
模型选择
训练误差:
- 模型在训练数据的误差
泛化误差:
- 模型在新数据上的误差
验证数据集:一个用来评估模型好坏的数据集。
测试数据集:只用一次的数据集。
k-则交叉验证:
- 在没有足够多的数据时使用(这是常态)
- 算法
- 将数据分成K块
- For i in 1,2,..,k
- 使用第i块作为验证数据集,其余作为训练数据集
- 报告K个验证集误差的平均
- 常用:k = 0 或 k = 10
过拟合和欠拟合

模型容量:
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有训练数据
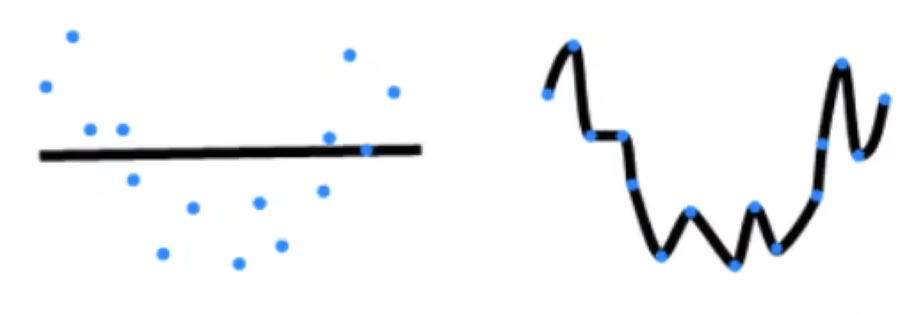
估计模型容量:
- 难以在不同的种类算法之间比较
- 例如树模型和神经网络
- 给定一个模型种类,将有两个主要因素
- 参数的个数
- 参数值的选择范围
数据复杂度:
- 多个重要因素
- 样本个数
- 每个样本的元素个数
- 时间,空间结构
- 多样性
总结
- 模型容量需要匹配数据复杂度,否则可能导致过拟合或欠拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差
