
run.c
// https://github.com/karpathy/llama2.c
/* Inference for Llama-2 Transformer model in pure C */
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <time.h>
#include <math.h>
#include <string.h>
#include <fcntl.h>
#if defined _WIN32
#include "win.h"
#else
#include <unistd.h>
#include <sys/mman.h>
#endif
// ----------------------------------------------------------------------------
// Transformer model
typedef struct {
int dim; // transformer dimension
int hidden_dim; // for ffn layers
int n_layers; // number of layers
int n_heads; // number of query heads
int n_kv_heads; // number of key/value heads (can be < query heads because of multiquery)
int vocab_size; // vocabulary size, usually 256 (byte-level)
int seq_len; // max sequence length
} Config;
typedef struct {
// token embedding table
float* token_embedding_table; // (vocab_size, dim)
// weights for rmsnorms
float* rms_att_weight; // (layer, dim) rmsnorm weights
float* rms_ffn_weight; // (layer, dim)
// weights for matmuls. note dim == n_heads * head_size
float* wq; // (layer, dim, n_heads * head_size)
float* wk; // (layer, dim, n_kv_heads * head_size)
float* wv; // (layer, dim, n_kv_heads * head_size)
float* wo; // (layer, n_heads * head_size, dim)
// weights for ffn
float* w1; // (layer, hidden_dim, dim)
float* w2; // (layer, dim, hidden_dim)
float* w3; // (layer, hidden_dim, dim)
// final rmsnorm
float* rms_final_weight; // (dim,)
// (optional) classifier weights for the logits, on the last layer
float* wcls;
} TransformerWeights;
typedef struct {
// current wave of activations
float *x; // activation at current time stamp (dim,)
float *xb; // same, but inside a residual branch (dim,)
float *xb2; // an additional buffer just for convenience (dim,)
float *hb; // buffer for hidden dimension in the ffn (hidden_dim,)
float *hb2; // buffer for hidden dimension in the ffn (hidden_dim,)
float *q; // query (dim,)
float *k; // key (dim,)
float *v; // value (dim,)
float *att; // buffer for scores/attention values (n_heads, seq_len)
float *logits; // output logits
// kv cache
float* key_cache; // (layer, seq_len, dim)
float* value_cache; // (layer, seq_len, dim)
} RunState;
typedef struct {
Config config; // the hyperparameters of the architecture (the blueprint)
TransformerWeights weights; // the weights of the model
RunState state; // buffers for the "wave" of activations in the forward pass
// some more state needed to properly clean up the memory mapping (sigh)
int fd; // file descriptor for memory mapping
float* data; // memory mapped data pointer
ssize_t file_size; // size of the checkpoint file in bytes
} Transformer;
void malloc_run_state(RunState* s, Config* p) {
// we calloc instead of malloc to keep valgrind happy
int kv_dim = (p->dim * p->n_kv_heads) / p->n_heads;
s->x = calloc(p->dim, sizeof(float));
s->xb = calloc(p->dim, sizeof(float));
s->xb2 = calloc(p->dim, sizeof(float));
s->hb = calloc(p->hidden_dim, sizeof(float));
s->hb2 = calloc(p->hidden_dim, sizeof(float));
s->q = calloc(p->dim, sizeof(float));
s->key_cache = calloc(p->n_layers * p->seq_len * kv_dim, sizeof(float));
s->value_cache = calloc(p->n_layers * p->seq_len * kv_dim, sizeof(float));
s->att = calloc(p->n_heads * p->seq_len, sizeof(float));
s->logits = calloc(p->vocab_size, sizeof(float));
// ensure all mallocs went fine
if (!s->x || !s->xb || !s->xb2 || !s->hb || !s->hb2 || !s->q
|| !s->key_cache || !s->value_cache || !s->att || !s->logits) {
fprintf(stderr, "malloc failed!\n");
exit(EXIT_FAILURE);
}
}
void free_run_state(RunState* s) {
free(s->x);
free(s->xb);
free(s->xb2);
free(s->hb);
free(s->hb2);
free(s->q);
free(s->att);
free(s->logits);
free(s->key_cache);
free(s->value_cache);
}
void memory_map_weights(TransformerWeights *w, Config* p, float* ptr, int shared_weights) {
int head_size = p->dim / p->n_heads;
// make sure the multiplications below are done in 64bit to fit the parameter counts of 13B+ models
unsigned long long n_layers = p->n_layers;
w->token_embedding_table = ptr;
ptr += p->vocab_size * p->dim;
w->rms_att_weight = ptr;
ptr += n_layers * p->dim;
w->wq = ptr;
ptr += n_layers * p->dim * (p->n_heads * head_size);
w->wk = ptr;
ptr += n_layers * p->dim * (p->n_kv_heads * head_size);
w->wv = ptr;
ptr += n_layers * p->dim * (p->n_kv_heads * head_size);
w->wo = ptr;
ptr += n_layers * (p->n_heads * head_size) * p->dim;
w->rms_ffn_weight = ptr;
ptr += n_layers * p->dim;
w->w1 = ptr;
ptr += n_layers * p->dim * p->hidden_dim;
w->w2 = ptr;
ptr += n_layers * p->hidden_dim * p->dim;
w->w3 = ptr;
ptr += n_layers * p->dim * p->hidden_dim;
w->rms_final_weight = ptr;
ptr += p->dim;
ptr += p->seq_len * head_size / 2; // skip what used to be freq_cis_real (for RoPE)
ptr += p->seq_len * head_size / 2; // skip what used to be freq_cis_imag (for RoPE)
w->wcls = shared_weights ? w->token_embedding_table : ptr;
}
void read_checkpoint(char* checkpoint, Config* config, TransformerWeights* weights,
int* fd, float** data, ssize_t* file_size) {
FILE *file = fopen(checkpoint, "rb");
if (!file) { fprintf(stderr, "Couldn't open file %s\n", checkpoint); exit(EXIT_FAILURE); }
// read in the config header
if (fread(config, sizeof(Config), 1, file) != 1) { exit(EXIT_FAILURE); }
// negative vocab size is hacky way of signaling unshared weights. bit yikes.
