
机器翻译是nlp中的较早的但却是很重要的任务。任务要求很简单,就是给定源语言的句子作为输入,得到目标语言的句子作为输出。
按照时间发展,一般分成两大类方法:
1. 基于统计信息的(SMT)
2. 基于神经网络的(NMT)
SMT
还这个思想的核心是从数据中学习出概率模型,其实是需要两个模型。一个$P(x|y)$是用来处理具体单词和词组翻译的,一个$P(y)$是用来将这些局部的信息进行组合,让翻译的句子更合理流畅。
整个的过程相当于:$\underset{y}{\operatorname*{argmax}}P(x|y)$
NMT
这个方法主要是seq-seq模型架构。即encoder将input(也就是源语言)映射为向量,再用一个decoder将其转化为output(目标要的翻译后的语言)。这里的decoder其实很像一个语言模型,即将encoder的信息作为输入,预测目标句子的下一个单词是什么。
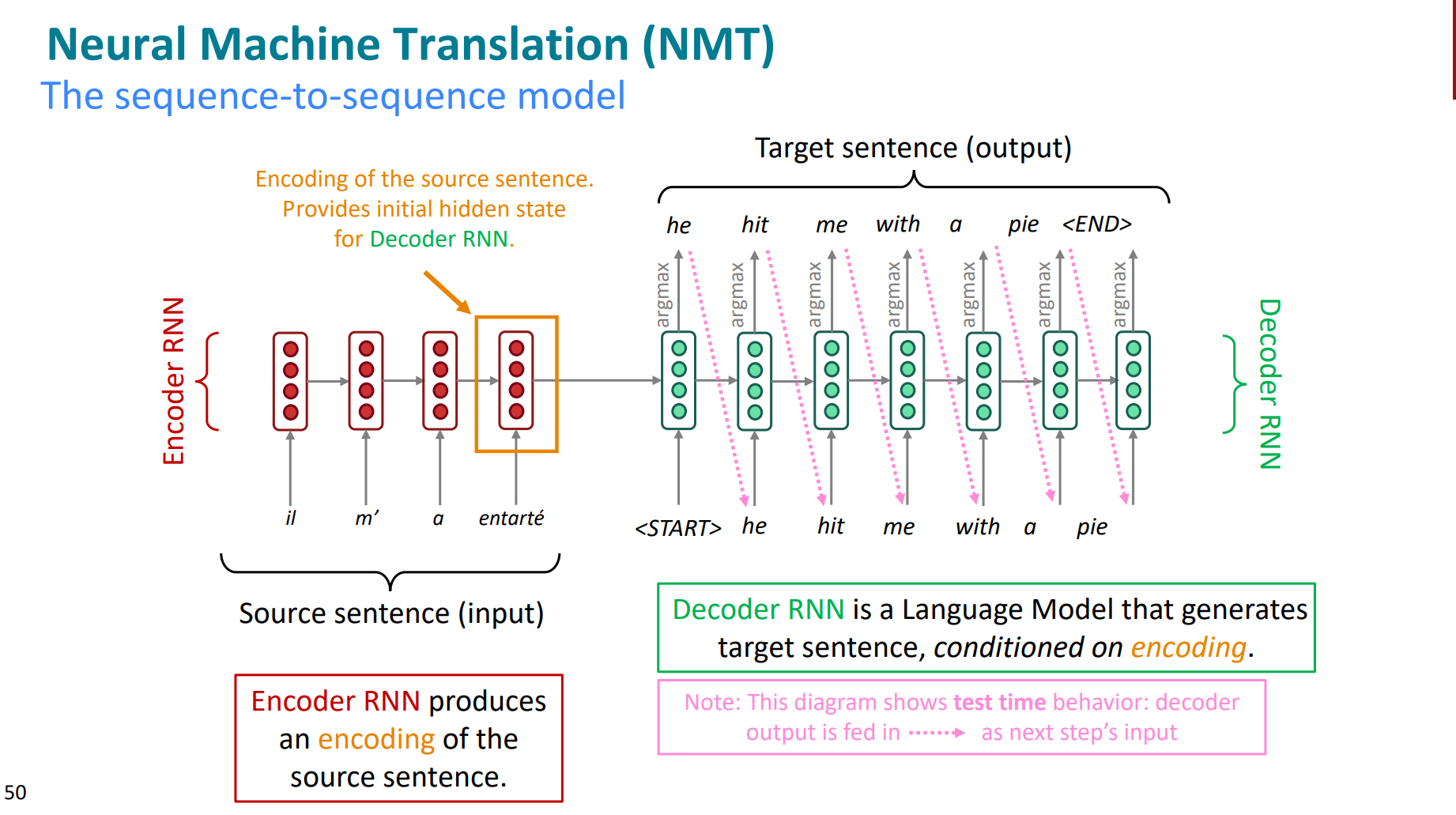
那么seq2seq的定义其实就很清晰了,如下:
- 一个net将输入映射为高维向量。
- 一个net将向量还原为输出。
- 如果input和output的都是sentence,那么就是seq2seq

这么一看,seq2seq的应用场景很多。比如摘要、对话、句法分析、代码生成等等。

seq2seq模型架构的特点是很清晰的,属于是一种“条件语言模型”。涉及了两个关键词,即“条件模型”和“语言模型”。
1. conditional:因为预测结果是基于输入的源信息的。
2. language:符合语言模型的特点,即根据已知序列(input)预测下一个word。
之所以区别传统的语言模型,就是因为还要基于已有的源输入x做预测。


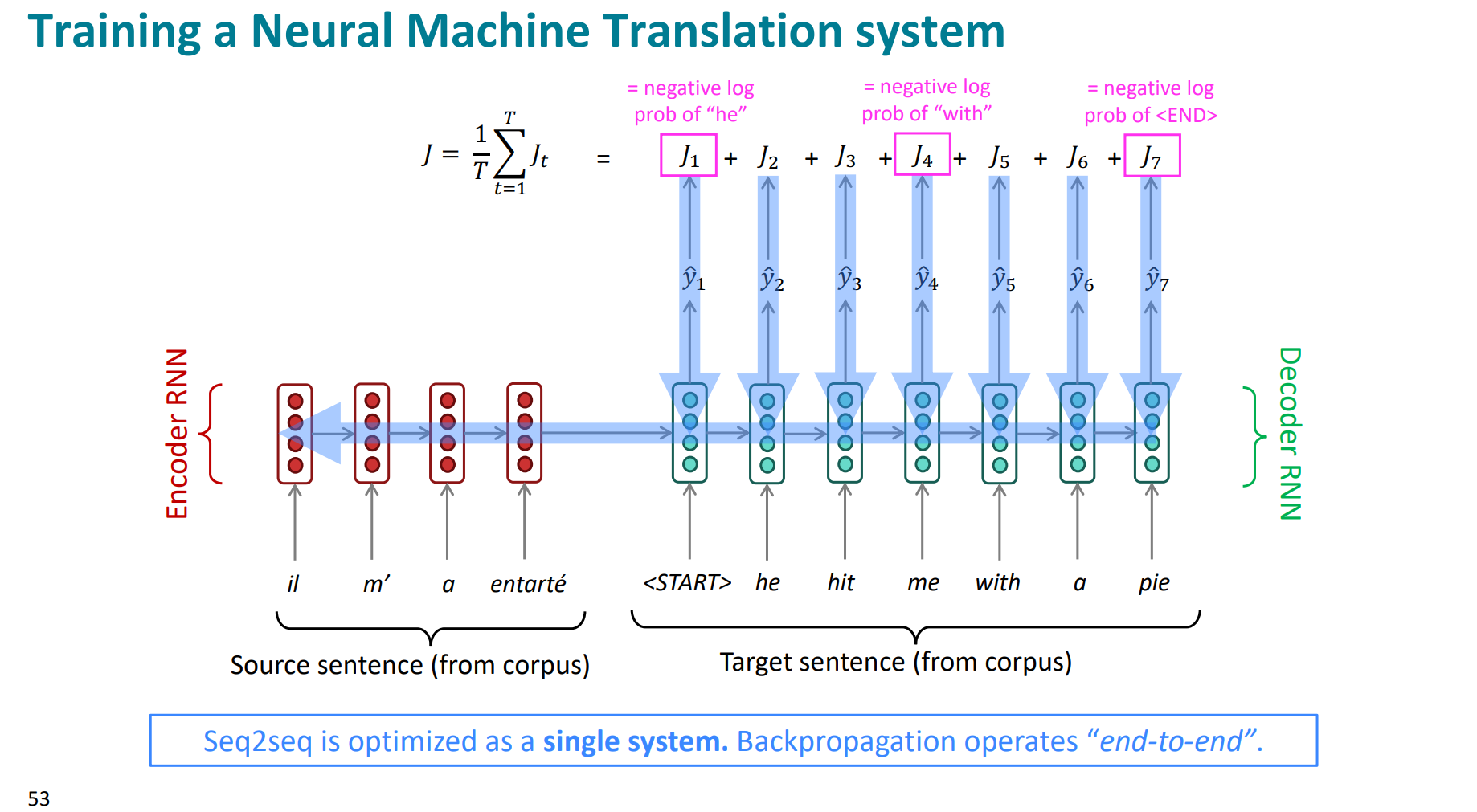
我们看一下如何训练这种seq2seq模型。
