

由于程序的转移概率不会很低,数据分布也比较离散,单纯依靠双端口RAM和多体交叉编址提高主存系统的效率是有限的,CPU和磁盘读写速度的矛盾依旧存在。高速缓冲存储器(Cache)拥有比主存更快的存储速度,在主存和CPU之间设置Cache可以显著提高存储系统的效率。
为什么 Cache 可以提高存储系统的效率?
程序访问局部性原理
程序访问局部性原理包括时间局部性和空间局部性。
- 时间局部性是指最近未来要用到的信息,很可能是现在正在使用的信息。
- 空间局部性是指指最近未来要用到的信息,很可能与现在使用的信息在空间上是连续的。
高速缓冲技术就是利用局部性原理,把正在使用的部分数据存放在一个高速的小容量Cache中,使得CPU的大部分操作都是针对Cache进行,从而达到提高数据读写效率的目的。
看看一下两段代码
程序A
int sum(int a[m][n]) {
int res = 0;
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
res += a[i][j];
}
}
return res;
}
程序B
int sum(int a[m][n]) {
int res = 0;
for(int j = 0; j < n; j++) {
for(int i = 0; j < m; i++) {
res += a[i][j];
}
}
return res;
}
数组在计算机中是这样存放的
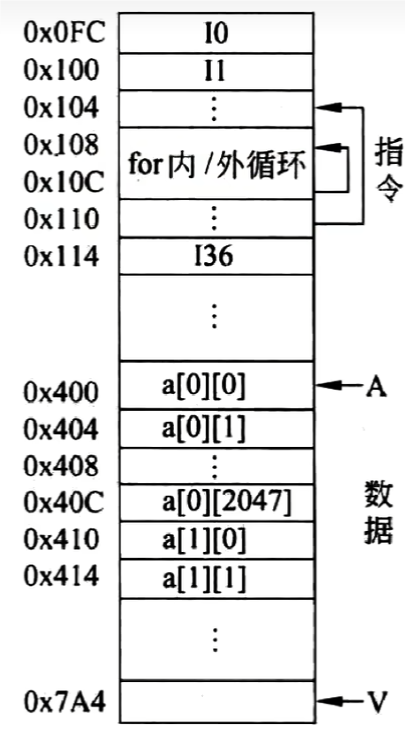
程序A 对于数组的访问顺序与存放顺序一直,对比程序B来说,局部性较好。
这也是为什么有些时候写 dp 或者一些循环暴力的时候,循环的顺序不一样,程序跑出结果来的时间也相差较大的原因。因为程序B的局部性较差,在执行过程中可能会发生更多的Cache缺失从而需要CPU更多的去访问主存,时间开销也就更大。
Cache 的基本工作原理
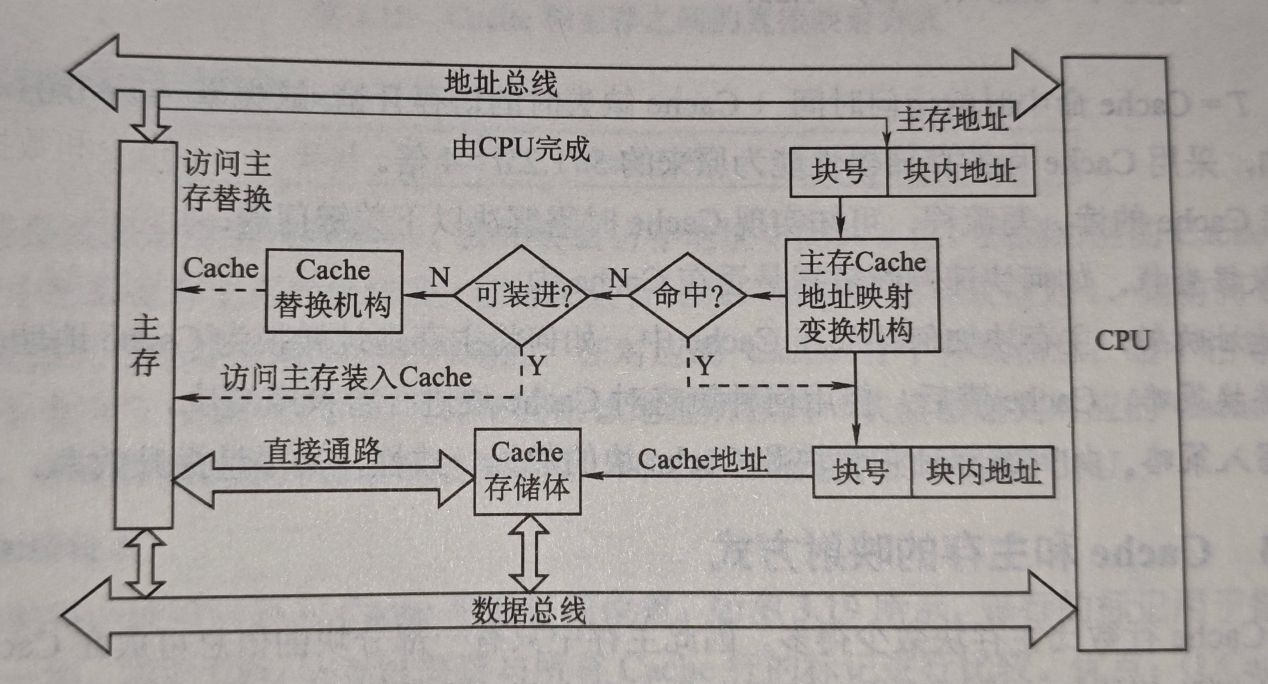
Cache和主存之间以块作为数据交换的单位,Cache块也会被叫做Cache行,块由若干字节组成,块的长度称为块长。
当CPU发出访问请求,会先根据访问地址,经过主存地址映射得到Cache地址,如果命中,会直接对Cache进行操作,如果没有命中,则需要去访问主存,并把这一次访问的块放入Cache中,如果Cache已满,就需要根据Cache替换策略选中一块换出。对于写请求,可能会出现Cache写了主存没有写,造成数据不一致的问题,所以针对写请求,会有相应的Cache写策略进行处理。Cache替换策略和写策略会在后续进行介绍。
Cache 和主存的映射方式
上文说到,CPU发出访问请求需要由地址映射机构将主存地址映射成Cache地址,接下来介绍几种映射方式
全相联映射
地址结构为: 标记 | 块内地址
主存中块可以存放在Cache中的任何位置,每行的标记用于指出来自与主存的那一块,CPU在访问时需要对标记进行比较。
优点:
- Cache块的冲突率较低,只要由空闲块就不会发生冲突。
- 空间利用率高。
- 命中率高。
缺点:
- 标记的比较速度较慢。
- 实现成本较高,一般是使用按内容寻址的相联存储器。
直接映射
地址结构为:标记 | Cache 行号 | 块内地址
直接映射的可以定义为
$$
Cache行号=主存块号\quad mod \quad Cache总行数
$$
在直接映射中主存的每一块在Cache中的存放位置都是唯一的,若产生冲突,对应的块将无条件的被换出去,即使Cache未满,这种映射方式冲突率最高,空间利用率最低,不够灵活,胜在实现简单。