int shared_weights = config->vocab_size > 0 ? 1 : 0;
config->vocab_size = abs(config->vocab_size);
// figure out the file size
fseek(file, 0, SEEK_END); // move file pointer to end of file
*file_size = ftell(file); // get the file size, in bytes
fclose(file);
// memory map the Transformer weights into the data pointer
*fd = open(checkpoint, O_RDONLY); // open in read only mode
if (*fd == -1) { fprintf(stderr, "open failed!\n"); exit(EXIT_FAILURE); }
*data = mmap(NULL, *file_size, PROT_READ, MAP_PRIVATE, *fd, 0);
if (*data == MAP_FAILED) { fprintf(stderr, "mmap failed!\n"); exit(EXIT_FAILURE); }
float* weights_ptr = *data + sizeof(Config)/sizeof(float);
memory_map_weights(weights, config, weights_ptr, shared_weights);
}
void build_transformer(Transformer *t, char* checkpoint_path) {
// read in the Config and the Weights from the checkpoint
read_checkpoint(checkpoint_path, &t->config, &t->weights, &t->fd, &t->data, &t->file_size);
// allocate the RunState buffers
malloc_run_state(&t->state, &t->config);
}
void free_transformer(Transformer* t) {
// close the memory mapping
if (t->data != MAP_FAILED) { munmap(t->data, t->file_size); }
if (t->fd != -1) { close(t->fd); }
// free the RunState buffers
free_run_state(&t->state);
}
// ----------------------------------------------------------------------------
// neural net blocks; the dynamics of the Transformer
void rmsnorm(float* o, float* x, float* weight, int size) {
// calculate sum of squares
float ss = 0.0f;
for (int j = 0; j < size; j++) {
ss += x[j] * x[j];
}
ss /= size;
ss += 1e-5f;
ss = 1.0f / sqrtf(ss);
// normalize and scale
for (int j = 0; j < size; j++) {
o[j] = weight[j] * (ss * x[j]);
}
}
void softmax(float* x, int size) {
// find max value (for numerical stability)
float max_val = x[0];
for (int i = 1; i < size; i++) {
if (x[i] > max_val) {
max_val = x[i];
}
}
// exp and sum
float sum = 0.0f;
for (int i = 0; i < size; i++) {
x[i] = expf(x[i] - max_val);
sum += x[i];
}
// normalize
for (int i = 0; i < size; i++) {
x[i] /= sum;
}
}
void matmul(float* xout, float* x, float* w, int n, int d) {
// W (d,n) @ x (n,) -> xout (d,)
// by far the most amount of time is spent inside this little function
int i;
#pragma omp parallel for private(i)
for (i = 0; i < d; i++) {
float val = 0.0f;
for (int j = 0; j < n; j++) {
val += w[i * n + j] * x[j];
}
xout[i] = val;
}
}
float* forward(Transformer* transformer, int token, int pos) {
// a few convenience variables
Config* p = &transformer->config;
TransformerWeights* w = &transformer->weights;
RunState* s = &transformer->state;
float *x = s->x;
int dim = p->dim;
int kv_dim = (p->dim * p->n_kv_heads) / p->n_heads;
int kv_mul = p->n_heads / p->n_kv_heads; // integer multiplier of the kv sharing in multiquery
int hidden_dim = p->hidden_dim;
int head_size = dim / p->n_heads;
// copy the token embedding into x
float* content_row = w->token_embedding_table + token * dim;
memcpy(x, content_row, dim*sizeof(*x));
// forward all the layers
for(unsigned long long l = 0; l < p->n_layers; l++) {
// attention rmsnorm
rmsnorm(s->xb, x, w->rms_att_weight + l*dim, dim);
// key and value point to the kv cache
int loff = l * p->seq_len * kv_dim; // kv cache layer offset for convenience
s->k = s->key_cache + loff + pos * kv_dim;
s->v = s->value_cache + loff + pos * kv_dim;
// qkv matmuls for this position
matmul(s->q, s->xb, w->wq + l*dim*dim, dim, dim);
matmul(s->k, s->xb, w->wk + l*dim*kv_dim, dim, kv_dim);
matmul(s->v, s->xb, w->wv + l*dim*kv_dim, dim, kv_dim);
// RoPE relative positional encoding: complex-valued rotate q and k in each head
for (int i = 0; i < dim; i+=2) {
int head_dim = i % head_size;
float freq = 1.0f / powf(10000.0f, head_dim / (float)head_size);
float val = pos * freq;
float fcr = cosf(val);
float fci = sinf(val);
int rotn = i < kv_dim ? 2 : 1; // how many vectors? 2 = q & k, 1 = q only
for (int v = 0; v < rotn; v++) {
float* vec = v == 0 ? s->q : s->k; // the vector to rotate (query or key)
float v0 = vec[i];
float v1 = vec[i+1];
vec[i] = v0 * fcr - v1 * fci;
vec[i+1] = v0 * fci + v1 * fcr;
}
}
// multihead attention. iterate over all heads
int h;
#pragma omp parallel for private(h)
for (h = 0; h < p->n_heads; h++) {
// get the query vector for this head
float* q = s->q + h * head_size;
// attention scores for this head
float* att = s->att + h * p->seq_len;
// iterate over all timesteps, including the current one
for (int t = 0; t <= pos; t++) {
// get the key vector for this head and at this timestep
float* k = s->key_cache + loff + t * kv_dim + (h / kv_mul) * head_size;
