
将yxc的图论模板进行了整理,给出了AC代码,并且对于关键思路加上了文字描述。便于没有听过算法基础课的同学容易理解。
最短路算法
单源最短路算法(非负权边)
朴素Dijkstra算法
dijkstra是基于贪心算法的,如果有负权边的话,会导致贪心算法的不正确,比如:
a->b = 50,a->c = 60,c->b = -100,那么其实a->b的最短路径应该是a - c - b,但是贪心算法会在第一步就确定下来到b的最短路径是50。
该算法的核心在于将所有的点划分为两个部分,一部分是到源点的最短距离已经确定了的点,另一部分则是还没有确定的。每次我们在还没有确定最短距离的所有点中找到一个距离源点最近的,这个点就是新的确定的点,然后我们利用这个最新的点来更新其余还没有确定的点的最短距离。直至所有点的最短距离都已经确定了。
我们使用visit数组标记每个点是否已经确定了,dist数组标记每个点到源点的最短距离。
时间复杂度:O(n2),空间复杂度o(n2)
题目链接:https://www.acwing.com/problem/content/851/
#include<stdio.h>
#include<cstring>
#include<iostream>
using namespace std;
const int N = 510;
int graph[N][N],dist[N];
bool visit[N];
int n,m,from,to,weight;
int main()
{
scanf("%d %d",&n,&m);
memset(graph,0x3f,sizeof(graph));
memset(dist,0x3f,sizeof(dist));
for(int i = 1 ; i <= n ; i ++)
graph[i][i] = 0;
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
graph[from][to] = min(graph[from][to],weight);
}
dist[1] = 0;
for(int i = 0 ; i < n ; i ++)
{
int t = -1;
for(int j = 1 ; j <= n ; j ++)
{
if(visit[j] == true) continue;
if(t == -1 || dist[j] < dist[t])
t = j;
}
visit[t] = true;
for(int j = 1 ; j <= n ; j ++)
dist[j] = min(dist[j],dist[t] + graph[t][j]);
}
if(dist[n] == 0x3f3f3f3f) printf("-1");
else printf("%d",dist[n]);
return 0;
}
堆优化版dijkstra算法
首先我们在朴素dijkstra算法中发现,我们每次都要为了遍历n个顶点来找到下一个当前最小值,我们很自然的就会想到使用小顶堆来优化查找当前最小值。
首先我们使用链式前向星来存储稀疏图:链式前向星主要原理就是使用静态数组来模拟链表存储以每个点为起点的所有边。
- 数组包括链表头节点数组
h[N],初始为-1,代表当前没有节点。 - 边的权值数组
w[N],存储第i条边的权值 - 边的终点数组
e[N],存储第i条边的终点 - 链表数组
ne[N],存储与第i条边的起点相同的所有边中下一条边的序号 idx,表示已经存入了多少条边,也代表下一条读入的边的序号
这里需要额外注意:h数组是关于节点的开到N即可,但是w,e,ne数组是存储边的,需要开到M,同时如果是双向图还需要开到2*m
添加一条边:
//添加一条起点为a,终点为b,权重为weight的有向边
void add(int a,int b,int weight)
{
e[idx] = b;//第idx条边的终点b
w[idx] = weight;//第idx条边的权重为weight
ne[idx] = h[a];//h[a]是以a为起点的最后一条读入的边的序号,我们将第idx条边指向这条边
h[a] = idx ++;//更新`h[a]`最后一条读入的边的序号。
}
遍历以第ver个顶点为起点的所有的边:
for(int i = h[ver] ; i != -1 ; i = ne[i])
{
//i代表第当前边的序号,w[i]代表当前边的权重,e[i]代表当前边的终点。
}
我们首先并初始化头节点数组,距离数组,标记数组和边序号,接着我们读入所有的边。我们使用一个关于pair<int,int>的优先队列来维护当前到所有点的可行距离,两个关键字分别代表<当前从1号点到i号点的最短距离,i>。初始时我们将{0,1}放入优先队列,并初始化dist[1] = 0,代表1号节点到1号节点的最短路径是0。
然后我们依次弹出队列头部元素,如果到当前节点的最短距离已经确认过了,那我们直接跳过。否则我们将当前节点ver标记为true,代表当前节点的最短距离在此刻被确认。我们接下来遍历所有以节点ver为起点的所有边的终点j,尝试用经过ver来更新其最短路径,如果到顶点j的最短路径大于经过顶点ver的最短路径,那么我们更新最短路径将该最短路径加入到队列中。
最后判断一下1号点和n号点是否是联通的。
时间复杂度:O(mlogn),适用于稀疏图。
题目链接:
#include<stdio.h>
#include<cstring>
#include<iostream>
#include<limits.h>
#include<queue>
using namespace std;
typedef pair<int,int> PII;
const int N = 100010;
int h[N],w[N],e[N],ne[N],idx = 0;
int dist[N];
bool visit[N];
void add(int a,int b,int weight)
{
e[idx] = b;
w[idx] = weight;
ne[idx] = h[a];
h[a] = idx ++;
