4个3)
pair(相当于一个结构体),支持比较运算,以first为第一关键字,以second为第二关键字(按字典序)
定义::(一个东西有两个关键字,把需要排序的那个关键字放在first里,不需要的放second里)
pair <类型,类型> 变量名; 两个类型可以不同
初始化方式:
假设有个pair <int,string> p;
第一种:
p = make_pair(10,"abc");
第二种:
p = {10,"abc");//直接等于号赋值
常用函数::
p.first(); //第一个元素//比如定义了一个pair数组使用sort的时候默认按其排序
p.second(); 第二个元素
//可以用vector<pair<int,int>> P存多对pair 且可以变长
string//(字符串)
//在字符串s后面加个字符/字符串 s+=“abc”;
常用函数::
substr(); //返回每一个子串 s.substr(a,b) //从下标a开始返回b个字符,省略b或者b大于a及后面的字符则返回从a开始的后面全部字符。
c_str(); //返回这个string对应的字符数组的头指针
size(); //返回字母个数
length(); //返回字母个数
empty(); //返回字符串是否为空
clear(); //把字符串清空
queue//(队列)
//定义::
queue <类型> //变量名;
//常用函数::
size(); 这个队列的长度
empty(); 返回这个队列是否为空
push(); 往队尾插入一个元素
front(); 返回队头元素
back(); 返回队尾元素
pop(); 把队头弹出
注意:队列没有clear函数!!!
那么清空就:
变量名 = queue <int> ();
priority_queue(优先队列,堆)
注意:默认是大根堆!!!
定义::
大根堆:priority_queue <类型> 变量名;
小根堆:priority_queue <类型,vecotr <类型>,greater <类型>> 变量名//最小的元素放堆顶
常用函数:
size(); 这个堆的长度
empty(); 返回这个堆是否为空
push();往堆里插入一个元素
top(); 返回堆顶元素
pop(); 弹出堆顶元素
注意:堆没有clear函数!!!
stack(栈)
常用函数:
size(); 这个栈的长度
empty(); 返回这个栈是否为空
push(); 向栈顶插入一个元素
top(); 返回栈顶元素
pop(); 弹出栈顶元素
deque(双端队列)
常用函数:
size(); 这个双端队列的长度
empty(); 返回这个双端队列是否为空
clear(); 清空这个双端队列
front(); 返回第一个元素
back(); 返回最后一个元素
push_back(); 向最后插入一个元素
pop_back(); 弹出最后一个元素
push_front(); 向队首插入一个元素
pop_front(); 弹出第一个元素
begin(); 双端队列的第0个数
end(); 双端队列的最后一个的数的后面一个数
set,map,multiset,multimap 基于平衡二叉树(红黑树),动态维护有序序列//map是键值对,set是一个数
//都是insert进去的
set/multiset//能查找元素出现了几次
注意:set不允许元素重复,如果有重复就会被忽略,但multiset允许!!!
常用函数:
size(); 返回元素个数
empty(); 返回set是否是空的
clear(); 清空
begin(); 第0个数,支持++或--,返回前驱和后继
end(); 最后一个的数的后面一个数,支持++或--,返回前驱和后继
insert(); 插入一个数
find(); 查找一个数
count(); //返回某一个数的个数//特性
erase();
(1)输入是一个数x,删除所有x O(k + log n)
(2)输入一个迭代器,删除这个迭代器
lower_bound(x); 返回大于等于x的最小的数的迭代器
upper_bound(x); 返回大于x的最小的数的迭代器
map/multimap
常用函数:
insert(); 插入一个数,插入的数是一个pair
erase();
(1)输入是pair
(2)输入一个迭代器,删除这个迭代器
find(); 查找一个数
lower_bound(x); 返回大于等于x的最小的数的迭代器
upper_bound(x); 返回大于x的最小的数的迭代器
unordered_set,unordered_map,unordered_muliset,unordered_multimap 基于哈希表
和上面类似,增删改查的时间复杂度是O(1)
不支持lower_bound()和upper_bound()
bitset 压位(水平到那再学)
定义:
bitset <个数> 变量名;
支持:
~,&,|,^
>>,<<
==,!=
[]
常用函数:
count(); 返回某一个数的个数
any(); 判断是否至少有一个1
none(); 判断是否全为0
set(); 把所有位置赋值为1
set(k,v); 将第k位变成v
reset(); //把所有位变成0
flip(); //把所有位取反,等价于~
flip(k); //把第k位取反

OrZ 可以 不记笔记了