组相联映射
地址结构为:标记 | 组号 | 块内地址
$$
组号=主存块号\quad mod \quad Cache总组数
$$
组相联映射结合前面两种映射方式,将Cache分成了若干大小相等的组,组之间采用直接映射,组内采用全相联映射方式,当组的大小等于1时,就会变为全相联映射。选定合适的组大小,可以使得组相联映射的成本接近直接映射,同时性能上仍然接近全相联映射。
Cache 替换算法
以下讨论都是在全相联映射或者组相联映射的情况下,直接映射不命中的话因为块位置固定,不用考虑替换策略而是直接换出。
前面有提到,当Cache中或者Cache组中空间被占满,需要采用替换算法替换Cache行。以下举出几种常见的替换算法
随机替换(Random)
随机选择Cache行进行换出,实现较为简单,但未依照局部性原理,命中率较低
先进先出(FIFO)
选择最早进入的Cache行调出,实现较为简单,但也未依照局部性原理,最早进入的也可能时最经常使用的
近期最少使用(LRU)
选择近期内长久为访问过的Cache进行替换,需要在Cache行中设置一个计数器(LRU替换位),记录主存块的使用情况,命中时命中的计数器清0,其余加一。以上是书中讲的,关于LRU的实现,在软件层面一般是使用Hash+双向链表。
以下是 GO和CPP 的实现
GO 版本
// Cache is a LRU cache. It is not safe for concurrent access.
type Cache struct {
maxBytes int64
nbytes int64
ll *list.List
cache map[string]*list.Element
// optional and executed when an entry is purged.
OnEvicted func(key string, value Value)
}
type entry struct {
key string
value Value
}
// Value use Len to count how many bytes it takes
type Value interface {
Len() int
}
// New is the Constructor of Cache
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}
// Get look ups a key's value
func (c *Cache) Get(key string) (value Value, ok bool) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
kv := ele.Value.(*entry)
return kv.value, true
}
return
}
// RemoveOldest removes the oldest item
func (c *Cache) RemoveOldest() {
ele := c.ll.Back()
if ele != nil {
c.ll.Remove(ele)
kv := ele.Value.(*entry)
delete(c.cache, kv.key)
c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
}
// Add adds a value to the cache.
