
题目描述
给定一个包含 n 个点 m 条边的有向图,并给定每条边的容量,边的容量非负。
图中可能存在重边和自环。求从点 S 到点 T 的最大流。
输入格式
第一行包含四个整数 n,m,S,T。
接下来 m 行,每行三个整数 u,v,c,表示从点 u 到点 v 存在一条有向边,容量为 c。
点的编号从 1 到 n。
输出格式
输出点 S 到点 T 的最大流。
如果从点 S 无法到达点 T 则输出 0。
数据范围
2≤n≤1000,
1≤m≤10000,
0≤c≤10000,
S≠T
输入样例:
7 14 1 7
1 2 5
1 3 6
1 4 5
2 3 2
2 5 3
3 2 2
3 4 3
3 5 3
3 6 7
4 6 5
5 6 1
6 5 1
5 7 8
6 7 7
输出样例:
14
算法1
由于个人习惯 没有使用前式链向星
但是想用stl替换这么经典的记录方案 着实叫人头痛
这里使用了.
const int N = 10010;
const int M = 20010;
set<int> g[N];
数组来记录 点之间的联系
使用map 来记录点之间的权值 方便查找
主要原理还是同Y总视频一样 稍后配调整步骤图
建立残余网络(有反向路径) 然后不停的BFS寻找起点到终点的增广路,如果存在增广路就说明
1起点终点之间的流量有改进余地, 那么调整路径流量
( 起点到终点减少流量表示该流量已经使用,但是反向路径会增加,表示可以调整该路径上的流量,可以返悔减少)
2 调整的额度 使找到的整个路径上每条边的最小可调整额度决定的
如图
假设有这么一个输入数据图
4 5 1 4
1 2 40
1 4 20
2 4 20
2 3 30
3 4 10
//==============
50
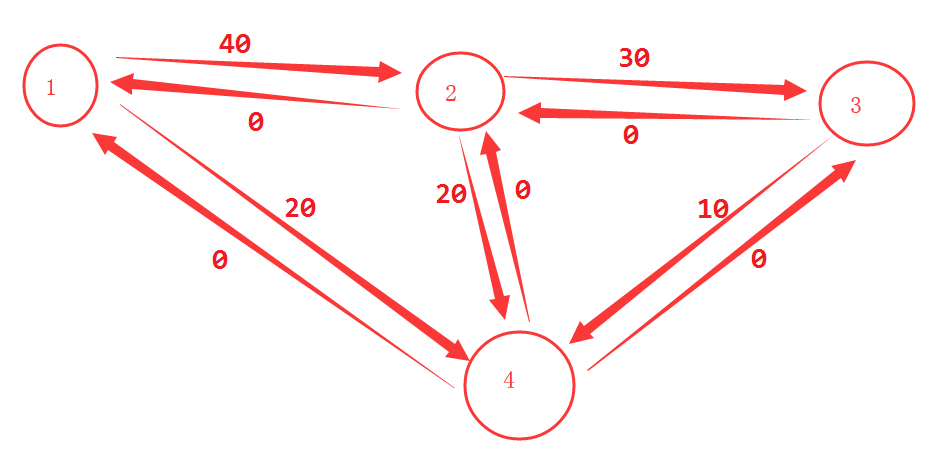
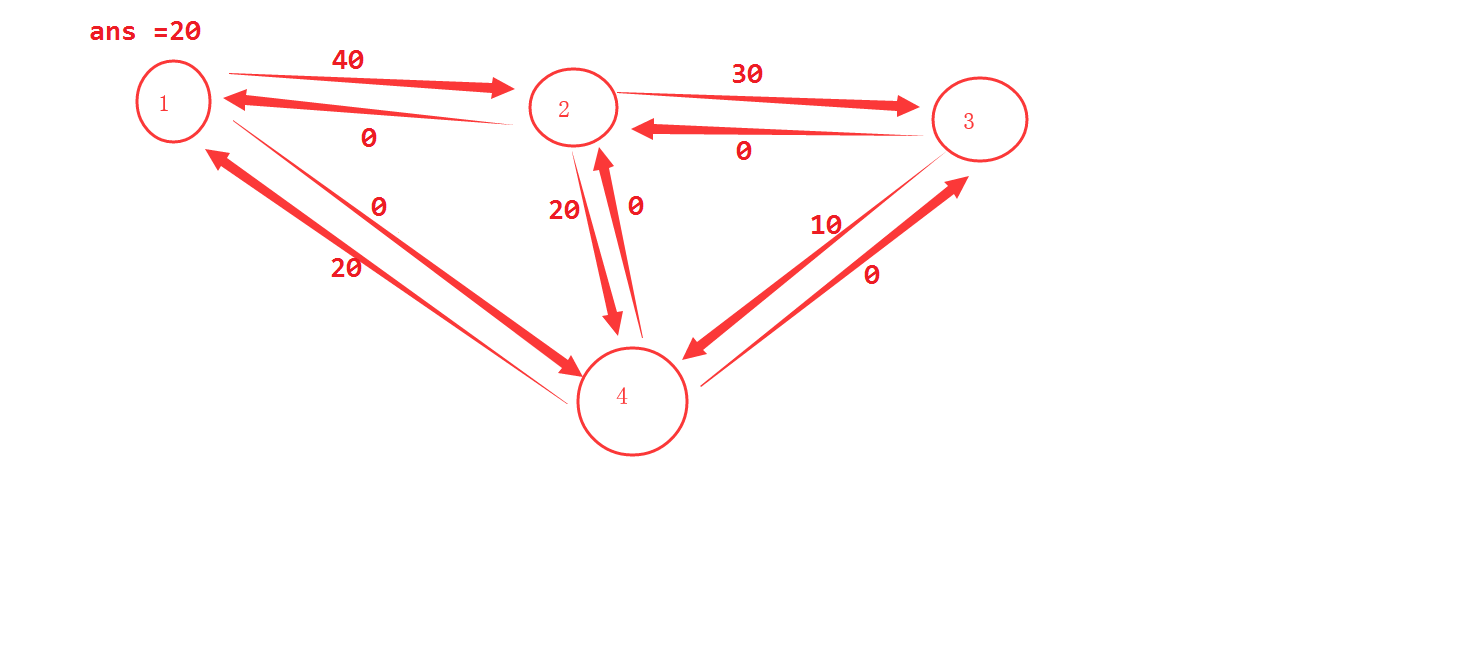
然后找到1条增广路径 1-4 流量调整额度为20
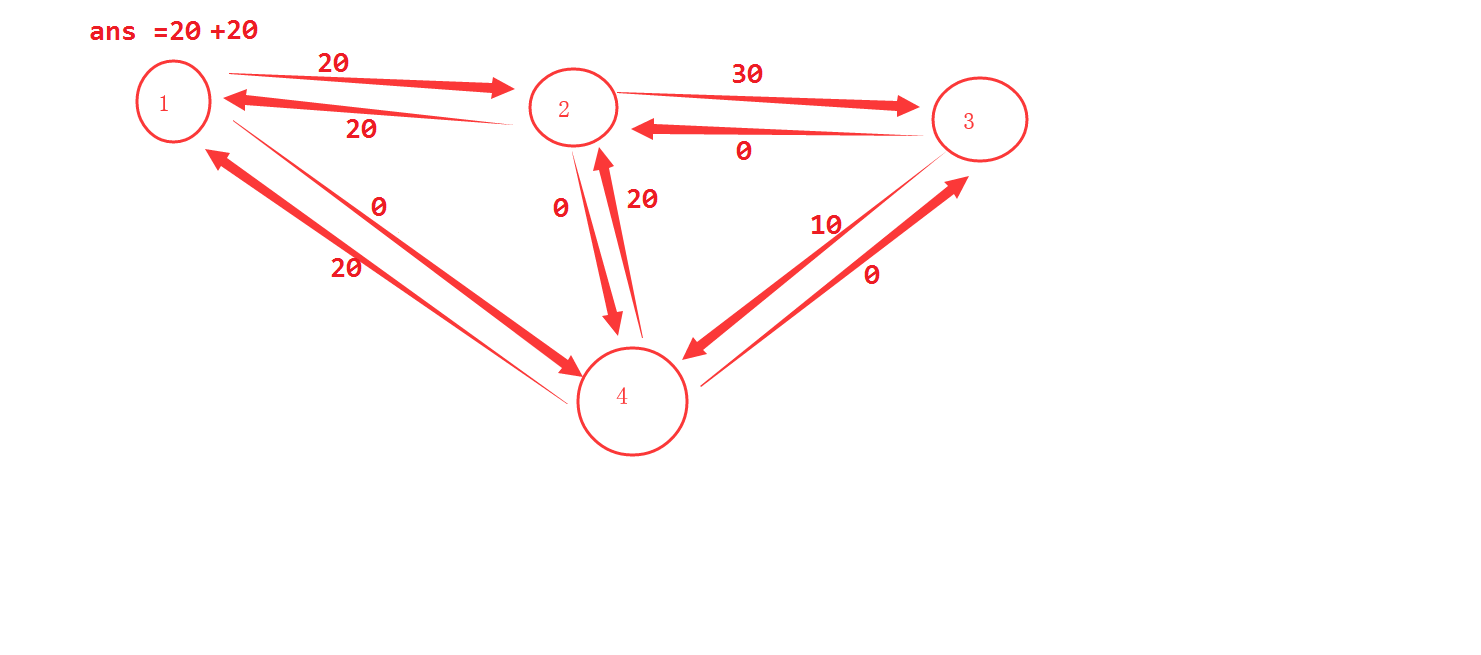
在找到1条增广路 1-2-4 流量调整额度为20
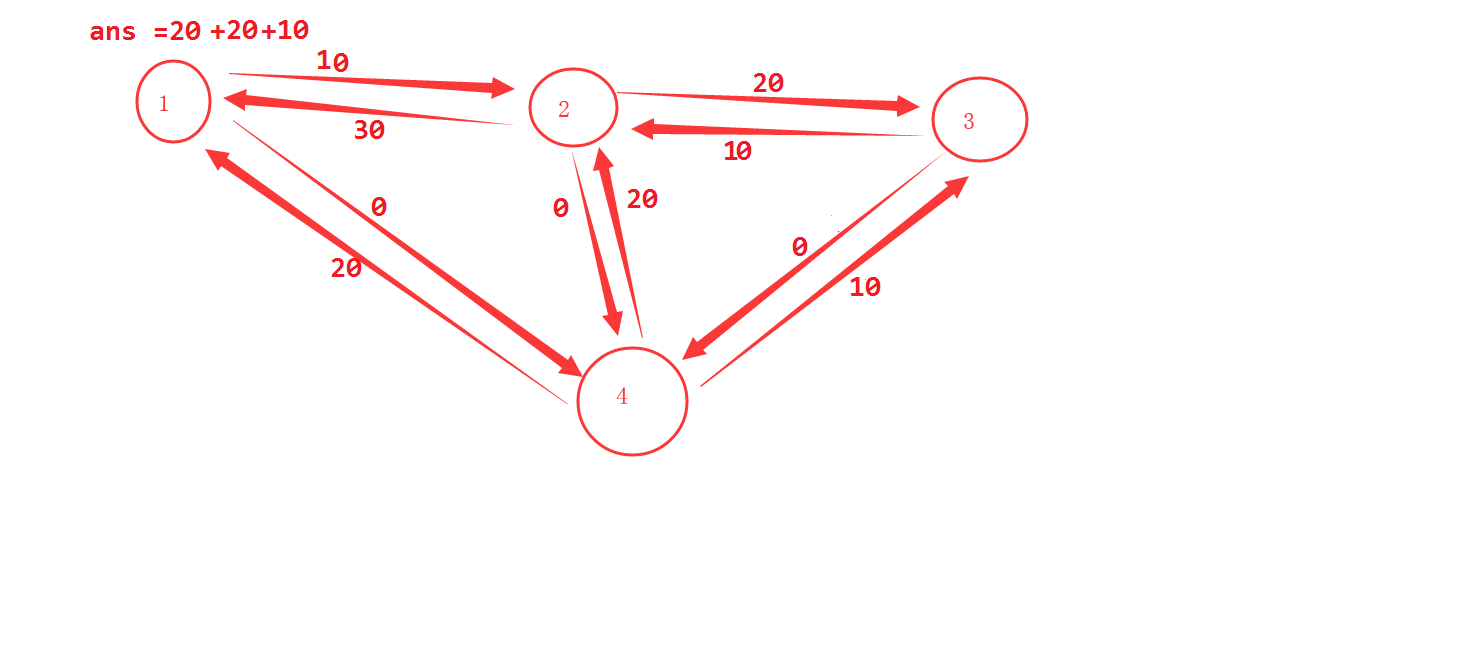
最后1条增广路 流量调整额度10
C++ 代码
