
根据“数据在容器中的排列”特性,容器可分为序列式和关联式两种,如下图:
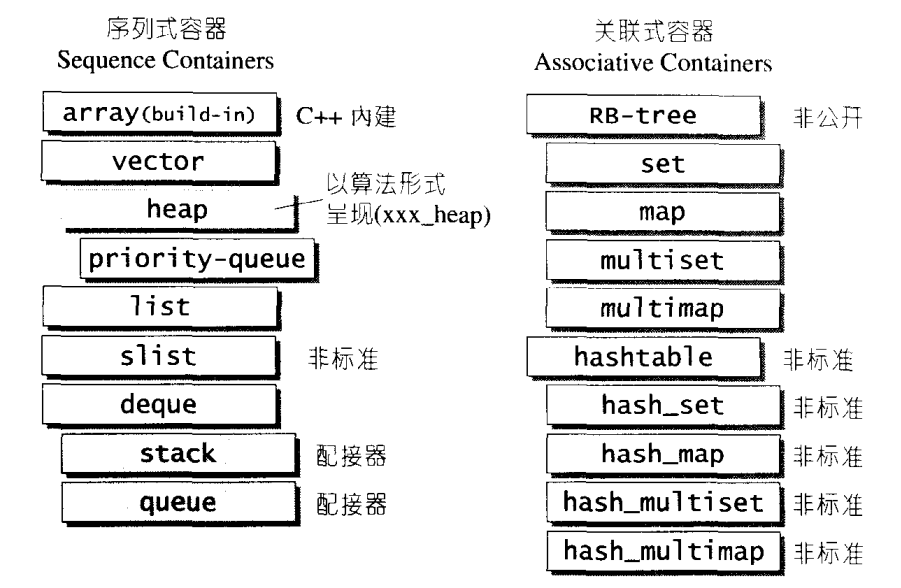
一、序列式容器
所谓序列式容器,其中的元素都可序(ordered),但未必有序(sorted),C++本身提供了一个序列式容器array,STL另外再提供vector,list,deque等序列式容器。
1、vector
vector与array非常相似,主要区别在于array是静态空间,一旦配置了就不能改变,而vector是动态空间,随着元素的加入,它会自行扩容。vector中有size(容器已使用空间)和capacity(容器可用空间)的概念,当size等于capacity时,再新增元素就会触发重新分配。
2、list
list的好处是对元素的插入或移除只需要常数时间,而且插入操作不会造成原有迭代器失效(vector中会),STL中的list是一个双向链表。
list<int> ilist;
... //插入若干元素
for (list<int>::iterator ite = ilist.begin(); ite != ilist.end(); ++ ite) { ... } //遍历list
3、deque
deque和vector的区别:
- deque允许于常数时间内对两端进行元素的插入或移除操作;
- deque没有容量的观念,它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。
- array无法成长,vector只能向尾端成长(会导致重新分配),deque可以向两端成长(不会导致重新分配)。
deque的底层结构如下图:
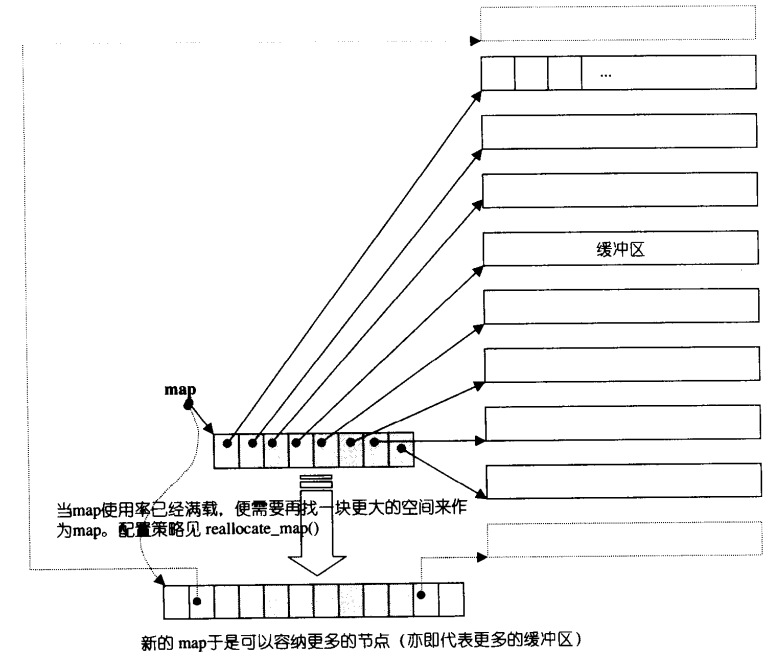
deque采用一块所谓的map(一小块连续空间)作为主控,map中每个元素都是指针,指向另一段(较大的)连续线性空间,称为缓冲区,缓冲区才是deque的储存空间主体。
注意:deque是分段连续空间,其迭代器 operator++ 和 operator-- 维持了其“整体连续”的假象。
4、stack
stack的底部结构是deque,把deque的一个开口封掉,就形成了一个stack。所以stack并不是一个容器(container),而是一个配接器(adapter)。stack没有迭代器,不提供遍历功能。
5、queue
queue只允许从底端加入元素和从顶端取出元素,其底部数据结构是deque,封闭deque底端的出口和前端的入口即形成了一个queue,所以queue也是一个配接器。queue没有迭代器,不提供遍历功能。
