
因倍质合(2)——神奇的TLE
咳咳,上一期我们讲解了一些算法,这一期讲解另一些算法(别打我鸭。
首先把表格copy过来……
| 自闭内容 | 自闭程度 | 代码长短 | 讲课时间 |
|---|---|---|---|
| 试除法判定质数 | 1星 | 中等 | 上节课 |
| 埃氏筛质数 | 2星 | 中等 | 上节课 |
| xxs筛质数 | 4星 | 较长 | 本节课 |
| 暴力求因(约)数 | 1星 | 较短 | 上节课 |
| 试除法求因(约)数 | 2星 | 中等 | 本节课 |
| 暴力算倍数 | 0.5星 | 极简 | 本节课 |
| 费马小定理求乘法逆元(补漏) | 4星 | 较长 | 上节课 |
| 分解质因数 | 2星 | 中等 | 本节课 |
| 质数的综合应用 | 4星 | 较长-极长 | 以后 |
| 约数的综合应用 | 5星 | 较长 | 以后 |
表格完成。
正式开始。
一、xxs,线性筛。
xxs,顾名思义,线性筛质数。
所谓线性筛,就是以极快的时间复杂度搞定。
那咋整哩?
线性筛(范围) 咋整:
# 你不是很牛吗?
整完了。
(乱入
好了来正经的。
一个数可能用多个质因子,比如:
$$
emm = {p_n} ^ {\alpha_1} \times {p_2} ^ {\alpha_2}\\\
if emm == 60:\\\
sixten = 0;\\\
sixten = 2 ^ 2 \times 3 \times 5;\\\
res = 0;\\\
res = (2 + 1) \times (1 + 1) \times (1 + 1)\\\
print(res);\\\
output: 12\\\
$$
所以说,一个数可能被多次无用的筛过去,这就导致时间复杂度有所提升。
所以我们就可以把这些无用功去掉,让每个数只被筛1遍。
这样就是$O(n)$的时间复杂度了。
那怎么搞呢?