// calculate the attention score as the dot product of q and k
float score = 0.0f;
for (int i = 0; i < head_size; i++) {
score += q[i] * k[i];
}
score /= sqrtf(head_size);
// save the score to the attention buffer
att[t] = score;
}
// softmax the scores to get attention weights, from 0..pos inclusively
softmax(att, pos + 1);
// weighted sum of the values, store back into xb
float* xb = s->xb + h * head_size;
memset(xb, 0, head_size * sizeof(float));
for (int t = 0; t <= pos; t++) {
// get the value vector for this head and at this timestep
float* v = s->value_cache + loff + t * kv_dim + (h / kv_mul) * head_size;
// get the attention weight for this timestep
float a = att[t];
// accumulate the weighted value into xb
for (int i = 0; i < head_size; i++) {
xb[i] += a * v[i];
}
}
}
// final matmul to get the output of the attention
matmul(s->xb2, s->xb, w->wo + l*dim*dim, dim, dim);
// residual connection back into x
for (int i = 0; i < dim; i++) {
x[i] += s->xb2[i];
}
// ffn rmsnorm
rmsnorm(s->xb, x, w->rms_ffn_weight + l*dim, dim);
// Now for FFN in PyTorch we have: self.w2(F.silu(self.w1(x)) * self.w3(x))
// first calculate self.w1(x) and self.w3(x)
matmul(s->hb, s->xb, w->w1 + l*dim*hidden_dim, dim, hidden_dim);
matmul(s->hb2, s->xb, w->w3 + l*dim*hidden_dim, dim, hidden_dim);
// SwiGLU non-linearity
for (int i = 0; i < hidden_dim; i++) {
float val = s->hb[i];
// silu(x)=x*σ(x), where σ(x) is the logistic sigmoid
val *= (1.0f / (1.0f + expf(-val)));
// elementwise multiply with w3(x)
val *= s->hb2[i];
s->hb[i] = val;
}
// final matmul to get the output of the ffn
matmul(s->xb, s->hb, w->w2 + l*dim*hidden_dim, hidden_dim, dim);
// residual connection
for (int i = 0; i < dim; i++) {
x[i] += s->xb[i];
}
}
// final rmsnorm
rmsnorm(x, x, w->rms_final_weight, dim);
// classifier into logits
matmul(s->logits, x, w->wcls, p->dim, p->vocab_size);
return s->logits;
}
// ----------------------------------------------------------------------------
// The Byte Pair Encoding (BPE) Tokenizer that translates strings <-> tokens
typedef struct {
char *str;
int id;
} TokenIndex;
typedef struct {
char** vocab;
float* vocab_scores;
TokenIndex *sorted_vocab;
int vocab_size;
unsigned int max_token_length;
unsigned char byte_pieces[512]; // stores all single-byte strings
} Tokenizer;
int compare_tokens(const void *a, const void *b) {
return strcmp(((TokenIndex*)a)->str, ((TokenIndex*)b)->str);
}
void build_tokenizer(Tokenizer* t, char* tokenizer_path, int vocab_size) {
// i should have written the vocab_size into the tokenizer file... sigh
t->vocab_size = vocab_size;
// malloc space to hold the scores and the strings
t->vocab = (char**)malloc(vocab_size * sizeof(char*));
t->vocab_scores = (float*)malloc(vocab_size * sizeof(float));
t->sorted_vocab = NULL; // initialized lazily
for (int i = 0; i < 256; i++) {
t->byte_pieces[i * 2] = (unsigned char)i;
t->byte_pieces[i * 2 + 1] = '\0';
}
// read in the file
FILE *file = fopen(tokenizer_path, "rb");
if (!file) { fprintf(stderr, "couldn't load %s\n", tokenizer_path); exit(EXIT_FAILURE); }
if (fread(&t->max_token_length, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read\n"); exit(EXIT_FAILURE); }
int len;
for (int i = 0; i < vocab_size; i++) {
if (fread(t->vocab_scores + i, sizeof(float), 1, file) != 1) { fprintf(stderr, "failed read\n"); exit(EXIT_FAILURE);}
if (fread(&len, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read\n"); exit(EXIT_FAILURE); }
t->vocab[i] = (char *)malloc(len + 1);
if (fread(t->vocab[i], len, 1, file) != 1) { fprintf(stderr, "failed read\n"); exit(EXIT_FAILURE); }
t->vocab[i][len] = '\0'; // add the string terminating token
}
fclose(file);
}
void free_tokenizer(Tokenizer* t) {
for (int i = 0; i < t->vocab_size; i++) { free(t->vocab[i]); }
free(t->vocab);
free(t->vocab_scores);
free(t->sorted_vocab);
}
char* decode(Tokenizer* t, int prev_token, int token) {
char *piece = t->vocab[token];
// following BOS (1) token, sentencepiece decoder strips any leading whitespace (see PR #89)
if (prev_token == 1 && piece[0] == ' ') { piece++; }
// careful, some tokens designate raw bytes, and look like e.g. '<0x01>'
// parse this and convert and return the actual byte
unsigned char byte_val;
if (sscanf(piece, "<0x%02hhX>", &byte_val) == 1) {
piece = (char*)t->byte_pieces + byte_val * 2;
}
return piece;
}
void safe_printf(char *piece) {
// piece might be a raw byte token, and we only want to print printable chars or whitespace
// because some of the other bytes can be various control codes, backspace, etc.
