课程评估
- 团队作用和个人课堂测试
课程内容
1. Introduction to machine learning
1.1: Introduction to Machine Learning
机器学习的定义
Arthur Samuel在1959年将机器学习定义为:
机器学习是计算机科学的一个子领域,它使计算机能够在没有明确编程的情况下学习。
汤姆·米切尔在1998年提出了以下流行的定义:
如果一个计算机程序在T中的任务(由P衡量)的性能随着经验E的提高而提高,那么它就可以从经验E中学习某些类别的任务T和性能指标P。
- Representation learning is a form of machine learning concerned with learning features.
- 表征学习是一种与学习特征有关的机器学习形式。
- 深度学习是一种表征学习形式,与学习特征的层次结构有关(具有不同程度的抽象性)。
- Deep learning is a form of representational learning concerned with learning a hierarchy of features (of varying degrees of abstractness).
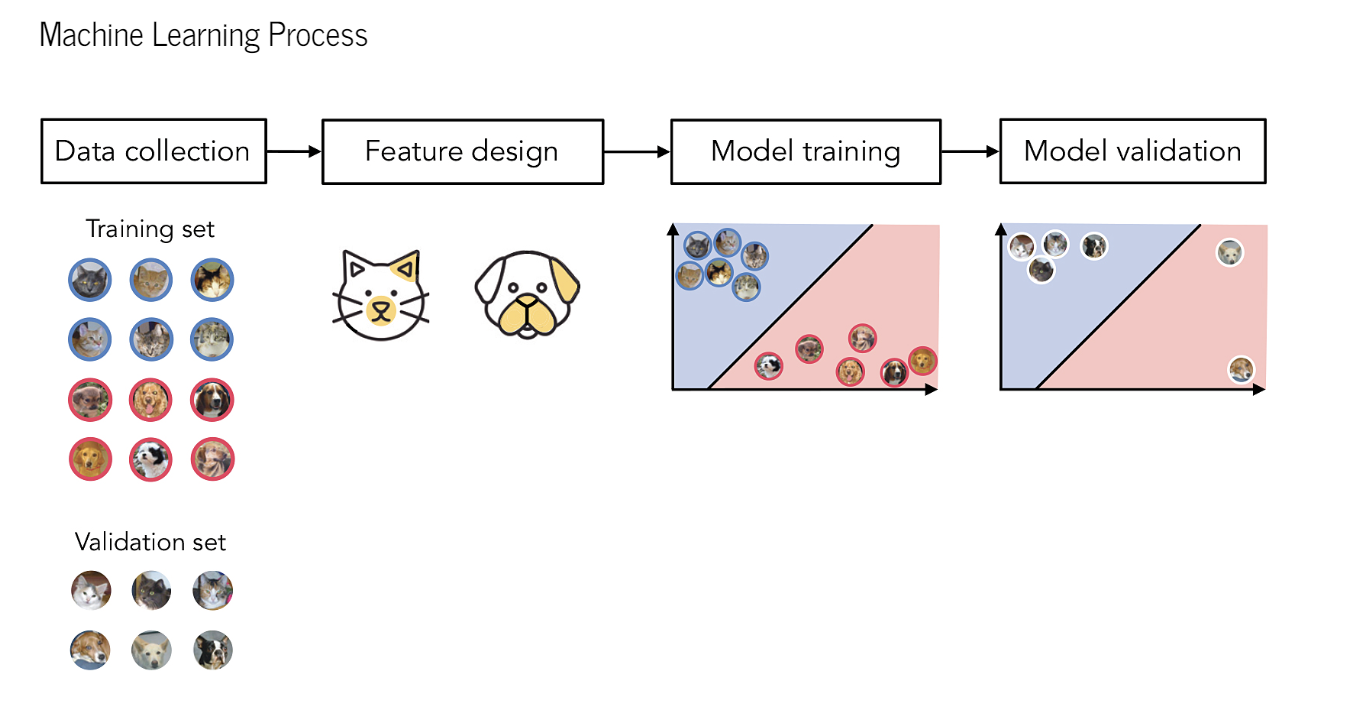
分类工作的步骤
- 数据收集
- 选择特征
- 模型训练
- 模型验证
数据集的表示
- 使用矩阵
- 每行包含不同的示例(样本),每列代表不同的特征
模型训练
有了训练数据的特征表示,区分猫和狗的机器学习问题就是一个几何问题:让计算机在我们精心设计的特征空间中找到一条将猫和狗分开的线或曲线。
如果我们要拟合一条直线
y=w0+w1x,那么我们必须找到其两个参数的最佳值:
- w1 梯度
- w0 纵轴上的截距
这是一个优化问题。优化是机器学习的关键。
机器学习的分类
- 监督学习算法
- 数据(观察、测量等)被标记为预定义的类别。就像“主管”给出类别并提供监督一样。
- 测试数据也被归类到这些类别中。
- 细分为分类或回归算法
- 无监督学习算法
- 数据的类别标签未知。
- 给定一组数据,任务是确定数据中是否存在类别或聚类
- 从数据中学习模式
- 半监督学习算法
- 利用标记和未标记数据进行训练
- 通常使用少量标记数据和大量未标记数据
-
强化学习算法
- 使用观察到的奖励来学习给定环境的最佳(或接近最佳)策略
- 必须通过尝试发现哪些操作会产生最大的奖励
-
监督学习与无监督学习
- 在我们的小问题中,我们从中学习的每个示例除了其特征外,还有一个标签(在本例中为猫/狗)。
- 如果我们从中学习的每个示例都有一个标签,并且任务是了解标签如何依赖于特征的值(以便我们可以预测新的、未见过的、未标记的示例的标签),那么学习就被称为监督学习。
- 当标签是离散类时,则任务称为分类;
- 当标签是连续的(实数)时,则任务称为回归;我们不会在本模块中介绍它
- 如果没有示例有标签(即我们只有特征值),那么任务通常是学习此数据集结构的有用属性。这称为无监督学习。无监督学习中最常见的任务是降维和聚类。
- 1.2: Classification vs clustering 分类和聚类
- 1.3: Introduction to Python and jupyter notebook
- 1.3: NumPy and Pandas Overview
- Labs: Exercises involving Scikit -learn
2.Classification (1)监督学习(分类)
- 2.1: Introduction to Classification
- 2.2: Classification algorithms
- Simple Linear Classifier简单线性
- Nearest Neigbour algorithm最邻近
- KNN
- Labs: Exercises involving Scikit -learn
3. Data pre-processing and feature selection
- 3.1: data preprocessing
- 3.2: feature selection
- Labs: Exercises involving Scikit -learn
4. Classification (2)
- 4.1: Classification algorithms (continue)
- 4.2: Classification performance assessment分类性能评估
- 4.3: Text Processing in Scikit-learn 文本处理
- Labs: Exercises involving Scikit -learn
5. Clustering (1)聚类
- 5.1: Introduction to clustering
- 5.2: Clustering algorithms
- Labs: Exercises involving Scikit -learn
6. Clustering (2)
- 6.1: Clustering algorithms (continue)
-
6.2: Clustering performance - assessment聚类性能评估
-
Labs: Exercises involving Scikit-learn
-
Submission of group assignment提交小组作业
7. Machine learning applications
- 7.1: ML applications
- 7.2: Trustworthy AI
- Class test
