
个人为了秋招整理一些知识点,理清思路,大佬们发现不对可以指正。
-
地址翻译:
cr3寄存器指向第一级页表的起始位置,是进程上下文的一部分,切换时就更新寄存器值。
以一个Intel Core i7(TLB四路组相联虚拟寻址,L1.L2和L3高速缓冲存储前两者八路组相联后者十六路组相联,物理寻址)地址翻译过程为例:从cpu产生虚拟地址,利用MMU进行地址翻译,其中利用TLB加速地址翻译,以VPN低位作为组索引(VPN的位数取决于内存物理页面的大小),高位作为标记在TLB缓存中查找PPN(也就是说如果利用TLB进行地址翻译就无法对访问权限进行保护),这是建立在命中的情况下,而不命中的话又是另一套流程,从cr3寄存器上获取页表基址,每9位作为每一级页表的选择子,最终定位到表示4K页面的PTE,这其中非叶子节点的PTE内容上面分别是P(是否驻留内存).R/W(所有访问写的读写权限).U/S(可访问的权限用户内核态).WT(写回或者只写策略).A(引用位,内核用这个来设置页替换算法).CD(是否缓存子页表)PS(页面大小为4K或者4M).base addr(子页面的基址).XD(能否从这个PTE可访问的页中取指令)限制只读代码段,使内核降低缓冲区移除的风险,而叶子节点的页表则多了G(标识全局页,页替换时不被从TLB中踢出去)。最终跟VPO(也就是PPO)组合成物理地址进行内存访问。 -
物理页面管理(buddy system)
Linux用伙伴系统管理空闲物理页框,分为11个链表,每个链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续的页框,其中伙伴的定义为两块页框大小相同以及物理地址连续;
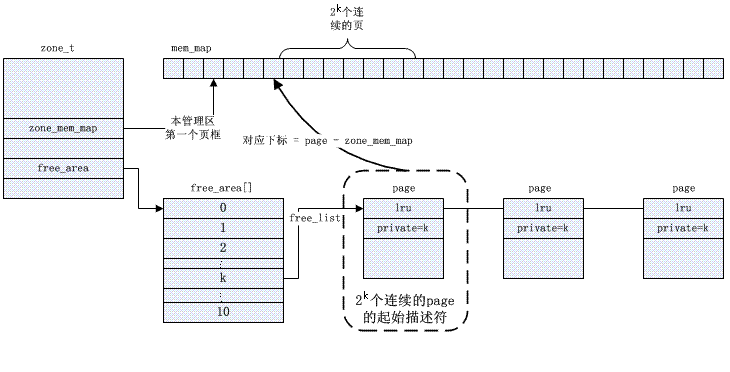
页面分配接口rmqueue_bulk,其中主要流程是在指定的order中free_area上的链表不一定能获得指定的page块,所以会去更大的order中寻找page块,获得page块后将其从所在链表中移除,并清除page上private(标志自己所在order)字段,减少free_area上nr_free计数,减少管理器page数,如果分配order过高,则会产生一些伙伴,就把伙伴放在合适的order里去。需要从order为2的分配,但是order为2的free_area的free_list没有page块了,则去order为3的链表上找,如果此时order为3的链表上也没有空闲page块,则到order为4的链表上去找,如果此时恰巧找到则停止。这样获得了一个有16个page的page块。但是只请求了4个page,此时那些多余的page要放到order为2,order为3的链表上。首先获得size,也就是这里说的16,high为4,low为2。area–也就是获得order为3的那个free_area;high–,此时为3;size>>=1,此时size为8;将刚才那个16个page的page块的后8个page组成块放到order为3的链表上,增加order为3上的块计数。
页释放接口free_pages_bulk:page_idx包含块中的第一个页框的下标,通过有一个位运算算法获得buddy_idx,检查两个page是否是兄弟,然后一次向上合并。 -
slab分配器(内核对象分配)
slab专为小内存分配诞生,基于伙伴分配器来进一步细分小内存分配,以及维护常用对象的缓存,slab对象分为通用slab和专用slab,原因是通用slab会造成内存浪费,slab分配器最后一项任务是提高CPU硬件缓存的利用率。slab从buddy分配器中获取的物理内存称为内存缓存,使用结构struct kmem_cache描述,通过双向链表维系起来,kmem_cache 中所有对象的大小是相同的(object_size),并且此 kmem_cache 中所有SLAB的大小也是相同的。每个缓存节点在内存中维护称为slab的连续页块,这些页面被切成小块,用于缓存数据结构和对象。 kmem_cache的 kmem_cache_node 成员记录了该kmem_cache 下的所有 slabs 列表。形成的结构如下图所示。