if (piece == NULL) { return; }
if (piece[0] == '\0') { return; }
if (piece[1] == '\0') {
unsigned char byte_val = piece[0];
if (!(isprint(byte_val) || isspace(byte_val))) {
return; // bad byte, don't print it
}
}
printf("%s", piece);
}
int str_lookup(char *str, TokenIndex *sorted_vocab, int vocab_size) {
// efficiently find the perfect match for str in vocab, return its index or -1 if not found
TokenIndex tok = { .str = str }; // acts as the key to search for
TokenIndex *res = bsearch(&tok, sorted_vocab, vocab_size, sizeof(TokenIndex), compare_tokens);
return res != NULL ? res->id : -1;
}
void encode(Tokenizer* t, char *text, int8_t bos, int8_t eos, int *tokens, int *n_tokens) {
// encode the string text (input) into an upper-bound preallocated tokens[] array
// bos != 0 means prepend the BOS token (=1), eos != 0 means append the EOS token (=2)
if (text == NULL) { fprintf(stderr, "cannot encode NULL text\n"); exit(EXIT_FAILURE); }
if (t->sorted_vocab == NULL) {
// lazily malloc and sort the vocabulary
t->sorted_vocab = malloc(t->vocab_size * sizeof(TokenIndex));
for (int i = 0; i < t->vocab_size; i++) {
t->sorted_vocab[i].str = t->vocab[i];
t->sorted_vocab[i].id = i;
}
qsort(t->sorted_vocab, t->vocab_size, sizeof(TokenIndex), compare_tokens);
}
// create a temporary buffer that will store merge candidates of always two consecutive tokens
// *2 for concat, +1 for null terminator +2 for UTF8 (in case max_token_length is 1)
char* str_buffer = malloc((t->max_token_length*2 +1 +2) * sizeof(char));
size_t str_len = 0;
// start at 0 tokens
*n_tokens = 0;
// add optional BOS (=1) token, if desired
if (bos) tokens[(*n_tokens)++] = 1;
// add_dummy_prefix is true by default
// so prepend a dummy prefix token to the input string, but only if text != ""
// TODO: pretty sure this isn't correct in the general case but I don't have the
// energy to read more of the sentencepiece code to figure out what it's doing
if (text[0] != '\0') {
int dummy_prefix = str_lookup(" ", t->sorted_vocab, t->vocab_size);
tokens[(*n_tokens)++] = dummy_prefix;
}
// Okay UTF-8 time. This will get messy. Here is the reference from Wikipedia:
// Code point ↔ UTF-8 conversion
// First code point Last code point Byte 1 Byte 2 Byte 3 Byte 4
// U+0000 U+007F 0xxxxxxx
// U+0080 U+07FF 110xxxxx 10xxxxxx
// U+0800 U+FFFF 1110xxxx 10xxxxxx 10xxxxxx
// U+10000 U+10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
// process the raw (UTF-8) byte sequence of the input string
for (char *c = text; *c != '\0'; c++) {
// reset buffer if the current byte is ASCII or a leading byte
// 0xC0 is 11000000, so (*c & 0xC0) keeps the first 2 bits and zeros the rest
// 0x80 is 10000000
// in UTF-8, all continuation bytes start with "10" in first two bits
// so in English this is: "if this byte is not a continuation byte"
if ((*c & 0xC0) != 0x80) {
// this byte must be either a leading byte (11...) or an ASCII char (0x...)
// => reset our location, as we're starting a new UTF-8 codepoint
str_len = 0;
}
// append the current byte to the buffer
str_buffer[str_len++] = *c; // ++ is post-increment, incremented after this line
str_buffer[str_len] = '\0';
// while the next character is a continuation byte, continue appending
// but if there are too many of them, just stop to avoid overruning str_buffer size.
if ((*(c+1) & 0xC0) == 0x80 && str_len < 4) {
continue;
}
// ok c+1 is not a continuation byte, so we've read in a full codepoint
int id = str_lookup(str_buffer, t->sorted_vocab, t->vocab_size);
if (id != -1) {
// we found this codepoint in vocab, add it as a token
tokens[(*n_tokens)++] = id;
} else {
// byte_fallback encoding: just encode each byte as a token
// +3 is here because the first 3 vocab elements are <unk>, <s>, </s>
// so the individual bytes only start at index 3
for (int i=0; i < str_len; i++) {
tokens[(*n_tokens)++] = (unsigned char)str_buffer[i] + 3;
}
}
str_len = 0; // protect against a sequence of stray UTF8 continuation bytes
}
// merge the best consecutive pair each iteration, according the scores in vocab_scores
while (1) {
float best_score = -1e10;
int best_id = -1;
int best_idx = -1;
for (int i=0; i < (*n_tokens-1); i++) {
// check if we can merge the pair (tokens[i], tokens[i+1])
sprintf(str_buffer, "%s%s", t->vocab[tokens[i]], t->vocab[tokens[i+1]]);
int id = str_lookup(str_buffer, t->sorted_vocab, t->vocab_size);
if (id != -1 && t->vocab_scores[id] > best_score) {
// this merge pair exists in vocab! record its score and position
best_score = t->vocab_scores[id];
best_id = id;
best_idx = i;
}
}
if (best_idx == -1) {
break; // we couldn't find any more pairs to merge, so we're done
}
// merge the consecutive pair (best_idx, best_idx+1) into new token best_id
tokens[best_idx] = best_id;
// delete token at position best_idx+1, shift the entire sequence back 1
for (int i = best_idx+1; i < (*n_tokens-1); i++) {
tokens[i] = tokens[i+1];
}
(*n_tokens)--; // token length decreased
}
// add optional EOS (=2) token, if desired
if (eos) tokens[(*n_tokens)++] = 2;
free(str_buffer);
}
// ----------------------------------------------------------------------------
// The Sampler, which takes logits and returns a sampled token
// sampling can be done in a few ways: greedy argmax, sampling, top-p sampling
typedef struct {
float prob;
int index;
} ProbIndex; // struct used when sorting probabilities during top-p sampling
typedef struct {
int vocab_size;
ProbIndex* probindex; // buffer used in top-p sampling
float temperature;
float topp;
unsigned long long rng_state;
} Sampler;
int sample_argmax(float* probabilities, int n) {
// return the index that has the highest probability
int max_i = 0;
float max_p = probabilities[0];
for (int i = 1; i < n; i++) {
if (probabilities[i] > max_p) {
max_i = i;
max_p = probabilities[i];
}
}
return max_i;
}
int sample_mult(float* probabilities, int n, float coin) {
// sample index from probabilities (they must sum to 1!)