// 11135.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <queue>
#include <memory.h>
#include <map>
#include <unordered_set>
using namespace std;
/*
给定一个包含 n 个点 m 条边的有向图,并给定每条边的容量,边的容量非负。
图中可能存在重边和自环。求从点 S 到点 T 的最大流。
输入格式
第一行包含四个整数 n,m,S,T。
接下来 m 行,每行三个整数 u,v,c,表示从点 u 到点 v 存在一条有向边,容量为 c。
点的编号从 1 到 n。
输出格式
输出点 S 到点 T 的最大流。
如果从点 S 无法到达点 T 则输出 0。
数据范围
2≤n≤1000,
1≤m≤10000,
0≤c≤10000,
S≠T
输入样例:
7 14 1 7
1 2 5
1 3 6
1 4 5
2 3 2
2 5 3
3 2 2
3 4 3
3 5 3
3 6 7
4 6 5
5 6 1
6 5 1
5 7 8
6 7 7
输出样例:
14
*/
/*
4 5 1 4
1 2 40
1 4 20
2 4 20
2 3 30
3 4 10
//==============
50
*/
const int N = 10010;
const int M = 20010;
map<pair<int, int>, int> graphW;
unordered_set<int> g[N];
int n, m;
int S, T;
int ans = 0;
int d[N];
int pre[N];
int st[N];
void addEdge(int from, int to, int flow)
{
//数组记录两点之间的关系 使用哈希记录两点之间的流 加速查找
pair<int, int> p1 = make_pair(from, to);
graphW[p1] += flow;
pair<int, int> p2 = make_pair(to, from);
graphW[p2] += 0;
g[from].insert(to);
g[to].insert(from);
}
bool bfs()
{
memset(st, 0, sizeof(st));