我们指需要让n被它的最小质因子筛掉即可。
先看一下代码:
void xxs(int n)
{
for(int i = 2; i <= n; i ++)
{
if(!st[i]) primes[cnt ++] = i;
for(int j = 0; primes[j] <= n / i; j ++)
{
st[primes[j] * i] = true;
if(i % primes[j] == 0) break;
}
}
}
那我们如何找到最小质因子呢?
我们枚举一遍所有的质数,
如果
if(i % primes[j] == 0) break;
说明已经找到了最小质因子,不需要在浪费时间了,break掉。
然后再说一下剩下的部分。
分情况讨论:
- 如果可以的话,那么就把这个点筛掉
- 找到最小质因子直接break。
这就是$线性筛质数的做法$,因为一个数只会被筛一遍,所以时间复杂度为:$O(n)$。
Q:为什么非要用线性筛来做呢?埃氏筛法不香?
A:在N=$10^7$及以上时,埃氏筛比线性筛慢一倍。

所以,线性筛可谓是非常重要的一个算法。
接下来进行实战演练。
题目描述:
给定$n$个区间,区间最大右端点为$m$。
接下来$n$行,每行两个数:$l,r$。
分别表示查询的数的左右端点。
如果$l$或者$r$超出边界,则输出"bug!",
否则输出中间的质数个数。
注:本题来源于luogu P1865,有改动
思路
一般一看到区间问题,大家的第一反应就是前缀和和差分。
本题就是结合线性筛和前缀和的一道题。
首先,线性筛一遍1-m之间的质数,这次prime数组记录的是前缀和。
所以每次更新的时候更新前缀和即可。
代码大家自己写吧,下一篇争取有时间放出来。
试除法求约数
首先,上次我们说到,按暴力搞约数会TLE。

所以,根据因数成对出现,我们可以成对求出因数,最后排序。
这就是试除法求约数。