}
int main(){
int n,m,first,second,weight;
scanf("%d %d",&n,&m);
memset(dist,0x3f,sizeof(dist));
memset(h,-1,sizeof(h));
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&first,&second,&weight);
add(first,second,weight);
}
priority_queue<PII,vector<PII>,greater<PII>> heap;
heap.push({0,1});
dist[1] = 0;
while(!heap.empty())
{
auto t = heap.top();
heap.pop();
int ver = t.second,distance = t.first;
if(visit[ver]) continue;
visit[ver] = true;
for(int i = h[ver] ; i != -1 ; i = ne[i])
{
int j = e[i];//第i条边的终点为j
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j],j});
}
}
}
int res = (dist[n] == 0x3f3f3f3f ? -1 : dist[n]);
printf("%d",res);
return 0;
}
单源最短路径(有负权边)
Bellman-Ford算法
我们知道dijsktra算法没有办法处理负权边,自然提出了能够判断负权边的最短路算法。我们需要知道这样一个事实,在n个顶点的图中,任意两个点之间的最短路径最多经过n - 1条边。那么我们可以使用动态规划的思想来求解最短路问题,以及最多经过k个顶点的最短路问题,判断负环问题。
Bellman-Ford算法本质上是一个使用滚动数组优化的动态规划。在第i次迭代后,dist[to]代表的是最多经过i条边到达点的最短距离。
我们首先读入所有的边,这里使用Edges数组存储所有的边,dist数组存储最短路,backup数组作为备份滚动数组。在第i次迭代当中,我们都需要遍历所有的边(from,to),我们判断能够通过这条边使我们到达节点to的距离变小。即状态转移为:
dist[to]=min(dist[to],backup[from]+weight)
其中backup[from]代表了只经过i - 1条边到达from的最短距离。
遍历完成之后,我们需要判断1号点和n号点是否联通,这时候不能直接判断是否等于0x3f3f3f3f,这是因为如果另有一个点p和1号点也不联通,但是和n号点联通,并且dist[p][n] < 0,那么在更新的时候,就会将dist[n]变成一个略小于0x3f3f3f3f的值。
另外,如果没有最大边数限制的话,我们可以不用使用backup数组。
另外,我们可以执行n次迭代,如果第n次迭代,还有一些边的最短路被修改了,说明这时候存在了负环。
时间复杂度分析O(n∗m)
题目链接:https://www.acwing.com/problem/content/description/855/
#include<stdio.h>
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510,M = 10010;
struct edge{
int from,to,weight;
edge(){}
edge(int from,int to,int weight):from(from),to(to),weight(weight){}
}Edges[M];
int dist[N],backup[N];
int main()
{
int n,m,k,from,to,weight;
scanf("%d %d %d",&n,&m,&k);
memset(dist,0x3f,sizeof(dist));
dist[1] = 0;
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
Edges[i] = edge(from,to,weight);
}
for(int i = 0 ; i < k ; i ++)
{
memcpy(backup,dist,sizeof(dist));
for(int j = 0 ; j < m ; j ++)
{
from = Edges[j].from,to = Edges[j].to,weight = Edges[j].weight;
dist[to] = min(dist[to],backup[from] + weight);
}
}
if(dist[n] > 0x3f3f3f3f / 2) printf("impossible");
else printf("%d",dist[n]);
return 0;
}
SPFA(Shortest Path Fast Algorithm)
SPFA其实就是对列优化版本的Bellman-Ford算法,但需要指出的是其平均时间复杂度虽然是O(m),但是其最坏时间复杂度是O(nm),并且出题人喜欢卡这一点。所以也有很多衍生的针对SPFA的优化算法。
SPFA的思路大概如下:
- 使用一个队列来保存待优化的节点。我们使用
state数组标记节点i是否在队列中,初始时只有源点1在队列中。 - 每次取出队列中一个首节点
p,并遍历所有以点p为起点的边e和对应的终点j,如果经过点p到达点j点的路径可以变得更短,那么我们更新dist[j],同时如果节点j不在队列中,并且将j加入队列,这是因为如果到j的最短路径更新了,那么经过j点到其他节点的路径很有可能也要更新。 - 重复上述操作,直至队列为空。
如果我们希望判断图中是否存在负环,我们可以使用一个计数数组,表示从源点到某点最短路中经过的点数。如果该点数大于n那么说明存在负环。
题目链接:https://www.acwing.com/problem/content/description/853/