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
kv := ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len())
kv.value = value
} else {
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
c.nbytes += int64(len(key)) + int64(value.Len())
}
for c.maxBytes != 0 && c.maxBytes < c.nbytes {
c.RemoveOldest()
}
}
CPP 版本
class Node {
public:
int key, value;
Node *prev, *next;
Node(int k = 0, int v = 0) : key(k), value(v) {}
};
class LRUCache {
private:
int capacity;
Node *dummy; // 哨兵节点
unordered_map<int, Node*> key_to_node;
// 删除一个节点
void remove(Node *x) {
x->prev->next = x->next;
x->next->prev = x->prev;
}
// 在链表头添加一个节点
void push_front(Node *x) {
x->prev = dummy;
x->next = dummy->next;
x->prev->next = x;
x->next->prev = x;
}
Node *get_node(int key) {
auto it = key_to_node.find(key);
if (it == key_to_node.end())
return nullptr;
auto node = it->second;
remove(node);
push_front(node);
return node;
}
public:
LRUCache(int capacity) : capacity(capacity), dummy(new Node()) {
dummy->prev = dummy;
dummy->next = dummy;
}
int get(int key) {
auto node = get_node(key);
return node ? node->value : -1;
}
void put(int key, int value) {
auto node = get_node(key);
if (node) {
node->value = value; // 更新 value
return;
}
key_to_node[key] = node = new Node(key, value);
push_front(node);
if (key_to_node.size() > capacity) {
auto back_node = dummy->prev;
key_to_node.erase(back_node->key);
remove(back_node);
delete back_node;
}
}
};
最不经常使用算法(LFU)
将最近一段时间内访问次数最少的块换出,也需要设置计数器,每访问一次计数器加1,有点类似LRU但不完全相同。软件层面使用两个hash标来实现
GO 实现
// LFU the Least Frequently Used (LFU) page-replacement algorithm
type LFU struct {
len int // length
cap int // capacity
minFreq int // The element that operates least frequently in LFU
// key: key of element, value: value of element
itemMap map[string]*list.Element
// key: frequency of possible occurrences of all elements in the itemMap
// value: elements with the same frequency
freqMap map[int]*list.List // 维护一个频率和list的集合
}
// initItem to init item for LFU
func initItem(k string, v any, f int) item {
return item{
key: k,
value: v,
freq: f,
}
}
// Get the key in cache by LFU
func (c *LFU) Get(key string) any {
// if existed, will return value
if e, ok := c.itemMap[key]; ok {
// the frequency of e +1 and change freqMap
c.increaseFreq(e)
obj := e.Value.(item)
return obj.value
}
// if not existed, return nil
return nil
}
// increaseFreq increase the frequency if element
func (c *LFU) increaseFreq(e *list.Element) {
obj := e.Value.(item)
// remove from low frequency first
oldLost := c.freqMap[obj.freq]
oldLost.Remove(e)
// change the value of minFreq
if c.minFreq == obj.freq && oldLost.Len() == 0 {
// if it is the last node of the minimum frequency that is removed
c.minFreq++
}
// add to high frequency list
c.insertMap(obj)
}
// Put the key in LFU cache
func (c *LFU) Put(key string, value any) {
if e, ok := c.itemMap[key]; ok {
// if key existed, update the value
obj := e.Value.(item)
obj.value = value
c.increaseFreq(e)
} else {
// if key not existed
obj := initItem(key, value, 1)
// if the length of item gets to the top line
// remove the least frequently operated element
if c.len == c.cap {
c.eliminate()
c.len--
}
// insert in freqMap and itemMap
c.insertMap(obj)
// change minFreq to 1 because insert the newest one
c.minFreq = 1
// length++
c.len++
}
}
// insertMap insert item in map
func (c *LFU) insertMap(obj item) {
// add in freqMap
l, ok := c.freqMap[obj.freq]
if !ok {
l = list.New()
c.freqMap[obj.freq] = l
}
e := l.PushFront(obj)
// update or add the value of itemMap key to e
c.itemMap[obj.key] = e
}
// eliminate clear the least frequently operated element
func (c *LFU) eliminate() {
l := c.freqMap[c.minFreq]
e := l.Back()
obj := e.Value.(item)
l.Remove(e)
delete(c.itemMap, obj.key)
}
Cache 写策略
对于写请求,可能会出现Cache写了主存没有写,造成数据不一致的问题,所以针对写请求,会有相应的Cache写策略进行处理。
写命中
全写法/直写法
Cache命中是,将数据同时写入Cache和主存,调出是不需要写主存,直接覆盖Cache即可,实现简单能随时保证数据的正确性,但是增加了访存次数。
写缓冲:在主存和Cache之间设置一个缓冲区,Cache往缓冲区写,主存再从缓冲同步,一定程度上解决速度不匹配的问题,但写得太频繁可能导致缓冲区溢出。
回写法
只写Cache不写主存,只在Cache行被替换时写入主存,访存次数少,但是存在数据不一致的隐患,Cache行中需要设置一位脏位标记该行是否被修改。
写不命中
写分配法
更新主存单元,然后把主存块调入Cache。通常和回写法一起使用
非写分配法
只更新主存单元,通常和全写法一起使用