注意这里需要特判,如果求约数的$x$是以一个完全平方数,那么$\sqrt x$就会被记录两遍。
完整代码如下:
vector<int> g(int x)
{
vector<int> res;//vector香
for(int i = 1; i <= x / i; i ++)
{
if(x % i == 0)
{
res.push_back(i);
if(i != x / i) res.push_back(x / i);//这里的特判
}
}
sort(res.begin(), res.end());//最后排序
return res;
}
就这么简单。
暴力算倍数
有时我们想求出一个数的所有倍数时,就可以开一个vector记录。
然后暴力循环。
for(int i = x; i <= 999999999; i += x) cout << i << endl;
这是暴力做法。
当然魔鬼的同学们肯定想到了恶搞做法——bfs。(当然这里主要是为了让大家练习一下搜索
我们新建一个队列,每一次扩展时把当前扩展的数乘以2放入队列里(皮
主要思路——bfs做法
首先开队列和vector记录。
然后套一下宽搜的板子。
弹出队头。
拓展队头是我们要特判一下,如果这个点乘上一个固定的值超过了边界,就不能拓展。
或者被遍历过了,也不能拓展。
否则就可以拓展。
#include<bits/stdc++.h>
using namespace std;
const int N = 101;
int n;
bool st[N];
vector<int> res;
void bfs()
{
queue<int> q;
res.push_back(n);
q.push(n);
st[n] = true;
while(q.size())
{
int t = q.front();
q.pop();
if(t + n < N)
{
if(!st[t + n])
{