queue<int> q;
q.push(S);
st[S] = 1;
d[S] = 100000010;
while (q.size()) {
int t = q.front(); q.pop();
for (auto ver : g[t]) {
pair<int, int> edge = make_pair(t,ver);
int f = graphW[edge];
if (!st[ver] && f) {
st[ver] = 1;
d[ver] = min(d[t], f);
pre[ver] = t;
if (ver == T) return true;
q.push(ver);
}
}
}
return false;
}
int main()
{
cin >> n >> m >> S >> T;
for (int i = 0; i < m; i++) {
int a, b, w;
cin >> a >> b >> w;
addEdge(a, b, w);
}
while (bfs())
{
ans += d[T];
int from = T; int to = pre[from];
while (1) {
pair<int, int> E = make_pair(from, to);
pair<int, int> revE = make_pair(to, from);
graphW[E] += d[T];
graphW[revE] -= d[T];
if (to == S) break;
from = to; to = pre[from];
}
}
cout << ans << endl;
return 0;
}
耗时1000ms 估计快TLE了 但是能AC
结论是使用其他方案加深印象可以 但是实际追求效率的话 STL不太适合
=============================================================
在贴一个Y总的标答
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1010, M = 20010, INF = 1e8;
int n, m, S, T;
int h[N], e[M], f[M], ne[M], idx;
