
from typing import List
from collections import deque
INF = 0x7fffffffffffffff
class FortdFulkerson:
# 输入图中所有边列表[(from1, to1, weight1), (form2, to2, weight2), ......]
# 边可以有重边和自环边
# souece_node 和 end_node 分别为源点和汇点
# 所有节点从1开始连续编号, max_node_num是最大节点数,max_edge_nums是最大边数
def __init__(self, edges, source_node, end_node, max_node_num, max_edge_num):
self.edges = edges[::]
self.source_node = source_node
self.end_node = end_node
self.max_edge_num = max_edge_num
self.max_node_num = max_node_num
#返回整个图的最大流和每条边的流量以及容量,(max_flow, [(from1, to1, flow1, weight1), (from1, to1, flow1, weight1), ......])
def Dinic(self, rev_edge_w = None): # rev_edge_w是反向边边权,默认都是0
e = [-1] * (self.max_edge_num*2 + 1) # e[idx]表示编号为idx残量图边的终点, idx//2 就是残量图边对应的原图边的编号
f = [-1] * (self.max_edge_num*2 + 1) # f[idx]表示编号为idx的残量图边的流量
ne = [-1] * (self.max_edge_num*2 + 1) # ne[idx]表示根编号为idx的边同一个起点的下一条边的编号
h = [-1] * (self.max_node_num + 1) # h[a]表示节点a为起点的所有边的链表头对应的边的编号
dis = [-1] * (self.max_node_num + 1) # dis[a]表示点a到源点的距离,用于记录分层图信息
cur = [-1] * (self.max_node_num + 1) # cur[a]表示节点a在dfs搜索中第一次开始搜索的边的下标,也称当前弧,用于优化dfs速度
orig_flow = [0] * (self.max_edge_num + 1) # 原图中有向边的流量
idx = 0
for i, (a, b, w) in enumerate(self.edges):
e[idx], f[idx], ne[idx], h[a] = b, w, h[a], idx
idx += 1
e[idx], f[idx], ne[idx], h[b] = a, 0, h[b], idx
if rev_edge_w is not None:
f[idx] = rev_edge_w[i]
idx += 1
# bfs搜索有没有增广路
def bfs() -> bool:
for i in range(self.max_node_num + 1):
dis[i] = -1
que = deque()
que.append(self.source_node)
dis[self.source_node] = 0
cur[self.source_node] = h[self.source_node]
while len(que) > 0:
cur_node = que.popleft()
idx = h[cur_node]
while idx != -1:
next_node = e[idx]
if dis[next_node] == -1 and f[idx] > 0:
dis[next_node] = dis[cur_node] + 1
cur[next_node] = h[next_node]
if next_node == self.end_node:
return True
que.append(next_node)
idx = ne[idx]
return False
# dfs查找增广路, 返回当前残量图上node节点能流入汇点的不超过limit的最大流量有多事少
def dfs(node, limit) -> int:
if node == self.end_node:
return limit
flow = 0
idx = cur[node] # 从节点的当前弧开始搜索下一个点
while idx != -1 and flow < limit:
# 当前弧优化,记录每一个节点最后走的一条边,只要limit还没有减成0,已经搜过的边的终点
# 能够汇入汇点的流量就已经全部用完了,另外一条路径到同一个点时候没必要重复搜索已经不会
# 再提供流量贡献的邻接点
cur[node] = idx
next_node = e[idx]
if dis[next_node] == dis[node]+1 and f[idx] > 0:
t = dfs(next_node, min(f[idx], limit - flow))
if t == 0:
# 已经无法提供流量的废点闪删除掉,不再参与搜索
dis[next_node] = -1
# 更新残量图边的流量
f[idx], f[idx^1], flow = f[idx]-t, f[idx^1]+t, flow+t
# 更新原图边的流量
if self.edges[idx>>1][0] == node:
orig_flow[idx>>1] += t
else:
orig_flow[idx>>1] -= t
idx = ne[idx]
return flow
max_flow = 0
while bfs():
# 只要还有增广路,就dfs把增广路都找到,把增广路上的流量加到可行流上
max_flow += dfs(self.source_node, INF)
return max_flow, [(self.edges[i][0], self.edges[i][1], orig_flow[i], self.edges[i][2]) for i in range(len(self.edges))]
class MergeSetExt:
def __init__(self, max_key_val = 0, trans_key_func=None):
if trans_key_func is not None and max_key_val > 0:
# 如果能够提供转换key的回调,并查集内部用线性表存储
self.trans_key_callback = trans_key_func
self.m = [-1 for _ in range(max_key_val+1)]
self.__root2cluster_size = [0 for _ in range(max_key_val+1)]
else:
# 如果不能提供转换key的回调,并查集内部用hash表存储
self.trans_key_callback = None
self.m = {}
self.__root2cluster_size = {}
self.__root_cnt = 0
def getRoot(self, node):
buf = []
root = self.trans_key_callback(node) if self.trans_key_callback else node
while self.m[root] != root:
buf.append(root)
root = self.m[root]
for key in buf:
self.m[key] = root
return root
def merge(self, a, b):
orig_a, orig_b = a, b
if self.trans_key_callback:
a, b = self.trans_key_callback(a), self.trans_key_callback(b)
for node in [a, b]:
if (self.trans_key_callback is None and node not in self.m) or (self.trans_key_callback is not None and self.m[node] == -1):
self.m[node] = node
self.__root2cluster_size[node] = 1
self.__root_cnt += 1
root1 = self.getRoot(orig_a)
root2 = self.getRoot(orig_b)
if root1 != root2:
self.m[root1] = root2
