玩转基础模型
环境
万事配环境难。不过万能的公开课,已经把相关的conda环境准备好了。
列举几个conda包如下:
# packages in environment at /root/share/pre_envs/icamp3_demo:
cuda-cudart 12.1.105 0 nvidia
cuda-cupti 12.1.105 0 nvidia
cuda-libraries 12.1.0 0 nvidia
cuda-nvrtc 12.1.105 0 nvidia
cuda-nvtx 12.1.105 0 nvidia
cuda-opencl 12.5.39 0 nvidia
cuda-runtime 12.1.0 0 nvidia
cuda-version 12.5 3 nvidia
libcublas 12.1.0.26 0 nvidia
libcufft 11.0.2.4 0 nvidia
libcufile 1.10.1.7 0 nvidia
libcurand 10.3.6.82 0 nvidia
libcusolver 11.4.4.55 0 nvidia
libcusparse 12.0.2.55 0 nvidia
libiconv 1.16 h5eee18b_3 defaults
libnpp 12.0.2.50 0 nvidia
libnvjitlink 12.1.105 0 nvidia
libnvjpeg 12.1.1.14 0 nvidia
ncurses 6.4 h6a678d5_0 defaults
nvidia-cublas-cu12 12.5.3.2 pypi_0 pypi
nvidia-cuda-runtime-cu12 12.5.82 pypi_0 pypi
nvidia-curand-cu12 10.3.6.82 pypi_0 pypi
nvidia-nccl-cu12 2.22.3 pypi_0 pypi
pynvml 11.5.3 pypi_0 pypi
python-dotenv 1.0.1 pypi_0 pypi
pytorch 2.1.2 py3.10_cuda12.1_cudnn8.9.2_0 pytorch
pytorch-cuda 12.1 ha16c6d3_5 pytorch
pytorch-mutex 1.0 cuda pytorch
torchaudio 2.1.2 py310_cu121 pytorch
torchvision 0.16.2 py310_cu121 pytorch
代码
接下来,在对应的conda环境下输入以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
model = model.eval()
system_prompt = """
You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("\nUser >>>")
input_text = input_text.replace(' ', '')
if input_text == "exit":
break
length = 0
for response, code in model.stream_chat(tokenizer, input_text, messages):
if response is not None:
print(response[length:], flush=True, end="")
length = len(response)
模型结果如下:
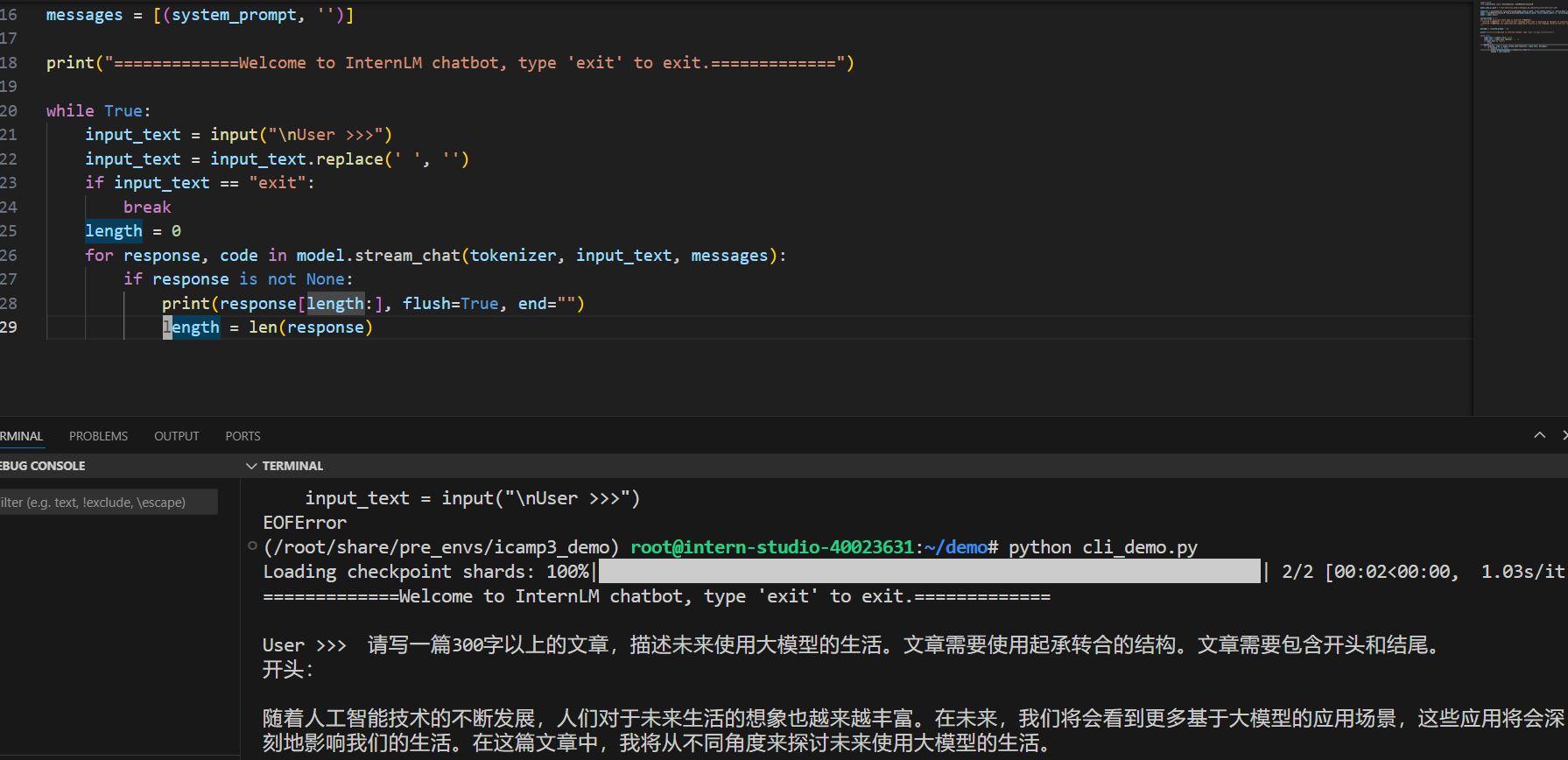
可以看到,代码成功运行,但美中不足的是,我们并不知道实际的字数。
所以,我们在代码中加入统计:
...