int q[N], d[N], pre[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, f[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
e[idx] = a, f[idx] = 0, ne[idx] = h[b], h[b] = idx ++ ;
}
bool bfs()
{
int hh = 0, tt = 0;
memset(st, false, sizeof st);
q[0] = S, st[S] = true, d[S] = INF;
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = h[t]; ~i; i = ne[i])
{
int ver = e[i];
if (!st[ver] && f[i])
{
st[ver] = true;
d[ver] = min(d[t], f[i]);
pre[ver] = i;
if (ver == T) return true;
q[ ++ tt] = ver;
}
}
}
return false;
}
int EK()
{
int r = 0;
while (bfs())
{
r += d[T];
for (int i = T; i != S; i = e[pre[i] ^ 1])
f[pre[i]] -= d[T], f[pre[i] ^ 1] += d[T];
}
return r;
}
int main()
{
scanf("%d%d%d%d", &n, &m, &S, &T);
memset(h, -1, sizeof h);
while (m -- )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
printf("%d\n", EK());
return 0;
}

实际上
map<pair<int, int>, int> graphW的增删改查都是O(logn)的,而且stl套stl常数会比较大$QwQ$可以考虑改成
unordered_map<int,int>graphW[N]是的 都是用unordered_set了, map应该也修改成哈希模式的
# %%%orz