
835. Trie字符串统计
维护一个字符串集合,支持两种操作:
“I x”向集合中插入一个字符串x;
“Q x”询问一个字符串在集合中出现了多少次。
共有N个操作,输入的字符串总长度不超过 105,字符串仅包含小写英文字母。
输入格式
第一行包含整数N,表示操作数。
接下来N行,每行包含一个操作指令,指令为”I x”或”Q x”中的一种。
输出格式
对于每个询问指令”Q x”,都要输出一个整数作为结果,表示x在集合中出现的次数。
每个结果占一行。
数据范围
1≤N≤2∗104
输入样例:
5
I abc
Q abc
Q ab
I ab
Q ab
输出样例:
1
0
1
具体分析
此分析就是根据y总视频来的
定义:高效地存储和查找字符串集合的数据结构 详细内容可以参考 百度百科
例如:
插入
abcdef
abdef
aced
bcdf
bcff
cdaa
bcdc
abc
1.首先插入abcdef
先判断根节点有没有a这个点作为子节点,没有就创建出来,以此类推,再从a往下走,判断a有没有b这个子节点,没有就创建出来,以此类推,把剩下的插入进来,(存的时候会在结尾的单词后面打上一个标记,表示在这个字母结尾是有一个的单词的)如图:
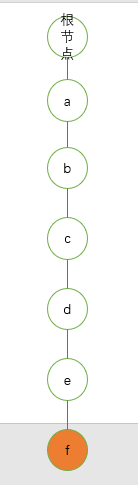
2.依次插入其余字符串
最终图为:
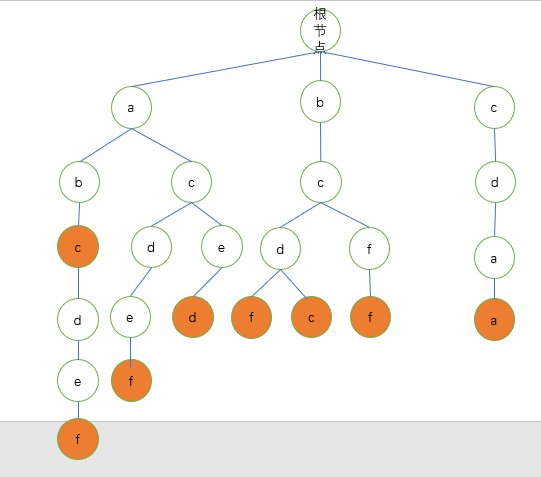
代码里面已经有所有逻辑分析了,所以就不多做解释了
具体代码
import java.util.Scanner;
public class Main {
private static int N=100010;
private static int son[][]=new int[N][26];//Trie树中每个节点的所有儿子
private static int cnt[]=new int[N];//以当前这个点结尾的单词有多少个
private static char str[]=new char[N];
private static int idx;//当前用的的哪个下标,下标0:既是根节点又是空节点
public static void main(String[] args){
Scanner scanner=new Scanner(System.in);
int n=scanner.nextInt();
while (n-->0){
String op=scanner.next();
String str=scanner.next();
if("I".equals(op)){
insert(str.toCharArray());
}else if("Q".equals(op)){
System.out.println(query(str.toCharArray()));
}
}
}
//插入
private static void insert(char[] str) {
int p=0;//根节点是0
//从根节点开始,从前向后遍历字符串
for(int i=0;i<str.length ;i++){
int u=str[i]-'a';//把当前这个字母对应的子节点编号搞出来
//如果当前这个点上不存在对应的字母的话,创建出来
if(son[p][u]==0) son[p][u]=++idx;
p=son[p][u];//走到下一个点
}
cnt[p]++;//p对应的点就是最后一个点,cnt[p]++表示以这个点结尾的单词数量加1
}
//查找字符串出现的次数
private static int query(char[] str) {
int p=0;
for(int i=0;i<str.length;i++){
int u=str[i]-'a';
//如果不存在这个子节点的话,说明集合中不存在这个单词
if(son[p][u]==0) return 0;
//否则的话走过去
p=son[p][u];
}
return cnt[p];//返回以p结尾的单词数量
}
}

N为什么是100010,而不可以是20010?N不是<=2 * (10的4次方)么
因为字符串长度是100000
private static char str[]=new char[N];这个好象没用到
注释的针不错