#include<stdio.h>
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 100010;
int h[N],w[N],e[N],ne[N],idx = 0;
int dist[N];
bool state[N];
void add(int from,int to,int weight)
{
w[idx] = weight;
e[idx] = to;
ne[idx] = h[from];
h[from] = idx ++;
}
int main()
{
int n,m,from,to,weight;
scanf("%d %d",&n,&m);
memset(h,-1,sizeof(h));
memset(dist,0x3f,sizeof(dist));
for(int i = 0 ; i < m; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
add(from,to,weight);
}
queue<int> q;
q.push(1);
dist[1] = 0;
state[1] = true;
while(!q.empty())
{
int p = q.front();
q.pop();
state[p] = false;
for(int i = h[p] ; i != -1 ; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[p] + w[i])
{
dist[j] = dist[p] + w[i];
if(state[j] == false)
{
q.push(j);
state[j] = true;
}
}
}
}
if(dist[n] == 0x3f3f3f3f) printf("impossible");
else printf("%d",dist[n]);
return 0;
}
SPFA求负环
在求解负环的时候,我们使用cnt数组标记从源点到点i的最短路最少要经过多少个点,如果超过了n - 1,那么说明存在负环。另一方面,此时我们不能只把源点放入队列,而应该把所有的点都放入队列,为了防止负环和源点不在一个联通块里面。
#include<stdio.h>
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 100010;
int h[N],w[N],e[N],ne[N],idx = 0;
int n,m,from,to,weight;
int dist[N],cnt[N];
bool state[N];
void add(int from,int to,int weight)
{
w[idx] = weight;
e[idx] = to;
ne[idx] = h[from];
h[from] = idx ++;
}
bool spfa()
{
queue<int> q;
dist[1] = 0;
for(int i = 1 ; i <= n ; i ++)
{
q.push(i);
state[i] = true;
}
while(!q.empty())
{
int p = q.front();
q.pop();
state[p] = false;
for(int i = h[p] ; i != -1 ; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[p] + w[i])
{
cnt[j] = cnt[p] + 1;
if(cnt[j] >= n) return true;
dist[j] = dist[p] + w[i];
if(state[j] == false)
{
q.push(j);
state[j] = true;
}
}
}
}
return false;
}
int main()
{
scanf("%d %d",&n,&m);
memset(h,-1,sizeof(h));
memset(dist,0x3f,sizeof(dist));
for(int i = 0 ; i < m; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
add(from,to,weight);
}
if(spfa()) printf("Yes");
else printf("No");
return 0;
}
多源最短路径算法
Floyd算法
Floyd算法能够处理负权边,但是无法处理有负环的情况。
时间复杂度O(n3),空间复杂度O(n2)。
Floyd算法也是采用了动态规划的思想,在第k次迭代中后,dist[i][j]代表只经过前k个点作为中转,顶点i,j之间的最短距离。
题目链接:https://www.acwing.com/problem/content/description/856/
#include<stdio.h>
#include<cstring>
#include<iostream>
using namespace std;
const int N = 210;
int dist[N][N];
int main()
{
int n,m,k,from,to,weight;
scanf("%d %d %d",&n,&m,&k);
memset(dist,0x3f,sizeof(dist));
for(int i = 1 ; i <= n ; i ++)
dist[i][i] = 0;
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
dist[from][to] = min(weight,dist[from][to]);
}
for(int k = 1 ; k <= n ; k ++)
for(int i = 1 ; i <= n ; i ++)
for(int j = 1 ; j <= n ; j ++)
dist[i][j] = min(dist[i][j],dist[i][k] + dist[k][j]);
