
题目描述
给定一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n - 1 的 n 个节点组成,且恰好有 n - 1 条 edges。树的根节点为节点 0,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点的标签就是 labels[i])。
边数组 edges 以 edges[i] = [a_i, b_i] 的形式给出,该格式表示节点 a_i 和 b_i 之间存在一条边。
返回一个大小为 n 的数组,其中 ans[i] 表示第 i 个节点的子树中与节点 i 标签相同的节点数。
树 T 中的子树是由 T 中的某个节点及其所有后代节点组成的树。
样例
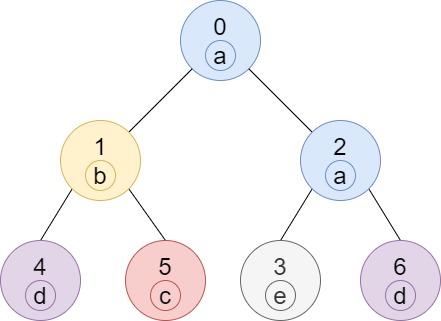
输入:n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd"
输出:[2,1,1,1,1,1,1]
解释:节点 0 的标签为 'a',以 'a' 为根节点的子树中,节点 2 的标签也是 'a',因此答案为 2。
注意树中的每个节点都是这棵子树的一部分。
节点 1 的标签为 'b',节点 1 的子树包含节点 1、4 和 5,
但是节点 4、5 的标签与节点 1 不同,故而答案为 1(即,该节点本身)。
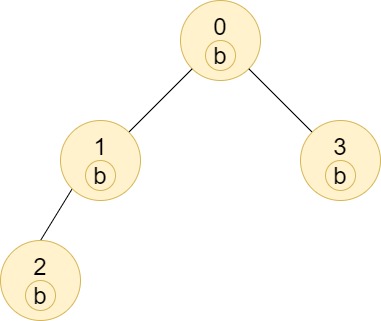
输入:n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb"
输出:[4,2,1,1]
解释:节点 2 的子树中只有节点 2,所以答案为 1。
节点 3 的子树中只有节点 3,所以答案为 1 。
节点 1 的子树中包含节点 1 和 2,标签都是 'b',因此答案为 2。
节点 0 的子树中包含节点 0、1、2 和 3,标签都是 'b',因此答案为 4。
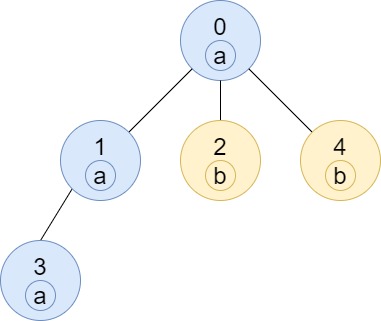
输入:n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab"
输出:[3,2,1,1,1]
输入:n = 6, edges = [[0,1],[0,2],[1,3],[3,4],[4,5]], labels = "cbabaa"
输出:[1,2,1,1,2,1]
输入:n = 7, edges = [[0,1],[1,2],[2,3],[3,4],[4,5],[5,6]], labels = "aaabaaa"
输出:[6,5,4,1,3,2,1]
限制
1 <= n <= 10^5edges.length == n - 1edges[i].length == 20 <= a_i, b_i < na_i != b_ilabels.length == nlabels仅由小写英文字母组成。
算法
(深度优先遍历) O(n)
- 深度优先遍历整棵树,先递归子节点,然后用子节点的信息来更新当前节点。
时间复杂度
- 每个节点仅访问一次,访问时遍历 26 个字母,故总时间复杂度为 O(n)。
空间复杂度
- 需要 O(n) 的额外空间存储邻接表,每个节点的信息以及答案。
C++ 代码
class Solution {
private:
vector<vector<int>> totLabels;
void solve(int u, int fa, const vector<vector<int>> &graph) {
for (int v : graph[u])
if (v != fa) {
solve(v, u, graph);
for (int i = 0; i < 26; i++)
totLabels[u][i] += totLabels[v][i];
}
}
public:
vector<int> countSubTrees(int n, vector<vector<int>>& edges, string labels) {
vector<vector<int>> graph(n);
for (const auto &e : edges) {
graph[e[0]].push_back(e[1]);
graph[e[1]].push_back(e[0]);
}
totLabels.resize(n, vector<int>(26, 0));
for (int i = 0; i < n; i++)
totLabels[i][labels[i] - 'a']++;
solve(0, -1, graph);
vector<int> ans(n);
for (int i = 0; i < n; i++)
ans[i] = totLabels[i][labels[i] - 'a'];
return ans;
}
};