for response, code in model.stream_chat(tokenizer, input_text, messages):
if response is not None:
print(response[length:], flush=True, end="")
length = len(response)
print(f"本次回答共{length}字")
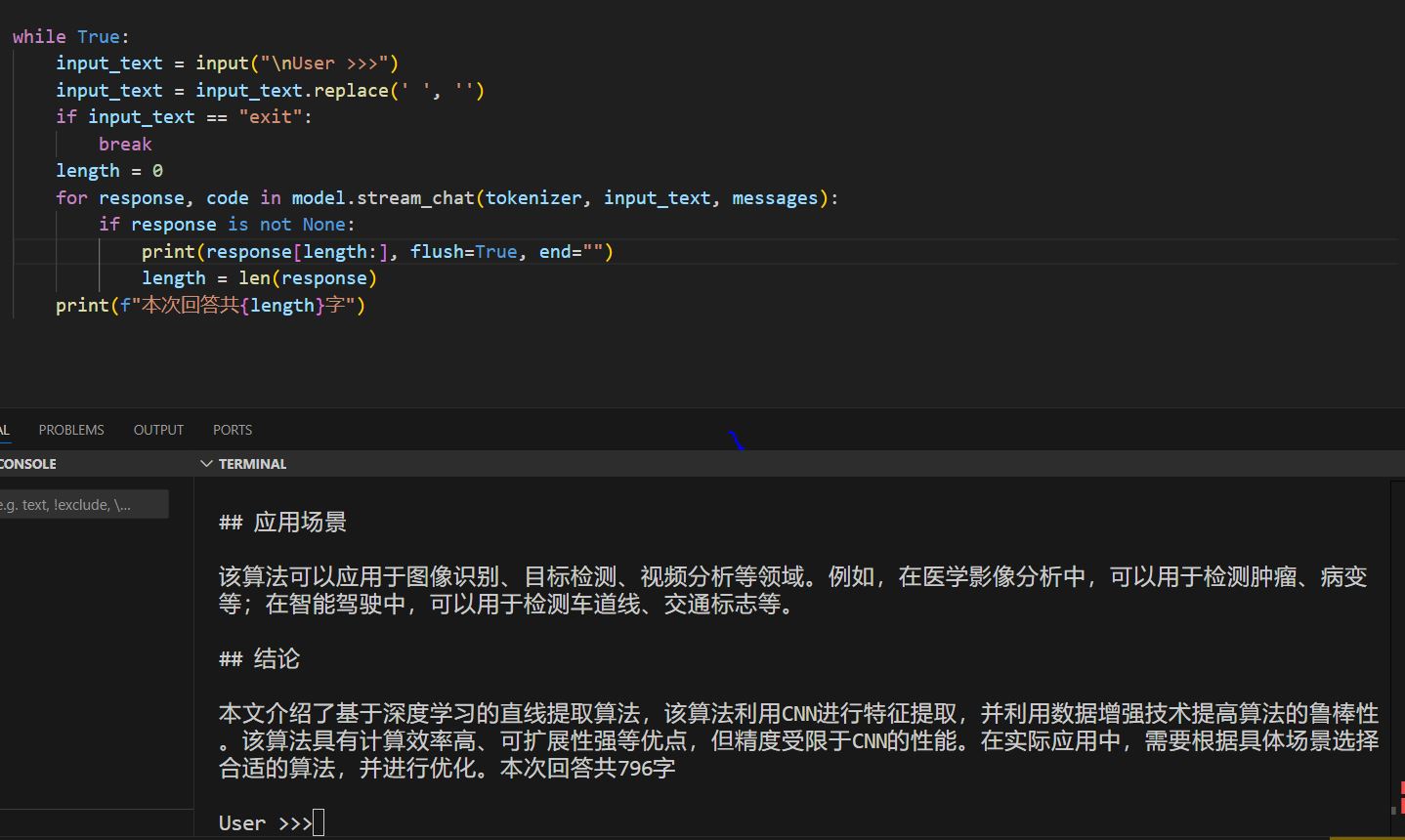
这样就能得到字数了。可以看到,大模型努力一下,还是可以轻松在10秒内写出一篇高考作文的。
资源使用
只有输出当然不够,我们要看是否确实只用了8GB。
共享的服务器不容易看出CPU和负载,这里主要看推理时的GPU负载。
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-SXM4-80GB On | 00000000:B3:00.0 Off | 0 |