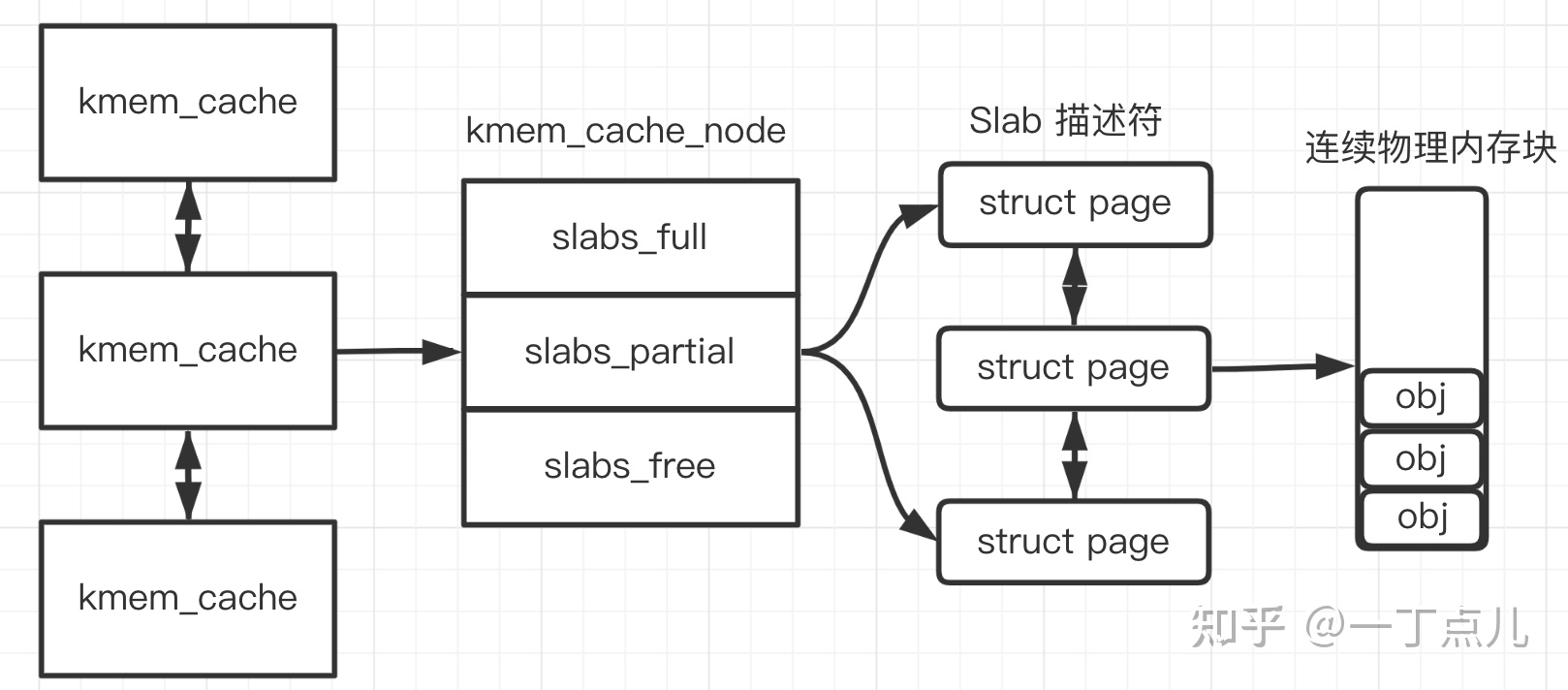
kmem_cache_noed 记录了3种slab:
slabs_full :已经完全分配的 slab
slabs_partial: 部分分配的slab
slabs_free:空slab,或者没有对象被分配
以上3个链表保存的是slab 描述符,Linux kernel 使用 struct page 来描述一个slab。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从 slabs_partial 中被删除,同时插入到 slabs_full 中去。当slab保存在内部时,其描述了一块连续的内存结构,free_list来用描述slab对象的分配状态;在kmem_cache结构体中还有一个成员cpu_cache,其用来为每个cpu维护一个空间链表,能够带起来几个好处:一是提高硬件的缓存的命中率(内核为每个CPU维护一个链表,当需要新对象时,会优先尝试本地CPU空闲链表中获取相应大小的对象),二是减少锁的竞争。该链表初始时为一个空链表,只有释放对象时才会将对象加入这个链表。而在struct kmem_struct_node结构体中同样给存在一个array_cache成员,其构成所有cpu共有的缓存,在此基础上,一个常规对象的申请流是这样的:内核首先会从本地 CPU 空闲对象链表中尝试获取一个对象用于分配:如果失败,则检查所有CPU共享的空闲对象链表链表中是否存在,并且空闲链表中是否存在空闲对象,若有就转移 batchcount 个空闲对象到本地 CPU空闲对象链表中;
如果第 1 步失败,就尝试从 SLAB中分配;这时如果还失败,kmem_cache会尝试从页框分配器中获取一组连续的页框建立一个新的SLAB,然后从新的SLAB中获取一个对象。
而释放流程是:首先会先将对象释放到本地CPU空闲对象链表中,如果本地CPU空闲对象链表中对象过多,kmem_cache 会将本地CPU空闲对象链表中的batchcount个对象移动到所有CPU共享的空闲对象链表链表中, - 如果所有CPU共享的空闲对象链表链表的对象也太多了,kmem_cache也会把所有CPU共享的空闲对象链表链表中batchcount个数的对象移回它们自己所属的SLAB中, - 这时如果SLAB中空闲对象太多,kmem_cache会整理出一些空闲的SLAB,将这些SLAB所占用的页框释放回页框分配器中。(着色机制,kmem_cache设置一个偏移量,让slab对象从内存读入高速缓存时,尽量处于同一行,而同类型的不同slab对象放在高速缓存的不同行里,依次降低内存交换率) -
缺页中断处理
先来说下用户态和内核态的过程:
先调整esp和eip指针,使其指向内核栈,eax上的系统调用号入栈,然后save_all(保存通用寄存器fs.es.ds.eax.ebp.edi.esi.edx.ecx.ebx等)切换成功。
缺页中断处理过程:上面的过程发生后,通过硬件寄存器或者ip寄存器获得正在访问的虚拟地址,对其合法性进行检验(内存地址是否在vm_start和vm_end之间,进程状态是否有操作页面权限),查找是否有空闲页框,没有空闲页框通过页面置换算法来淘汰一个页面,淘汰页面如果存在脏读就安排写回磁盘,中间可以挂起进程,一旦页框干净后,就通过pte上面的磁盘地址进行写入,磁盘中断发生时,表明页表可以反应位置, 返回调用例程恢复寄存器,再通过iret指令返回用户态。
页面置换算法:LRU算法