for(int i = 0 ; i < k ; i ++)
{
scanf("%d %d",&from,&to);
if(dist[from][to] > 0x3f3f3f3f / 2) printf("impossible\n");
else printf("%d\n",dist[from][to]);
}
return 0;
}
拓扑排序
拓扑排序指的是:对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
拓扑排序的思路非常的直观:
- 统计所有节点的入度,如果某些节点的入度等于0,说明他们不依赖于任何前驱节点,我们将这些节点加入队列。
- 我们依次将队列中的节点取出来,将以该节点为起点的所有边对应的终点的入度减去1。如果此时终点的入度等于0,我们将该节点加入队列。
- 重复执行上述步骤,直至队列为空。如果所有的节点都已经被加入到队列过,就存在一个拓扑排序,并且出队列的顺序就是一个拓扑排序。否则不存在。
题目链接:https://www.acwing.com/problem/content/850/
#include<stdio.h>
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 100010;
int h[N],e[N],ne[N],in_cnt[N],idx = 0;
int n,m,from,to;
int res[N];
void add(int from,int to)
{
e[idx] = to;
ne[idx] = h[from];
h[from] = idx ++;
in_cnt[to] ++;
}
int main()
{
scanf("%d %d",&n,&m);
memset(h,-1,sizeof(h));
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d",&from,&to);
add(from,to);
}
queue<int> q;
for(int i = 1 ; i <= n ; i ++)
if(in_cnt[i] == 0)
q.push(i);
int u = 0;
while(!q.empty())
{
int p = q.front();
q.pop();
res[u ++] = p;
for(int i = h[p] ; i != -1 ; i = ne[i])
{
int j = e[i];
in_cnt[j] --;
if(in_cnt[j] == 0)
q.push(j);
}
}
if(u != n) printf("-1");
else
{
for(int i = 0 ; i < n ; i ++)
printf("%d ",res[i]);
}
return 0;
}
最小生成树算法
最小生成树算法指的是:给定一张边带权的无向图G=(V, E),其中V表示图中点的集合,E表示图中边的集合,n=|V|,m=|E|。
由V中的全部n个顶点和E中n-1条边构成的无向连通子图被称为G的一棵生成树,其中边的权值之和最小的生成树被称为无向图G的最小生成树。
Prim算法
Prim算法的思路如下:
- 初始化点集合Vnew={x},Vold=V−Vnew,x为图中任何一个顶点,初始化所有Vold集合中点y到Vnew的距离为graph(x,y)。
- 在Vold集合中找到距离Vnew距离最小的点t,我们将t加入Vnew,将点t到最小生成树的距离计入答案,如果该距离是inf,说明图不联通,同时使用t点来更新Vold中的点到Vnew的距离。
- 重复上述步骤二n−1次,得到最小生成树。
具体到代码,我们使用visit数组判断节点是否在Vnew集合中。
时间复杂度O(n2),适用于点数比较小,边比较多的稠密图。
题目链接:https://www.acwing.com/problem/content/860/
#include<stdio.h>
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510;
int graph[N][N],dist[N];
bool visit[N];
int n,m,from,to,weight,res = 0,INF = 0x3f3f3f3f;
int prim()
{
// 初始化到V_new的距离
visit[1] = true;;
for(int i = 2 ; i <= n ; i ++)
dist[i] = graph[1][i];
for(int i = 0 ; i < n - 1 ; i ++)
{
// 找到所有V_old中距离V_new最小的点j
int t = -1;
for(int j = 1 ; j <= n ; j ++)
{
if(!visit[j] && (t == -1 || dist[j] < dist[t]))
t = j;
}
// 不联通,直接返回
if(dist[t] == INF) return INF;
// 更新答案,更新距离
res += dist[t];
visit[t] = true;
for(int j = 1 ; j <= n ; j ++)
dist[j] = min(dist[j],graph[t][j]);
}
return res;
}
int main()
{
scanf("%d %d",&n,&m);
memset(graph,0x3f,sizeof(graph));
memset(dist,0x3f,sizeof(dist));
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
graph[from][to] = min(graph[from][to],weight);
graph[to][from] = min(graph[to][from],weight);
}
if(prim() == INF) printf("impossible");
else printf("%d",res);
return 0;
