
NER任务(命名实体识别)这个是比较有年头的任务了

NER任务的一个挑战就是同一个词在不同上下文可能是不同的命名实体,那我们的思路就是:
通过对该词在某一窗口内附近的词来对其进行分类(这里的类别是人名,地点,机构名等等)。
我们以下图为例,希望探测到地名Paris。设置窗口大小为2,那这样就能得到5个单词在一起的窗口,形成一个更大的向量。

思路:
对于museums in Paris are amazing,我们希望探测到地点名Paris。假设窗口大小为2,并且通过词向量方法如word2vec得到窗口内5个单词的词向量,则我们可以将这5个向量连在一起得到更大的向量,再对该向量进行classification。
对于多分类问题,我们使用softmax实现classification,损失函数就是交叉熵损失,还是比较经典的有监督多分类问题。
$$p(y|x)=\frac{exp(W_y\cdot x)}{\sum_{c=1}^kexp(W_c\cdot x)}$$
$$J(\theta)=\frac1N\sum_{i=1}^N-log\left(\frac{exp(W_y\cdot x)}{\sum_{c=1}^kexp(W_c\cdot x)}\right)$$

这里教授又说了一下传统的ML的softmax是线性分类关系,且输入x是独热编码,只能学到softmax函数中的一些参数,学不到模型的输入参数,且会有很多边界问题。但深度神经网络则充分应用了非线性关系,决策也更合理。

大概整个的二分类过程如下:

这里作者对交叉熵损失简单说了一下:

这里有一个小细节还是想说:
其实我们最后看到交叉熵损失函数中只有负对数概率这部分,并没有正确概率的部分,原因是一般正确概率这部分用one-hot编码,只有在正确类别上是1,其余位置是0,所以一相乘,就会只有负对数概率那部分了。
论非线性的重要性:
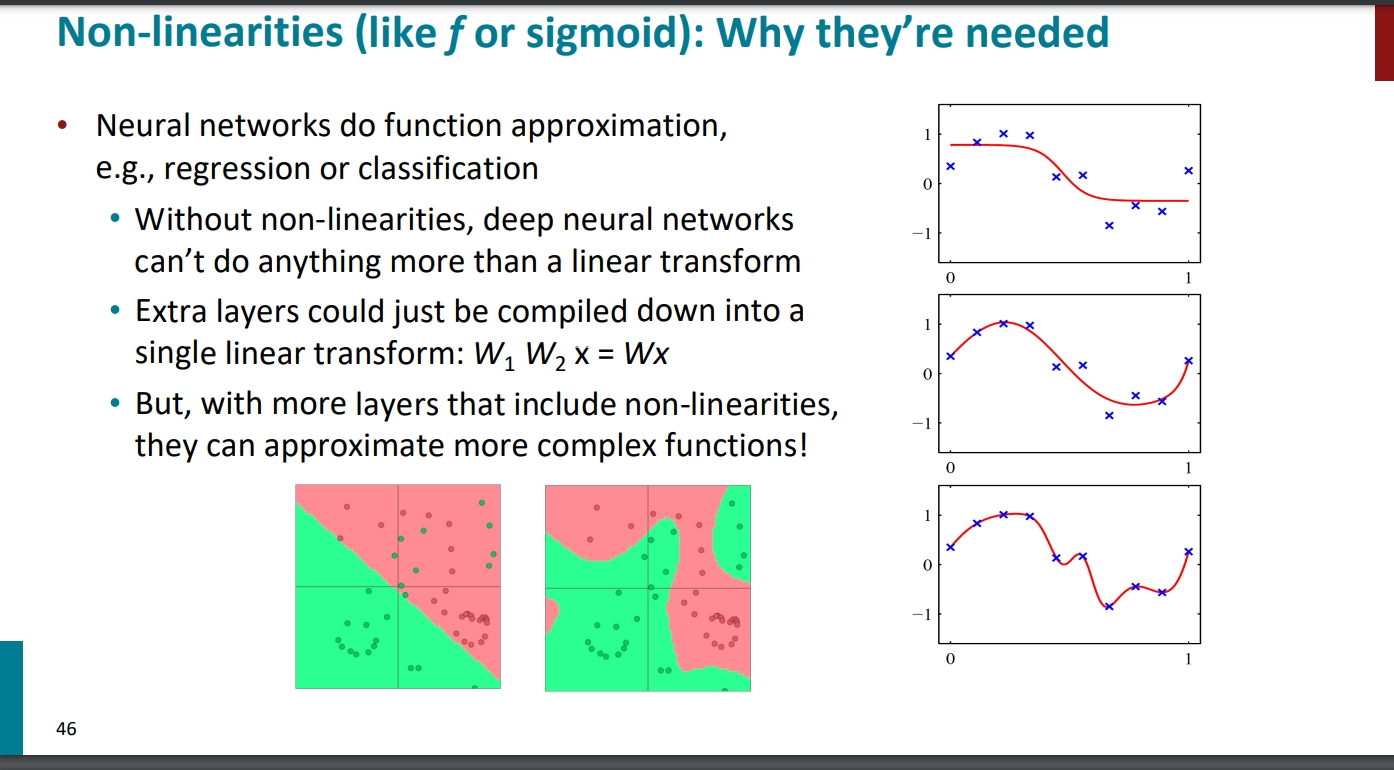 、
、
最后,作者给出了一些激活函数(非线性的办法),我们再一起看一下复习一下hh

参考
https://zhuanlan.zhihu.com/p/61601575
https://web.stanford.edu/class/cs224n/
