
今年是考纲加入 Bellman-Ford 算法的第三年,但一分都还没考过,因此今年考察概率极大,群里最近关于这块的讨论和讲解,务必学透。
1. 相同点
- 目的相同:迪杰斯特拉算法和贝尔曼 - 福特算法都是用于解决图中(有向图或无向图,这里重点是有向图)单源最短路径问题。即从一个给定的源节点出发,找到到其他所有节点的最短路径长度。
- 基本思想相关:都基于松弛操作来逐步更新最短路径的估计值。松弛操作是指对于边((u, v)),如果从源节点到(u)的距离加上(u)到(v)的边权小于当前从源节点到(v)的估计距离,那么就更新从源节点到(v)的距离。
2. 不同点
- 算法策略
- 迪杰斯特拉算法:是一种贪心算法。它每次选择当前距离源节点最近的未确定最短路径的节点,将其标记为已确定最短路径的节点,然后对其相邻节点进行松弛操作。这个过程不断重复,直到所有节点的最短路径都被确定。
- 贝尔曼 - 福特算法:基于动态规划的思想。它对图中的所有边进行(V - 1)次松弛操作((V)是图中的节点数),每次松弛操作都会更新所有边对应的最短路径估计值。在(V-1)次松弛操作后,如果还能对某条边进行松弛,说明图中存在负权回路。
- 时间复杂度
- 迪杰斯特拉算法:
- 用普通的邻接矩阵存储图,时间复杂度是(O(V^{2})),其中(V)是节点数。这是因为在每次选择距离源节点最近的节点时,需要遍历所有未确定最短路径的节点,这个操作的时间复杂度是(O(V)),总共需要进行(V)次这样的选择,并且每次选择后还要对相邻节点进行松弛操作,时间复杂度也是(O(V)),所以总的时间复杂度是(O(V^{2}))。
- 用二叉堆(优先队列)来优化选择距离源节点最近节点的过程,时间复杂度可以降低到(O((V + E)\log V)),其中(E)是边数。因为每次从堆中取出最小元素的时间复杂度是(O(\log V)),总共需要进行(V)次这样的操作,而每次取出元素后对相邻节点进行松弛操作并更新堆的时间复杂度是(O(E\log V))。
- 贝尔曼 - 福特算法:时间复杂度是(O(VE))。因为需要对所有的(E)条边进行(V - 1)次松弛操作。
- 迪杰斯特拉算法:
- 空间复杂度
- 迪杰斯特拉算法:
- 用邻接矩阵存储图时,空间复杂度是(O(V^{2})),因为需要存储(V^{2})的矩阵来表示图中节点之间的边权关系。