res.push_back(t + n);
q.push(t + n);
st[t + n] = true;
}
}
}
}
int main()
{
cin >> n;
bfs();
sort(res.begin(), res.end());//sort一遍
for(int i = 0; i < res.size(); i ++) cout << res[i] << ' ';
cout << endl;
return 0;
}
我们还可以用dfs来写一下。
每次递归处理即可。
#include<bits/stdc++.h>
using namespace std;
const int N = 101;
int n;
bool st[N];
vector<int> res;
void dfs(int u)
{
if(u >= N) return;
res.push_back(u);
st[u] = true;
for(int i = u + u; i < N; i += u)
{
if(!st[i])
{
dfs(i);
}
}
return;
}
int main()
{
cin >> n;
dfs(n);
sort(res.begin(), res.end());
for(int i = 0; i < res.size(); i ++) cout << res[i] << ' ';
cout << endl;
return 0;
}
对比一下3者的运行速度。
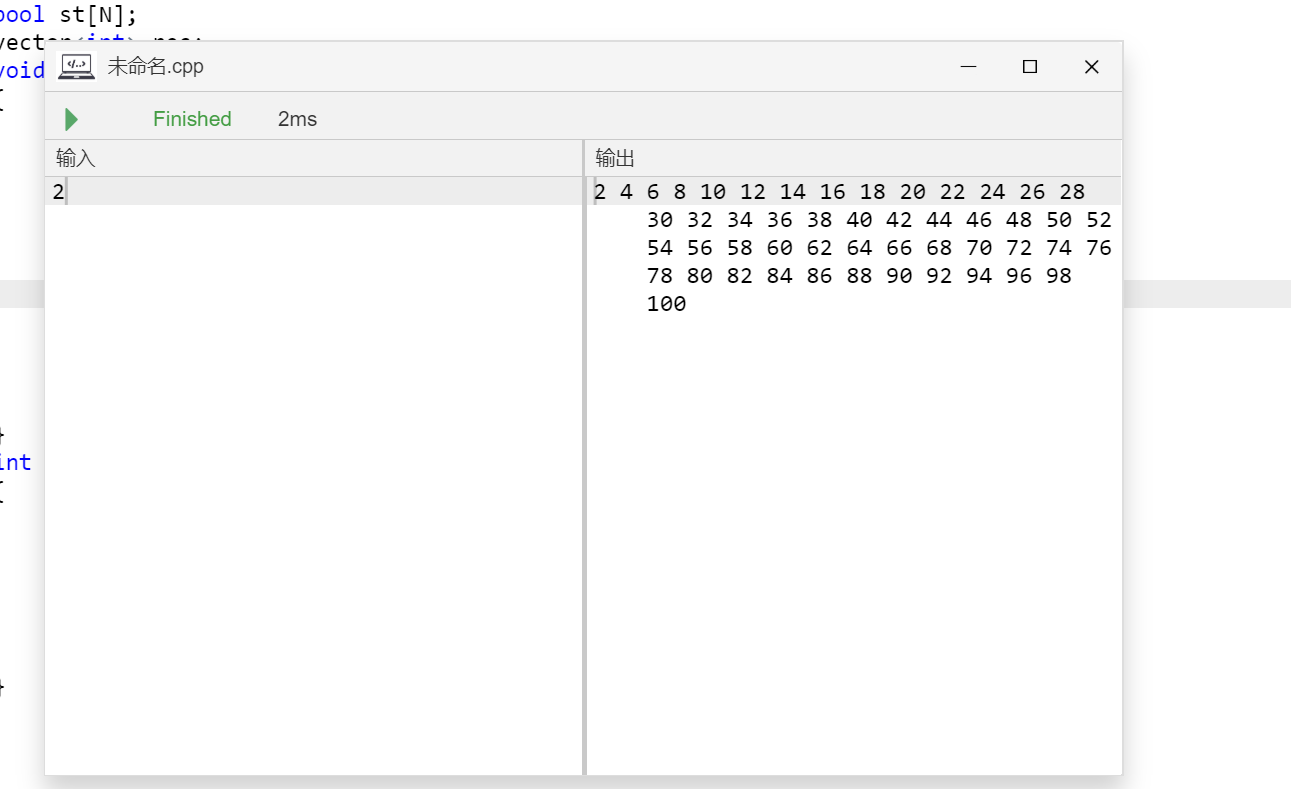
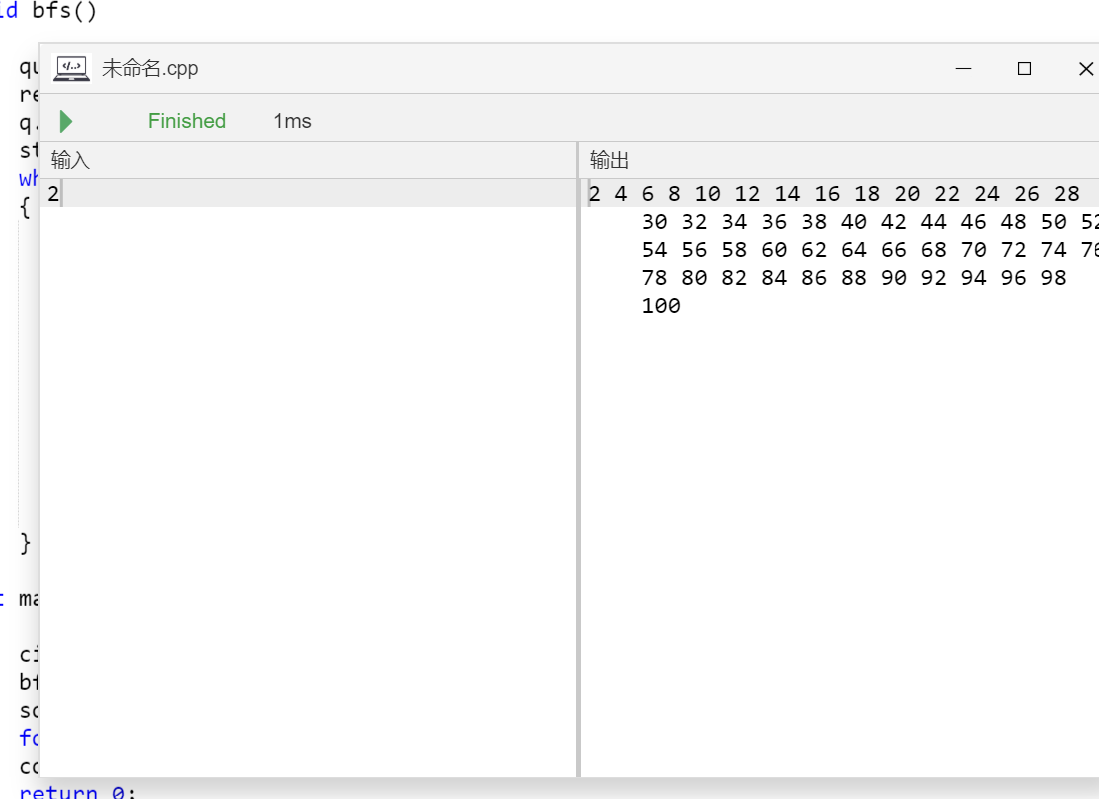
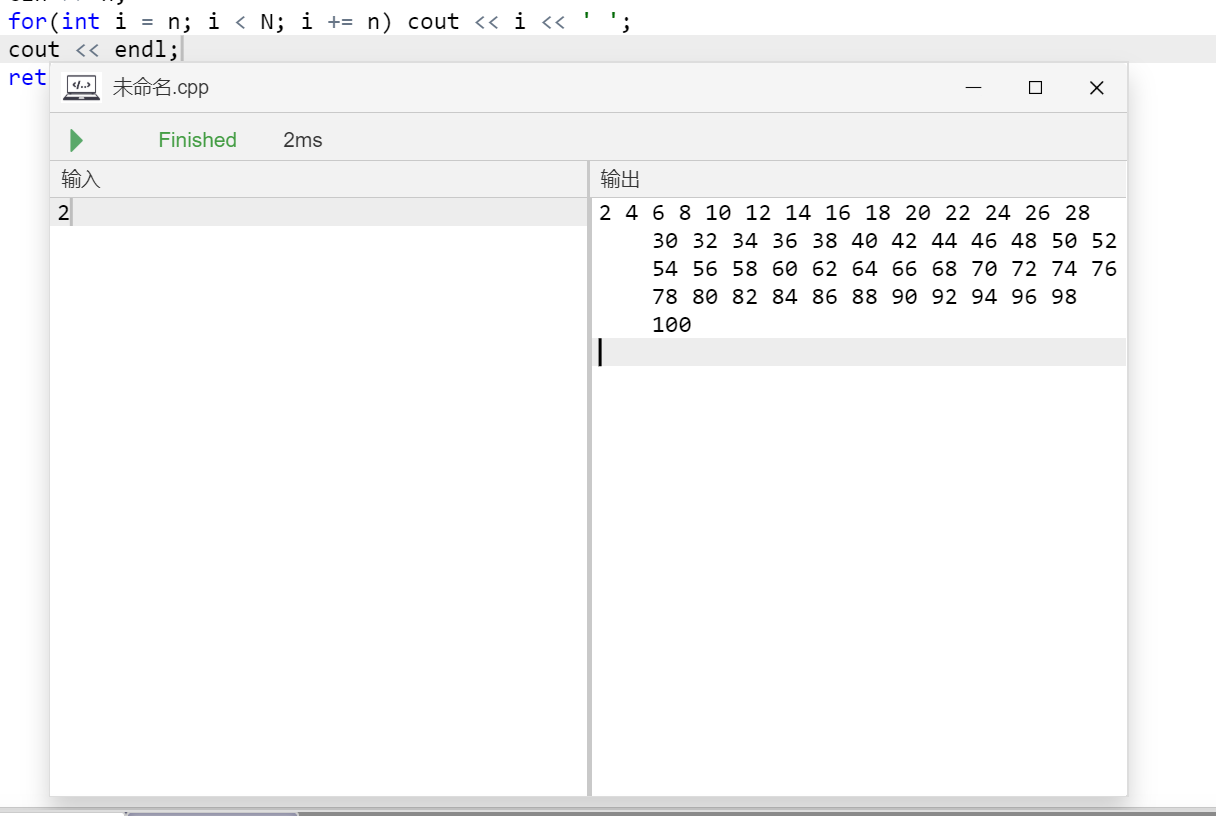
所以好像bfs快一点……
dfs没有做什么玄学剪枝,慢了1ms。
分解质因数。
上次列了一个表格,大家还记得吗?