// coin is a random number in [0, 1), usually from random_f32()
float cdf = 0.0f;
for (int i = 0; i < n; i++) {
cdf += probabilities[i];
if (coin < cdf) {
return i;
}
}
return n - 1; // in case of rounding errors
}
int compare(const void* a, const void* b) {
ProbIndex* a_ = (ProbIndex*) a;
ProbIndex* b_ = (ProbIndex*) b;
if (a_->prob > b_->prob) return -1;
if (a_->prob < b_->prob) return 1;
return 0;
}
int sample_topp(float* probabilities, int n, float topp, ProbIndex* probindex, float coin) {
// top-p sampling (or "nucleus sampling") samples from the smallest set of
// tokens that exceed probability topp. This way we never sample tokens that
// have very low probabilities and are less likely to go "off the rails".
// coin is a random number in [0, 1), usually from random_f32()
int n0 = 0;
// quicksort indices in descending order of probabilities
// values smaller than (1 - topp) / (n - 1) cannot be part of the result
// so for efficiency we crop these out as candidates before sorting
const float cutoff = (1.0f - topp) / (n - 1);
for (int i = 0; i < n; i++) {
if (probabilities[i] >= cutoff) {
probindex[n0].index = i;
probindex[n0].prob = probabilities[i];
n0++;
}
}
qsort(probindex, n0, sizeof(ProbIndex), compare);
// truncate the list where cumulative probability exceeds topp
float cumulative_prob = 0.0f;
int last_idx = n0 - 1; // in case of rounding errors consider all elements
for (int i = 0; i < n0; i++) {
cumulative_prob += probindex[i].prob;
if (cumulative_prob > topp) {
last_idx = i;
break; // we've exceeded topp by including last_idx
}
}
// sample from the truncated list
float r = coin * cumulative_prob;
float cdf = 0.0f;
for (int i = 0; i <= last_idx; i++) {
cdf += probindex[i].prob;
if (r < cdf) {
return probindex[i].index;
}
}
return probindex[last_idx].index; // in case of rounding errors
}
void build_sampler(Sampler* sampler, int vocab_size, float temperature, float topp, unsigned long long rng_seed) {
sampler->vocab_size = vocab_size;
sampler->temperature = temperature;
sampler->topp = topp;
sampler->rng_state = rng_seed;
// buffer only used with nucleus sampling; may not need but it's ~small
sampler->probindex = malloc(sampler->vocab_size * sizeof(ProbIndex));
}
void free_sampler(Sampler* sampler) {
free(sampler->probindex);
}
unsigned int random_u32(unsigned long long *state) {
// xorshift rng: https://en.wikipedia.org/wiki/Xorshift#xorshift.2A
*state ^= *state >> 12;
*state ^= *state << 25;
*state ^= *state >> 27;
return (*state * 0x2545F4914F6CDD1Dull) >> 32;
}
float random_f32(unsigned long long *state) { // random float32 in [0,1)
return (random_u32(state) >> 8) / 16777216.0f;
}
int sample(Sampler* sampler, float* logits) {
// sample the token given the logits and some hyperparameters
int next;
if (sampler->temperature == 0.0f) {
// greedy argmax sampling: take the token with the highest probability
next = sample_argmax(logits, sampler->vocab_size);
} else {
// apply the temperature to the logits
for (int q=0; q<sampler->vocab_size; q++) { logits[q] /= sampler->temperature; }
// apply softmax to the logits to get the probabilities for next token
softmax(logits, sampler->vocab_size);
// flip a (float) coin (this is our source of entropy for sampling)
float coin = random_f32(&sampler->rng_state);
// we sample from this distribution to get the next token
if (sampler->topp <= 0 || sampler->topp >= 1) {
// simply sample from the predicted probability distribution
next = sample_mult(logits, sampler->vocab_size, coin);
} else {
// top-p (nucleus) sampling, clamping the least likely tokens to zero
next = sample_topp(logits, sampler->vocab_size, sampler->topp, sampler->probindex, coin);
}
}
return next;
}
// ----------------------------------------------------------------------------
// utilities: time
long time_in_ms() {
// return time in milliseconds, for benchmarking the model speed
struct timespec time;
clock_gettime(CLOCK_REALTIME, &time);
return time.tv_sec * 1000 + time.tv_nsec / 1000000;
}
// ----------------------------------------------------------------------------
// generation loop
void generate(Transformer *transformer, Tokenizer *tokenizer, Sampler *sampler, char *prompt, int steps) {
char *empty_prompt = "";
if (prompt == NULL) { prompt = empty_prompt; }
// encode the (string) prompt into tokens sequence
int num_prompt_tokens = 0;
int* prompt_tokens = (int*)malloc((strlen(prompt)+3) * sizeof(int)); // +3 for '\0', ?BOS, ?EOS
encode(tokenizer, prompt, 1, 0, prompt_tokens, &num_prompt_tokens);
if (num_prompt_tokens < 1) {
fprintf(stderr, "something is wrong, expected at least 1 prompt token\n");
exit(EXIT_FAILURE);
}
// start the main loop
long start = 0; // used to time our code, only initialized after first iteration
int next; // will store the next token in the sequence