6、heap
heap并不归属于STL容器组件,其内部结构是完全二叉树,heap有两种实现:max-heap(堆顶为最大元素)和min-heap(堆顶为最小元素),它更像是一种算法,用来实现priority_queue。
7、priority_queue
默认情况下的priority_queue用vector来表现完全二叉树,并使用max-heap算法作为规则。只有顶端的元素才有机会被外界取用,且不提供遍历功能,没有迭代器。
8、slist
slist就是一个单链表。
二、关联式容器
所谓关联式容器,就是每笔数据都有一个键值(key)和实值(value),当元素被插入到关联式容器中时,容器内部结构便依照其键值大小,以某种特定规则将这个元素放置于适当位置。
set的键值就是实值,map的键值与实值可以分开,形成一种映射关系。
1、树
树是一种非常基础的数据结构,几乎所有操作系统都将文件存放在树状结构里。
1)二叉搜索树
二叉搜索树的规则是:任何节点的键值一定大于其左子树中的每一个节点的键值,并小于其右子树中的每一个节点的键值。二叉搜索树可提供对数时间的元素插入和访问,其中序遍历就是顺序遍历。
缺点:当输入的值不够随机,或经过某些插入删除操作后,二叉搜索树会失去平衡,造成搜寻效率低下的情况。
2)AVL树(Adelson-Velskii-Landis tree)
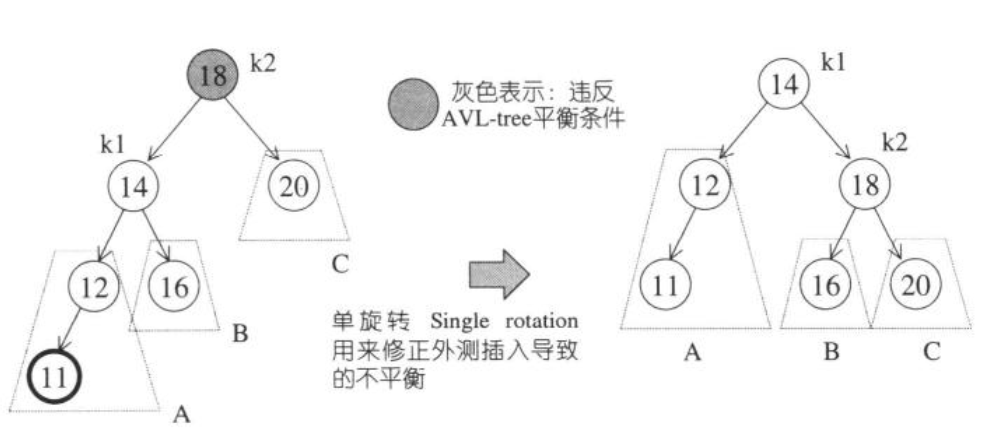
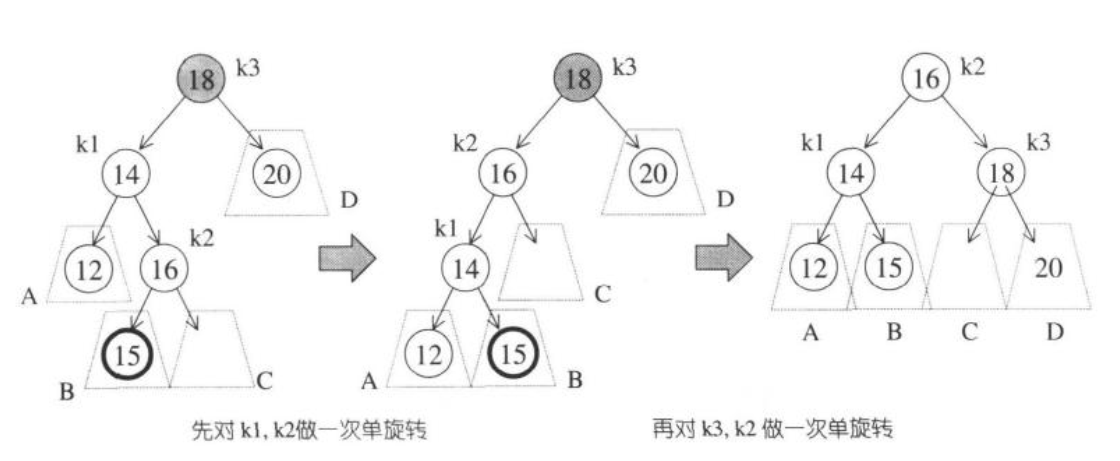
AVL tree是一个“加上了额外平衡条件”的二叉搜索树,其条件是为了确保整棵树的深度为$O(logN)$。AVL tree要求任何节点左右子树高度最多相差1,如果新插入的节点将平衡打破,可以通过单旋转或双旋转恢复平衡,如下图:
单旋转:用于修正外侧插入导致的不平衡(外侧插入:例如12的左子节点与16的右子节点)。
双旋转:用于修正内侧插入导致的不平衡(内侧插入:例如12的右子节点与16的左子节点)。
AVL tree为了维护它的高度平衡,需要高频率的调整(旋转),适用于查询多、增删少的场景。
3)红黑树(RB-tree)
红黑树同样运用了单旋转和双旋转修正操作,平衡性比AVL树要弱,但两者效率几乎相等。红黑树主要用来实现set与map。
特点:
- 每个节点非红即黑;
- 根节点为黑色;
- 如果节点为红色,其子节点必须为黑;
- 新插入的节点必须为红色;
- 任一节点到叶子节点的任何路径上黑节点数必须相同。