- 用邻接表存储图并且用优先队列优化时,空间复杂度是(O(V + E)),其中(V)是节点数,(E)是边数。因为需要存储节点的邻接表以及优先队列中的元素。
- 贝尔曼 - 福特算法:空间复杂度是(O(V + E))。因为需要存储图的邻接表结构(存储边的信息)以及每个节点的最短路径估计值,总共需要(O(V))的空间来存储最短路径估计值,(O(E))的空间来存储边的信息。
- 迪杰斯特拉算法:
3. 只能使用贝尔曼 - 福特算法的情况
- 当图中存在负权边,并且可能存在负权回路时,迪杰斯特拉算法可能会出错,而贝尔曼 - 福特算法可以正确处理。例如,有一个有向图(G=(V, E)),如下图(a)所示,其中(V = {0,1,2}),(E={(0,1,7),(1,2,-5),(0,2,5)}),源节点为(0)。迪杰斯特拉算法在选择节点的贪心策略下,会先选择节点(2),然后选择节点(1),但由于它已经确定了节点(2)的距离为(5),通过边((1,2))已经无法再更新这个更小的值,导致错误。
- 而贝尔曼 - 福特算法会通过多次松弛操作正确地找到从节点(0)到节点(2)的最短路径为(2),详细过程如下。
- 对于图(a),源节点为(0):
- 初始化:设(dist[0]=0),(dist[1]=∞),(dist[2]=∞)。
- 第1次迭代:
- 考虑边((0,1)),更新(dist[1]=min(∞,7)=7)。
- 考虑边((0,2)),更新(dist[2]=min(∞-5,5) = 5)。
- 第2次迭代:dist[1]不变,(dist[2]=min(5,7+(-5) = 2)
- 由于没有负权回路(这里只有(3)个节点,最多迭代(2)次就可以确定最短路径),不会再更新距离。
- 对于图(a),源节点为(0):
- 最终,Bellman-Ford算法能够正确地找到从源节点(0)到节点(2)的最短路径为(2)。
所以,在存在负权边的图中,如上述有向图,Dijkstra算法可能无法找到正确的最短路径,而Bellman - Ford算法能够正确地计算出最短路径。
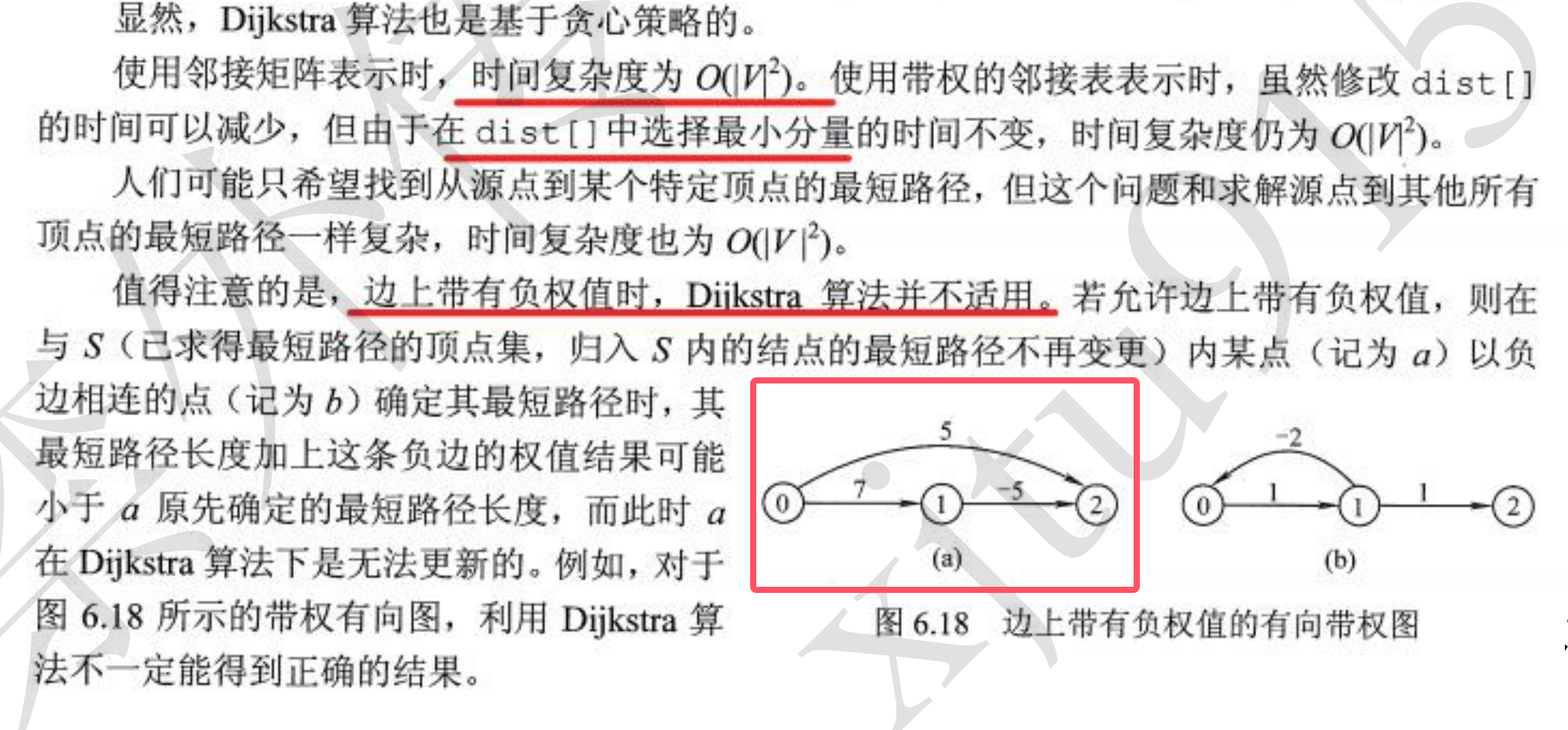
注意,并不是所有的负权图 dijkstra 都不适用,如将 1 到 2 的距离改为-1,此时 dijkstra 仍适用。

今年还是没考哈哈
确实 hh 每年都是 Dijkstra
好文。