int token = prompt_tokens[0]; // kick off with the first token in the prompt
int pos = 0; // position in the sequence
while (pos < steps) {
// forward the transformer to get logits for the next token
float* logits = forward(transformer, token, pos);
// advance the state machine
if (pos < num_prompt_tokens - 1) {
// if we are still processing the input prompt, force the next prompt token
next = prompt_tokens[pos + 1];
} else {
// otherwise sample the next token from the logits
next = sample(sampler, logits);
}
pos++;
// data-dependent terminating condition: the BOS (=1) token delimits sequences
if (next == 1) { break; }
// print the token as string, decode it with the Tokenizer object
char* piece = decode(tokenizer, token, next);
safe_printf(piece); // same as printf("%s", piece), but skips "unsafe" bytes
fflush(stdout);
token = next;
// init the timer here because the first iteration can be slower
if (start == 0) { start = time_in_ms(); }
}
printf("\n");
// report achieved tok/s (pos-1 because the timer starts after first iteration)
if (pos > 1) {
long end = time_in_ms();
fprintf(stderr, "achieved tok/s: %f\n", (pos-1) / (double)(end-start)*1000);
}
free(prompt_tokens);
}
void read_stdin(const char* guide, char* buffer, size_t bufsize) {
// read a line from stdin, up to but not including \n
printf("%s", guide);
if (fgets(buffer, bufsize, stdin) != NULL) {
size_t len = strlen(buffer);
if (len > 0 && buffer[len - 1] == '\n') {
buffer[len - 1] = '\0'; // strip newline
}
}
}
// ----------------------------------------------------------------------------
// chat loop
// I manually inspected the tokens for a few chat conversations compared to
// python reference and that seemed ok, but this was not thoroughly tested and
// is not safely implemented, it's more a proof of concept atm.
void chat(Transformer *transformer, Tokenizer *tokenizer, Sampler *sampler,
char *cli_user_prompt, char *cli_system_prompt, int steps) {
// buffers for reading the system prompt and user prompt from stdin
// you'll notice they are soomewhat haphazardly and unsafely set atm
char system_prompt[512];
char user_prompt[512];
char rendered_prompt[1152];
int num_prompt_tokens = 0;
int* prompt_tokens = (int*)malloc(1152 * sizeof(int));
int user_idx;
// start the main loop
int8_t user_turn = 1; // user starts
int next; // will store the next token in the sequence
int token; // stores the current token to feed into the transformer
int prev_token;
int pos = 0; // position in the sequence
while (pos < steps) {
// when it is the user's turn to contribute tokens to the dialog...
if (user_turn) {
// get the (optional) system prompt at position 0
if (pos == 0) {
// at position 0, the user can also contribute a system prompt
if (cli_system_prompt == NULL) {
// system prompt was not passed in, attempt to get it from stdin
read_stdin("Enter system prompt (optional): ", system_prompt, sizeof(system_prompt));
} else {
// system prompt was passed in, use it
strcpy(system_prompt, cli_system_prompt);
}
}
// get the user prompt
if (pos == 0 && cli_user_prompt != NULL) {
// user prompt for position 0 was passed in, use it
strcpy(user_prompt, cli_user_prompt);
} else {
// otherwise get user prompt from stdin
read_stdin("User: ", user_prompt, sizeof(user_prompt));
}
// render user/system prompts into the Llama 2 Chat schema
if (pos == 0 && system_prompt[0] != '\0') {
char system_template[] = "[INST] <<SYS>>\n%s\n<</SYS>>\n\n%s [/INST]";
sprintf(rendered_prompt, system_template, system_prompt, user_prompt);
} else {
char user_template[] = "[INST] %s [/INST]";
sprintf(rendered_prompt, user_template, user_prompt);
}
// encode the rendered prompt into tokens
encode(tokenizer, rendered_prompt, 1, 0, prompt_tokens, &num_prompt_tokens);
user_idx = 0; // reset the user index
user_turn = 0;
printf("Assistant: ");
}
// determine the token to pass into the transformer next
if (user_idx < num_prompt_tokens) {
// if we are still processing the input prompt, force the next prompt token
token = prompt_tokens[user_idx++];
} else {
// otherwise use the next token sampled from previous turn
token = next;
}
// EOS (=2) token ends the Assistant turn
if (token == 2) { user_turn = 1; }
// forward the transformer to get logits for the next token
float* logits = forward(transformer, token, pos);
next = sample(sampler, logits);
pos++;
if (user_idx >= num_prompt_tokens && next != 2) {
// the Assistant is responding, so print its output
char* piece = decode(tokenizer, token, next);
safe_printf(piece); // same as printf("%s", piece), but skips "unsafe" bytes
fflush(stdout);
}
if (next == 2) { printf("\n"); }
}
printf("\n");
free(prompt_tokens);
}
// ----------------------------------------------------------------------------
// CLI, include only if not testing