self.__root2cluster_size[root2] += self.__root2cluster_size[root1]
if self.trans_key_callback:
self.__root2cluster_size[root1] = 0
else:
self.__root2cluster_size.pop(root1)
self.__root_cnt -= 1
def isInSameSet(self, a, b):
if a == b:
return True
orig_a, orig_b = a, b
if self.trans_key_callback:
a, b = self.trans_key_callback(a), self.trans_key_callback(b)
for node in [a, b]:
if self.m[node] == -1:
return False
else:
for node in [orig_a, orig_b]:
if node not in self.m:
return False
return self.getRoot(orig_a) == self.getRoot(orig_b)
n, m, k = map(int, input().split())
H = [0] * m # H[i]是编号是i的飞船的容量
P = [] # P[i]是编号是i的飞船的路线中的位置列表
for i in range(m):
arr = list(map(int, input().split()))
H[i] = arr[0]
P.append(arr[2:])
merge_set = MergeSetExt(n+2, lambda x: x)
for p in P:
last_val = None
for i, val in enumerate(p):
if val == 0:
val = n+1
elif val == -1:
p[i] = n+1 # 月球的编号换成n+1, 方便后面建图
val = n+2
if last_val is not None:
merge_set.merge(last_val, val)
last_val = val
if not merge_set.isInSameSet(n+1, n+2):
# 地球和月球不可达
print(0)
else:
# <i, j>二元组转换成节点编号
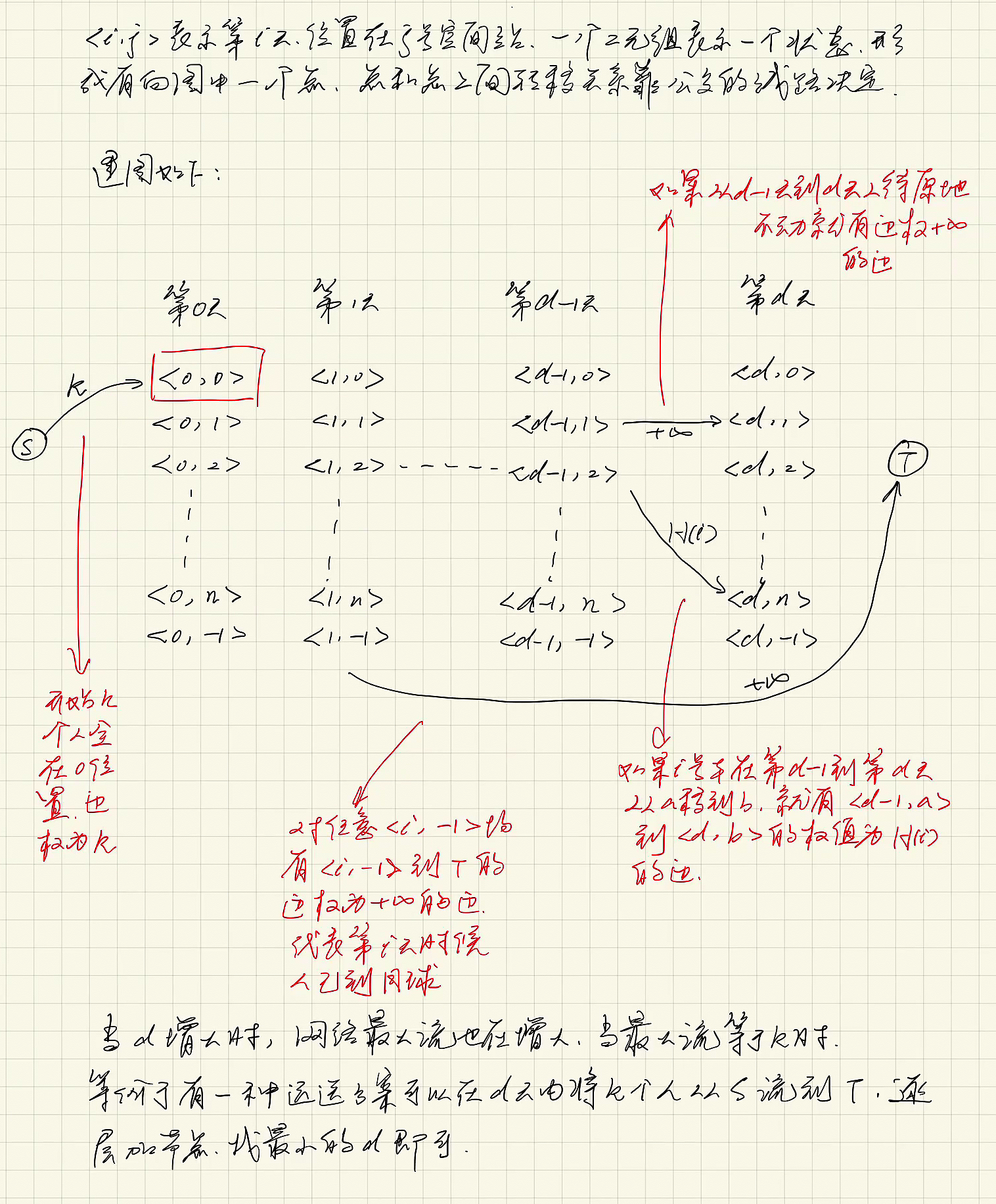
def pos2idx(i, j):
return 3 + (i * (n+2)) + j
S, T = 1, 2
d = 0
edges = []
f = [] # f[idx]是编号是idx的边已经用掉的流量
total_flow = 0
while True:
if d == 0:
edges.append((S, pos2idx(0, 0), k))
f.append(0)
else:
for j in range(0, n+2):
edges.append((pos2idx(d-1, j), pos2idx(d, j), INF))
f.append(0)
edges.append((pos2idx(d, n+1), T, INF))
f.append(0)
for i, p in enumerate(P):
last_pos = p[(d-1) % len(p)]
cur_pos = p[d % len(p)]
edges.append((pos2idx(d-1, last_pos), pos2idx(d, cur_pos), H[i]))
f.append(0)
e = [(a, b, w-f) for (a, b, w), f in zip(edges, f)]
max_flow, new_edges = FortdFulkerson(e, S, T, (d+1)*(n+2)+2, len(e)).Dinic(rev_edge_w=f)
total_flow += max_flow
if total_flow == k:
print(d)
break
new_f = [flow for _, _, flow, _ in new_edges]
for i, val in enumerate(f):
new_f[i] += f[i]
f = new_f
d += 1

题解写的真的很好,看懂了,谢谢
难受