}
Kruskal算法
Kruskal算法和Prim不同的是:Prime算法每次将一个点加入到最小生成树中,而Kruskal算法则是每次选择一条边加入到最小生成树中。Kruskal算法的整体流程如下:
- 将所有的边按照长度从小到大排序。
- 每次选择一条最小的边,且边的两个端点不在同一个联通块中。
- 重复上述步骤二,直至所有的边都被遍历完了。
这里最困难的步骤就是如何判断两个端点是否在同一个联通块中,我们使用并查集来进行判断。
时间复杂度:mlogm
题目链接:https://www.acwing.com/problem/content/description/861/
#include<stdio.h>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010,M = 200010;
struct edge{
int from,to,weight;
edge(){}
edge(int from,int to,int weight):from(from),to(to),weight(weight){}
bool operator< (const edge& b) const
{
return weight < b.weight;
}
}edges[M];
int fa[N],size[N];
int getfa(int x)
{
if(fa[x] != x) fa[x] = getfa(fa[x]);
return fa[x];
}
void uni(int x,int y)
{
if(size[x] < size[y])
{
fa[x] = y;
size[y] += size[x];
}else{
fa[y] = x;
size[x] += size[y];
}
}
int main(){
int n,m,from,to,weight,res = 0,cnt = 0;
scanf("%d %d",&n,&m);
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d %d",&from,&to,&weight);
edges[i] = edge(from,to,weight);
}
sort(edges,edges + m);
for(int i = 1 ; i <= n ; i ++)
{
fa[i] = i;
size[i] = 1;
}
for(int i = 0 ; i < m ; i ++)
{
int x = edges[i].from,y = edges[i].to,weight = edges[i].weight;
int fx = getfa(x),fy = getfa(y);
if(fx != fy)
{
uni(fx,fy);
cnt ++;
res += weight;
}
}
if(cnt < n - 1) printf("impossible");
else printf("%d",res);
return 0;
}
二分图
判断二分图
设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(V1,V2),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集i∈V1,j∈V2,则称图G为一个二分图。
即如果我们能够把图中的所有顶点分成两部分,然后对于任何一条边,他的两个端点都在不同的点集合中。判断二分图的一个等价条件是图中不存在奇数顶点的环。
因此我们可以使用染色法来解决这样的问题,我们每次选取图中一个没有染色的点将其染成颜色1,将其相邻的还没有染色的顶点染成相反的颜色,如果发现相邻的颜色和当前染的颜色相同的话,说明发生了冲突。
我们可以使用BFS或者DFS来完成染色的过程。
题目链接:https://www.acwing.com/problem/content/description/862/
#include<stdio.h>
#include<cstring>
#include<iostream>
#include<queue>
using namespace std;
const int N = 100010,M = 200010;
int h[N],e[M],ne[M],idx = 0;
int st[N];//0代表未染色,1代表颜色1,2代表颜色2
bool res = true;
void add(int from,int to)
{
e[idx] = to;
ne[idx] = h[from];
h[from] = idx ++;
}
bool bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = 1;
while(!q.empty())
{
int p = q.front(),color = st[p],next_color = 3 - color;
q.pop();
for(int i = h[p] ; i != -1 ; i = ne[i])
{
int j = e[i];
if(st[j] == color)
return false;
else if(st[j] == 0)
{
st[j] = next_color;
q.push(j);
}
}
}
return true;
}
bool dfs(int u,int c)
{
st[u] = c;
for(int i = h[u] ; i != -1 ; i = ne[i])
{
int j = e[i];
if(st[j] == c)
return false;
else if(st[j] == 0 && !dfs(j,3 - c))
return false;
}
return true;
}
int main()
{
int n,m,from,to;
scanf("%d %d",&n,&m);
memset(h,-1,sizeof(h));
memset(st,0,sizeof(st));