#ifndef TESTING
void error_usage() {
fprintf(stderr, "Usage: run <checkpoint> [options]\n");
fprintf(stderr, "Example: run model.bin -n 256 -i \"Once upon a time\"\n");
fprintf(stderr, "Options:\n");
fprintf(stderr, " -t <float> temperature in [0,inf], default 1.0\n");
fprintf(stderr, " -p <float> p value in top-p (nucleus) sampling in [0,1] default 0.9\n");
fprintf(stderr, " -s <int> random seed, default time(NULL)\n");
fprintf(stderr, " -n <int> number of steps to run for, default 256. 0 = max_seq_len\n");
fprintf(stderr, " -i <string> input prompt\n");
fprintf(stderr, " -z <string> optional path to custom tokenizer\n");
fprintf(stderr, " -m <string> mode: generate|chat, default: generate\n");
fprintf(stderr, " -y <string> (optional) system prompt in chat mode\n");
exit(EXIT_FAILURE);
}
int main(int argc, char *argv[]) {
// default parameters
char *checkpoint_path = NULL; // e.g. out/model.bin
char *tokenizer_path = "tokenizer.bin";
float temperature = 1.0f; // 0.0 = greedy deterministic. 1.0 = original. don't set higher
float topp = 0.9f; // top-p in nucleus sampling. 1.0 = off. 0.9 works well, but slower
int steps = 256; // number of steps to run for
char *prompt = NULL; // prompt string
unsigned long long rng_seed = 0; // seed rng with time by default
char *mode = "generate"; // generate|chat
char *system_prompt = NULL; // the (optional) system prompt to use in chat mode
// poor man's C argparse so we can override the defaults above from the command line
if (argc >= 2) { checkpoint_path = argv[1]; } else { error_usage(); }
for (int i = 2; i < argc; i+=2) {
// do some basic validation
if (i + 1 >= argc) { error_usage(); } // must have arg after flag
if (argv[i][0] != '-') { error_usage(); } // must start with dash
if (strlen(argv[i]) != 2) { error_usage(); } // must be -x (one dash, one letter)
// read in the args
if (argv[i][1] == 't') { temperature = atof(argv[i + 1]); }
else if (argv[i][1] == 'p') { topp = atof(argv[i + 1]); }
else if (argv[i][1] == 's') { rng_seed = atoi(argv[i + 1]); }
else if (argv[i][1] == 'n') { steps = atoi(argv[i + 1]); }
else if (argv[i][1] == 'i') { prompt = argv[i + 1]; }
else if (argv[i][1] == 'z') { tokenizer_path = argv[i + 1]; }
else if (argv[i][1] == 'm') { mode = argv[i + 1]; }
else if (argv[i][1] == 'y') { system_prompt = argv[i + 1]; }
else { error_usage(); }
}
// parameter validation/overrides
if (rng_seed <= 0) rng_seed = (unsigned int)time(NULL);
if (temperature < 0.0) temperature = 0.0;
if (topp < 0.0 || 1.0 < topp) topp = 0.9;
if (steps < 0) steps = 0;
// build the Transformer via the model .bin file
Transformer transformer;
build_transformer(&transformer, checkpoint_path);
if (steps == 0 || steps > transformer.config.seq_len) steps = transformer.config.seq_len; // override to ~max length
// build the Tokenizer via the tokenizer .bin file
Tokenizer tokenizer;
build_tokenizer(&tokenizer, tokenizer_path, transformer.config.vocab_size);
// build the Sampler
Sampler sampler;
build_sampler(&sampler, transformer.config.vocab_size, temperature, topp, rng_seed);
// run!
if (strcmp(mode, "generate") == 0) {
generate(&transformer, &tokenizer, &sampler, prompt, steps);
} else if (strcmp(mode, "chat") == 0) {
chat(&transformer, &tokenizer, &sampler, prompt, system_prompt, steps);
} else {
fprintf(stderr, "unknown mode: %s\n", mode);
error_usage();
}
// memory and file handles cleanup
free_sampler(&sampler);
free_tokenizer(&tokenizer);
free_transformer(&transformer);
return 0;
}
#endif
编译方法,推理一个15兆的故事模型:
git clone https://github.com/karpathy/llama2.c.git && cd llama2.c
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories15M.bin
make run
./run stories15M.bin
按一个开头开始推理
./run stories42M.bin -t 0.8 -n 256 -i "One day, Lily met a Shoggoth"
从Cauchy Thm 到 [未完待续]
Embarking on a journey from the foundational concepts of mathematics to the sophisticated realms of deep learning is both ambitious and enlightening. This exploration not only showcases the interconnectedness of mathematical principles but also their applicability in understanding and advancing artificial intelligence, specifically deep learning. Let’s outline this journey, connecting core concepts across different fields of mathematics and their relevance to deep learning.
From Cauchy’s Theorem to Complex Analysis
Cauchy’s Theorem is a fundamental result in complex analysis stating that, within certain conditions, a line integral of a complex function over a closed path is zero. This theorem not only underscores the importance of analyticity (a function being complex differentiable in a neighborhood of a point) but also paves the way for further results in complex analysis, such as the residue theorem, which has applications in solving real integrals and differential equations.