$$
4 = 2 ^ 2
$$
$$
6 = 2 \times3
$$
$$
8 = 2 ^ 3
$$
$$
9 = 3 ^ 2
$$
$$
10 = 2 \times 5
$$
$$
12 = 2 ^ 2 \times 3
$$
$$
14 = 2 \times 7
$$
$$
15 = 3 \times 5
$$
$$
16 = 2 ^ 4
$$
$$
18 = 2 \times 3 ^ 2
$$
$$
20 = 2 ^ 2 \times 5
$$
$$
21 = 3 \times 7
$$
$$
22 = 2 \times 11
$$
$$
24 = 2 ^ 3 \times 3
$$
$$
25 = 5 ^ 2
$$
$$
26 = 2 \times 13
$$
$$
27 = 3 ^ 3
$$
$$
28 = 2 ^ 2 \times 7
$$
$$
30 = 2 \times 3 \times 5
$$
$$
32 = 2 ^ 5
$$
$$
33 = 3 \times 11
$$
$$
34 = 2 \times 17
$$
$$
35 = 5 \times 7
$$
$$
36 = 2 ^ 2 \times 3 ^ 3
$$
$$
38 = 2 \times 19
$$
$$
39 = 3 \times 13
$$
$$
40 = 2 ^ 3 \times 5
$$
$$
42 = 2 \times 3 \times 7
$$
$$
44 = 2 ^ 2 \times 11
$$
$$
45 = 5 \times 9
$$
$$
46 = 2 \times 23
$$
$$
48 = 2 ^ 4 \times 3
$$
$$
50 = 2 \times 5 ^ 2
$$
$$
51 = 3 \times 17
$$
$$
52 = 2 ^ 2 \times 13
$$
$$
54 = 2 \times 3 ^ 3
$$
$$
55 = 5 \times 11
$$
$$
56 = 2 ^ 3 \times 7
$$
$$
57 = 3 \times 19
$$
$$
58 = 2 \times 29
$$
$$
60 = 2 ^ 2 \times 3 \times 5
$$
$$
62 = 2 \times 31
$$
$$
63 = 3 ^ 2 \times 7
$$
$$
64 = 2 ^ 6
$$
$$
65 = 5 \times 13
$$
$$
66 = 2 \times 3 \times 11
$$
$$
68 = 2 ^ 2 \times 17
$$
$$
69 = 3 \times 23
$$
$$
70 = 2 \times 5 \times 7
$$
$$
72 = 2 ^ 3 \times 3 ^ 2
$$
$$
74 = 2 \times 27
$$
$$
75 = 3 \times 5 ^ 2
$$
$$
76 = 2 ^ 2 \times 19
$$
$$
77 = 7 \times 11
$$
$$
78 = 2 \times 3 \times 13
$$
$$
80 = 2 ^ 4 \times 5
$$
$$
81 = 3 ^ 4
$$
$$
82 = 2 \times 41
$$
$$
84 = 2 ^ 2 \times 3 \times 7
$$
$$
85 = 5 \times 13
$$
$$
86 = 2 \times 43
$$
$$
87 = 3 \times 29
$$
$$
88 = 2 ^ 3 \times 11
$$
$$
90 = 2 \times 3 ^ 2 \times 5
$$
$$
91 = 7 \times 13
$$
$$
92 = 2 ^ 2 \times 23
$$
$$
93 = 3 \times 31
$$
$$
94 = 2 \times 7 ^ 2
$$
$$
95 = 5 \times 19
$$
$$
96 =2 ^ 5 \times 3
$$
$$
98 = 2 \times 7 ^ 2
$$
$$
99 = 3 ^ 2 \times 11
$$
$$
100 = 2 ^ 2 \times 5 ^ 2
$$
我们先思考一下暴力解法。
如果使用暴力法,只需要从头到尾线性筛一遍($O(n)$),
然后再枚举每个约数,这样就很容易TLE。
所以我们可以用试除法,而不是先筛一遍质数再依次判断。
但是?这样会不会枚举到合数?!
答案是不会的。
代码如下:
void d(int x)
{
for(int i = 2; i <= x / i; i ++)
{
if(x % i == 0)
{
int s = 0;
while(x % i == 0 ) x /= i, s ++;
cout << i << ' ' << s << endl;
}
}
if(x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}

tql orz%%%
您tqL
总结的很好啊 orz
您tql
cht tql!!!
您tql
CHT YONG YUAN DI SHEN!!1
您tql
orz,三连
orz谢谢
《鸽王是怎么产生的》
orz
qwq,orz
## orz cht!
您tql
咕咕咕……