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d",&from,&to);
add(from,to);
add(to,from);
}
for(int i = 1 ; i <= n ; i ++)
{
if(st[i] == 0)
{
if(dfs(i,1) == false)
{
res = false;
break;
}
}
}
if(res) printf("Yes");
else printf("No");
return 0;
}
二分图最大匹配
二分图的匹配:给定一个二分图G,在G的一个子图M中,M的边集E中的任意两条边都不依附于同一个顶点,则称M是一个匹配。匹配本质上是一个边的集合,且任意两个边没有交点。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
我们这里主要使用匈牙利算法来进行求解,在介绍算法之前,我们需要介绍两个概念:
-
交错路径:给定图G的一个匹配M,如果一条路径的边交替出现在M中和不出现在M中,我们称之为一条M-交错路径。
-
增广路径:而如果一条M-交错路径,它的两个端点都不与M中的边关联,我们称这条路径叫做M-增广路径。
如下图: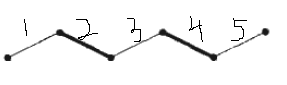
对于匹配M={2,4}其中边集{2,3,4}是一个交错路径,边集{1,2,3,4,5}是一个增广路径。
我们可以发现,对于一个增广路径,我们可以就可以将其中匹配边变成非匹配边,非匹配边变成匹配边。得到一个更大的匹配{1,3,5}。所以我们的目标就转化成在图中不停的找到增广路径。
匈牙利算法
假设我们给定一个二分图,其中点集合分别为X,Y,我们需要为其找到一个最大匹配,我们依次遍历X集合中的顶点。
刚开始,匹配M为空集,我们任意选取一条边(x1,y1),加入到匹配中,得到:
接着我们再选取(x2,y2)加入匹配,得到:
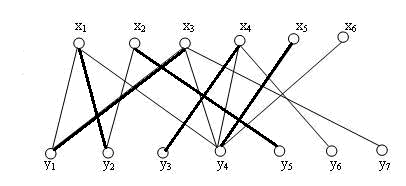
接下来我们希望为x3,找到一个匹配点,我们的算法不是直接让y4分配给他,而是我们先去和y1匹配,这时候(x3,y1),那么x1被孤立了,他则去寻找y2,得到边(x1,y2),这时候x2被孤立了,那么他就去找到y5,组成边(x2,y5)。
我们可以发现,如果可以不断的改变原来的关系,并且之前匹配的一个端点x2能够找到一个非匹配点y5,我们的匹配数就会增加,如果找不多,那么我们的边的大小也能保持不变,只是匹配关系变化了。
因此匈牙利算法的核心在于:不断寻找原有匹配M的增广路径,因为找到一条M匹配的增广路径,就意味着一个更大的匹配M’ , 其恰好比M 多一条边。
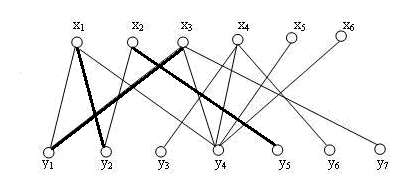
接下来我们依次尝试将后面三个点加入得到一个最大匹配:
题目链接:https://www.acwing.com/problem/content/863/
#include<stdio.h>
#include<cstring>
#include<iostream>
using namespace std;
const int N = 510,M = 100010;
int h[N],e[M],ne[M],idx = 0;//存储点和边
int st[N];//存储当前集合2中的点是否被使用了
int match[N];//存储当前集合2中的点匹配的是集合1中的哪一个点。
int n1,n2,m,from,to,res = 0;
void add(int x,int y)
{
e[idx] = y;
ne[idx] = h[x];
h[x] = idx ++;
}
bool find(int x)
{
// 遍历x的所有边对应的端点j,如果j还没有被使用,那么我们将(x,j)作为匹配中的一条边
// 这时候我们看一下端点j再之前匹配中对应的端点是match[j],如果之前匹配中没有使用过,那么说明可以新加入一条边,直接返回,不然的话我们迫使match[j]去找一个其他的顶点进行匹配。同时要更新match[j] = x,是当前匹配的节点。
for(int i = h[x] ; i != -1 ; i = ne[i])
{
int j = e[i];
if(st[j] == 0)
{
st[j] = 1;
if(match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
int main()
{
scanf("%d %d %d",&n1,&n2,&m);
memset(h,-1,sizeof(h));
for(int i = 0 ; i < m ; i ++)
{
scanf("%d %d",&from,&to);
add(from,to);
}
// 每次为集合1中的点找增广路径的时候,需要清除标记,如果找到了一个增广路径,答案加上1。
for(int i = 1 ; i <= n1 ; i ++)
{
memset(st,0,sizeof(st));
if(find(i)) res ++;
}
printf("%d",res);
return 0;
}
二分图最小顶点覆盖
定义:假如选了一个点就相当于覆盖了以它为端点的所有边。最小顶点覆盖就是选择最少的点来覆盖所有的边。
定理:最小顶点覆盖等于二分图的最大匹配。
二分图最大独立集
定义:选出一些顶点使得这些顶点两两不相邻,则这些点构成的集合称为独立集。找出一个包含顶点数最多的独立集称为最大独立集。
定理:最大独立集 = 所有顶点数 - 最小顶点覆盖 = 所有顶点数 - 最大匹配
参考资料
https://www.acwing.com/blog/content/405/

基于priority_queue的dijkstra算法的时间复杂度是O(mlogm),因为没法直接删掉priority_queue的边,priority_queue中元素最多为m条边。使用手写堆则可以达到O(mlogn),此时可以保证堆中的元素为n个顶点的dist,logn时间内能修改dist和调整堆。
prim的复杂度应该是O(n^2+m)
nice