Complex Analysis itself is pivotal in understanding the behavior of nonlinear dynamical systems and in signal processing, both of which are foundational to creating and understanding algorithms in machine learning and deep learning, especially in the context of understanding the behavior of activation functions.
From Probability to Lebesgue Measure
Probability Theory is the mathematical backbone of statistical learning, which underpins machine learning and deep learning. Concepts such as random variables, expectation, and variance are crucial for understanding the behavior of algorithms and for the formulation of models like Bayesian networks or Gaussian processes.
Transitioning from probability to Lebesgue Measure introduces a more generalized concept of measuring sets, crucial for integrating functions over spaces that are not as nicely behaved as the real numbers. This is particularly relevant in understanding the foundations of probability theory in continuous spaces and is essential for the rigorous development of the theory behind random variables and their distributions, especially in the context of machine learning where we often deal with high-dimensional data.
From Linear Algebra to Linear Regression
Linear Algebra is the language of data representation and transformation in machine learning. Concepts such as vectors, matrices, eigenvalues, and eigenvectors are crucial for understanding data structures, optimizing algorithms, and even in the deep learning architectures themselves, where the manipulation of high-dimensional data is a routine task.
Linear Regression, a fundamental statistical technique for modeling relationships between variables, can be seen as a direct application of linear algebra. It involves finding the best linear approximation to model the relationship between a dependent variable and one or more independent variables. This concept extends into more complex models in machine learning, serving as a stepping stone towards understanding the intricacies of model fitting and optimization.
From Classification to Deep Learning
Classification tasks in machine learning are about predicting discrete labels for given inputs. Techniques such as logistic regression, decision trees, and support vector machines are grounded in the principles of statistics and optimization. Understanding these methods requires a grasp of concepts like decision boundaries, loss functions, and gradient descent.
Deep Learning extends these ideas into more complex architectures, such as neural networks, which are capable of learning representations from data in an incremental manner. This involves a deeper understanding of not just linear algebra and calculus, but also optimization techniques, regularization, and the nuances of different activation functions and architecture choices.
Leading into Deep Learning
Deep learning itself is a vast field, encompassing various architectures like Convolutional Neural Networks (CNNs) for image processing, Recurrent Neural Networks (RNNs) for sequential data, and Transformers for handling sequential data without the limitations of RNNs. Each of these architectures leverages the foundational mathematical concepts we’ve discussed, applied in innovative ways to learn from data.
Understanding deep learning from the ground up involves:
- Calculus for understanding how models learn (through backpropagation).
- Probability and Statistics for understanding data distributions and model uncertainty.
- Linear Algebra for data representation and manipulation.
- Optimization Theory for improving model performance.
Conclusion
This journey from basic mathematical principles to the forefront of artificial intelligence research illustrates the beauty and utility of mathematics in solving real-world problems through deep learning. Each step, from Cauchy’s theorem to complex analysis, from probability theory to Lebesgue measure, and from linear algebra through linear regression to deep learning, builds upon the previous, showcasing how fundamental concepts in mathematics are not just academic exercises but tools for understanding and creating the algorithms that power today’s AI technologies.
发展路径:
RNN -> Attention --> Seq2Seq (Encoder+Decoder) --> Seq2Seq+Attention --> Self-Attention --> Transformer
RNN:
具有隐状态的循环神经网络
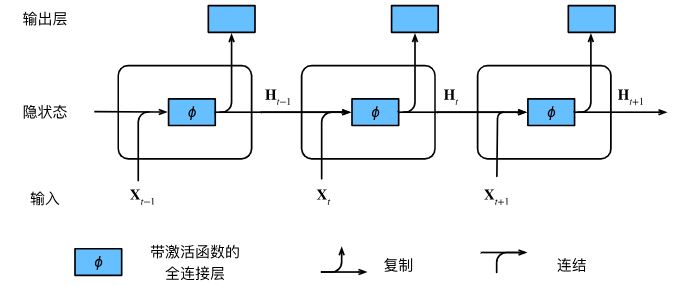
何谓RNN循环神经网络,核心即【循环】,输出作为输入继续进入模型,达成【记忆】般的效果,就像钢琴的延音踏板。
Def: 对隐状态使用循环计算的神经网络称为循环神经网络
对于连续性数据出奇的有效,比如时间序列,自然语言处理,语音识别
time series analysis, natural language processing, and speech recognition
适用于1对1,或者想同纬度有对应关系的
1. 一对多
这种 RNN 类型将一个输入传送到多个输出。它通过使用单个关键字生成句子来支持图片说明文字之类的语言应用程序。
2.多对多n对n
此模型使用多个输入来预测多个输出。例如,您可以使用 RNN 创建语言翻译器,该翻译器可以分析句子并正确用不同语言组织词句。
3. 多对一
多个输入映射到一个输出。这在情绪分析之类的应用程序中非常有用,在情绪分析中,此模型可以根据输入的评价预测客户的正面、负面和中立情绪。
对于n对m问题不太行。
变种:LSTM,由于自循环结构,rnn只对最近的文本相关性最强,记忆比较短,所以lstm提出来尝试解决短时记忆过短问题
Tom is a cat。 Tom’s favorite food is fish。使用 RNN 时,模型无法记住“Tom is a cat”。在预测最后一个词时,可能会产生各种各样的食物。LSTM 网络在隐藏层添加了一个名为单元的特殊内存块。每个单元都由输入门、输出门和遗忘门控制,使层能够记住有用的信息。例如,单元会记住 Tom 和 cat 这两个词,从而使模型能够预测 fish 这个词。 (ref:aws)
门控循环单元(GRU)是支持选择性内存保留的 RNN