反向传播优化参数的时候,不仅可以优化decoder端,encoder端也可以优化,即模型整体都可以被优化,是一种端到端end2end的表现。
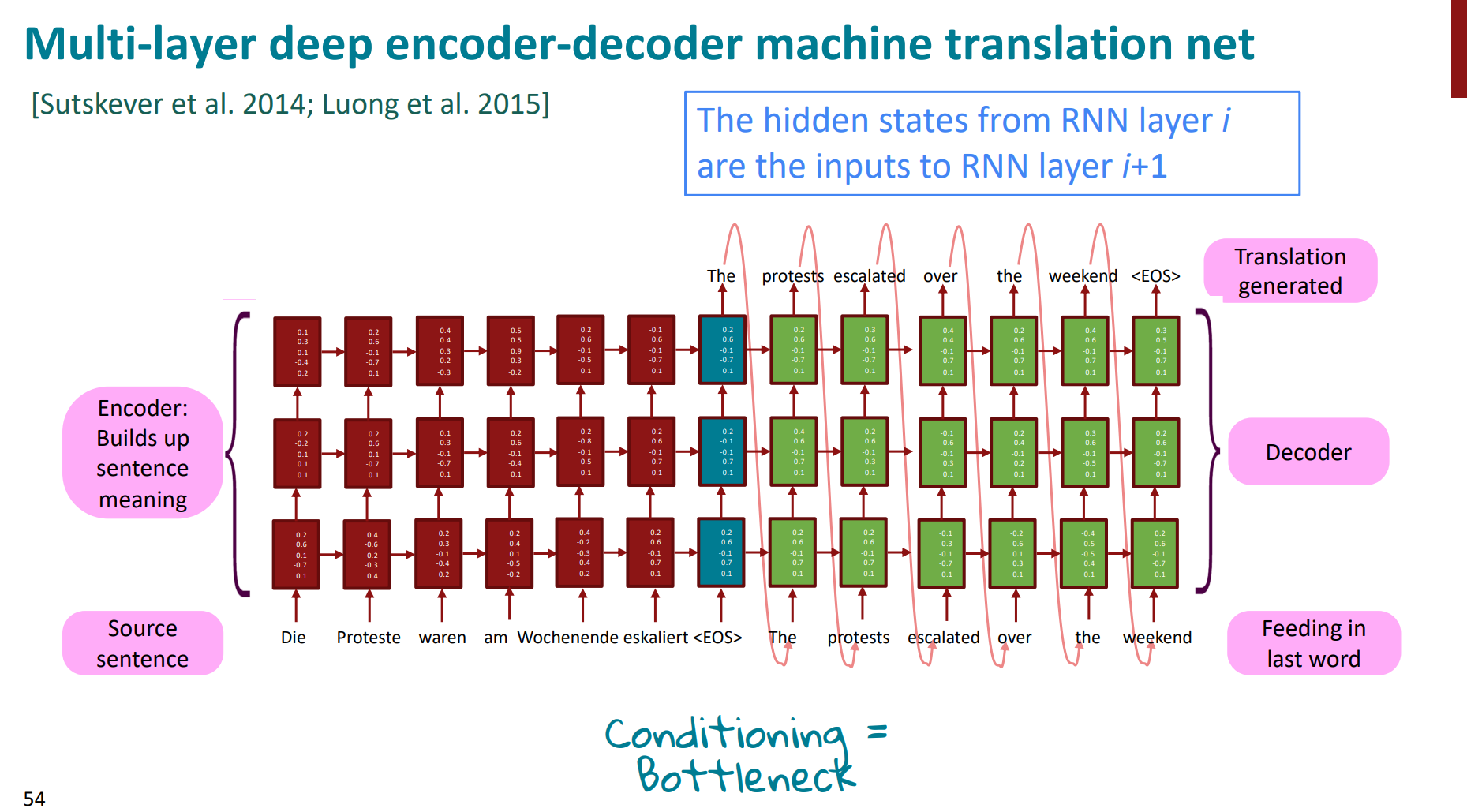
当然,我们为了模型性能更好,完全可以让层数更多更深,比如muti-layer。
我们在推理的时候,可以是贪心算法,即每一步选取当前出现概率最大的word。
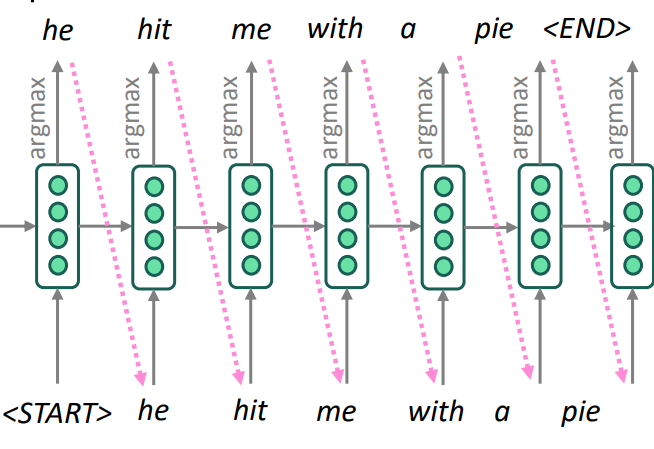
这样很方便,但问题就是每一步的最优解,不一定是整体的最优解。即可能当前的最大概率的单词对于翻译整个句子来讲不一定是最优的选择。但这就是贪心的特点,我们没法选择别的路径,只有这一条路径。
所以,为了解决这种局部解的累加不一定等于最优解问题的情况,常见的思路是束走索beam search。
也就是不再选择当前概率最大的那个word,而是选择当前概率最大的前k个word,逐一去尝试不同的路径。这比贪心要合理很多,但复杂度也是提升了很大。
到这儿,我们的NMT和SMT的对比也就差不多了。其实能看出来NMT的最大优势,就是不用去单独优化翻译模型和语言模型了,直接优化一个整体的条件语言模型就够了,实现了端到端优化。
端到端的思想,也是在很多场景和业务中被使用,减少了很多的耦合性。
彩蛋:我们之后开始进军attention。
参考致谢
https://web.stanford.edu/class/cs224n/index.html
https://www.bilibili.com/video/BV18Y411p79k?spm_id_from=333.788.videopod.episodes&vd_source=de334f24ee86583df2785811808ca76b&p=7
https://zhuanlan.zhihu.com/p/64887738