由于红黑树平衡性较弱,不要求任何节点左右子树高度最多相差1,故调整频率较低,适用于增删频繁的场景。
总结:
AVL树查找效率高,红黑树增删效率高(不需要频繁地旋转)。
2、set
set中所有元素都会根据元素的键值自动被排序,不允许有相同的键值,且键值无法改变。
multiset与set完全相同,唯一的差别在于它允许键值重复。
3、map
map中所有元素都会根据元素的键值自动排序,其中所有元素都是pair,同时拥有键值和实值,且不允许两个元素拥有相同键值,不允许改变键值,但可以改变实值。
multimap与map完全相同,唯一的差别在于它允许键值重复。
4、hashtable
使用哈希表会带来一个问题:可能有不同的元素被映射到相同的位置(亦即有相同的索引),这便是所谓的“碰撞(collision)”问题,解决碰撞问题的方法有很多种:线性探测、二次探测、开链等,我们目前所使用的实现就是开链法,如下图:
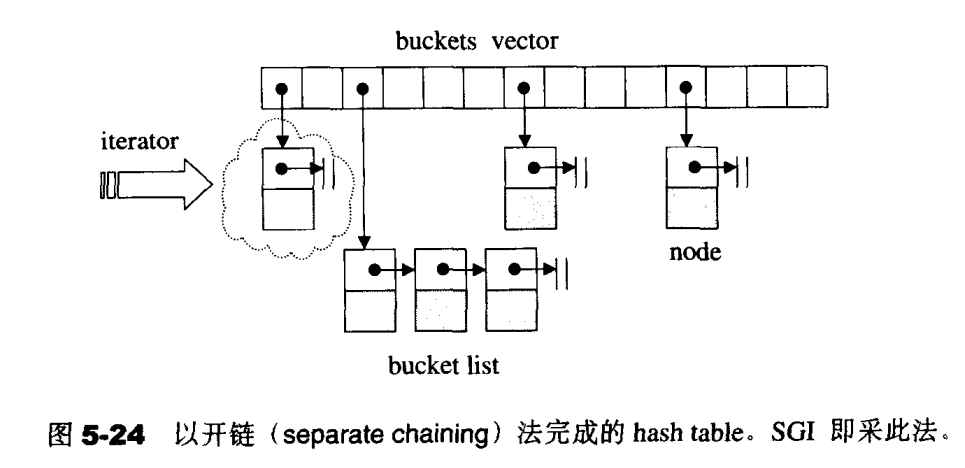
可以简单地把hashtable想象成一个vector,vector里面的每个元素又是一个list,即链表的数组。hashtable的查找、插入和删除操作的时间复杂度都是常数级别,但当表被基本填满时,性能下降非常严重。hashtable内置了28个质数(53,97,193 … ),在创建hashtable时会根据存入元素的个数选择大于元素个数的质数作为hashtable的容量(vector的长度),其中每个bucket所维护的linked-list长度也等于hashtable的容量,如果插入元素超过了bucket数量,就要找下一个质数作为容量,重建hashtable。
如果当前桶中链表元素达到8个时,链表会转换为红黑树,以提高遍历效率。
5、hash_set
hash_set的使用方式与set完全相同,但set的元素有自动排序功能,hash_set没有。
hash_multiset的特性与multiset完全相同,唯一的差别在于它的底层机制是hashtable,也因此,hash_multiset的元素并不会被自动排序。
6、hash_map
hash_map的使用方式与map完全相同,但map的元素有自动排序功能,hash_map没有。
hash_multimap的特性与multimap完全相同,唯一的差别在于它的底层机制是hashtable,也因此,hash_multimap的元素并不会被自动排序。
三、Algorithm
整理ing…
参考文献
《STL源码剖析》–侯捷