| N/A 38C P0 127W / 400W | 4897MiB / 81920MiB | 45% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
lmdeploy 使用xomper2-vl
conda环境不变,输入
lmdeploy serve gradio /share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-vl-1_8b --cache-max-entry-count 0.1
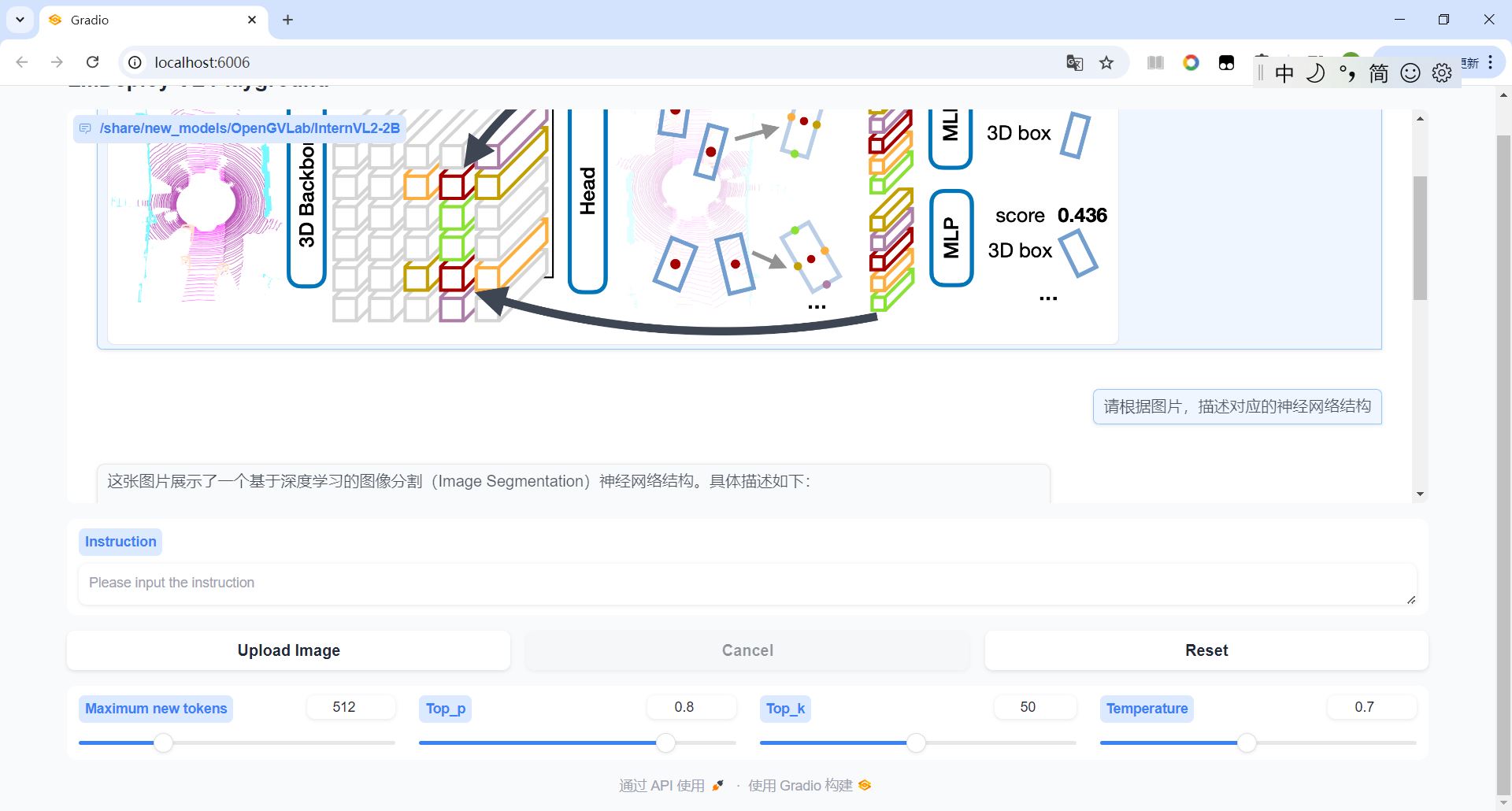
lmdeploy可以根据模型名称匹配,启动对应的web界面和推理程序。
可以上传这个截图,要求进行分析:
更换模型的操作类似,只需要更换模型名称即可。
对应分析内容如下: