
题目描述
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。账户本身可以以任意顺序返回
样例
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"],
["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com",
"john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
输出:
[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'],
["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
算法1
(并查集 + 哈希表) $O(nlogn)$
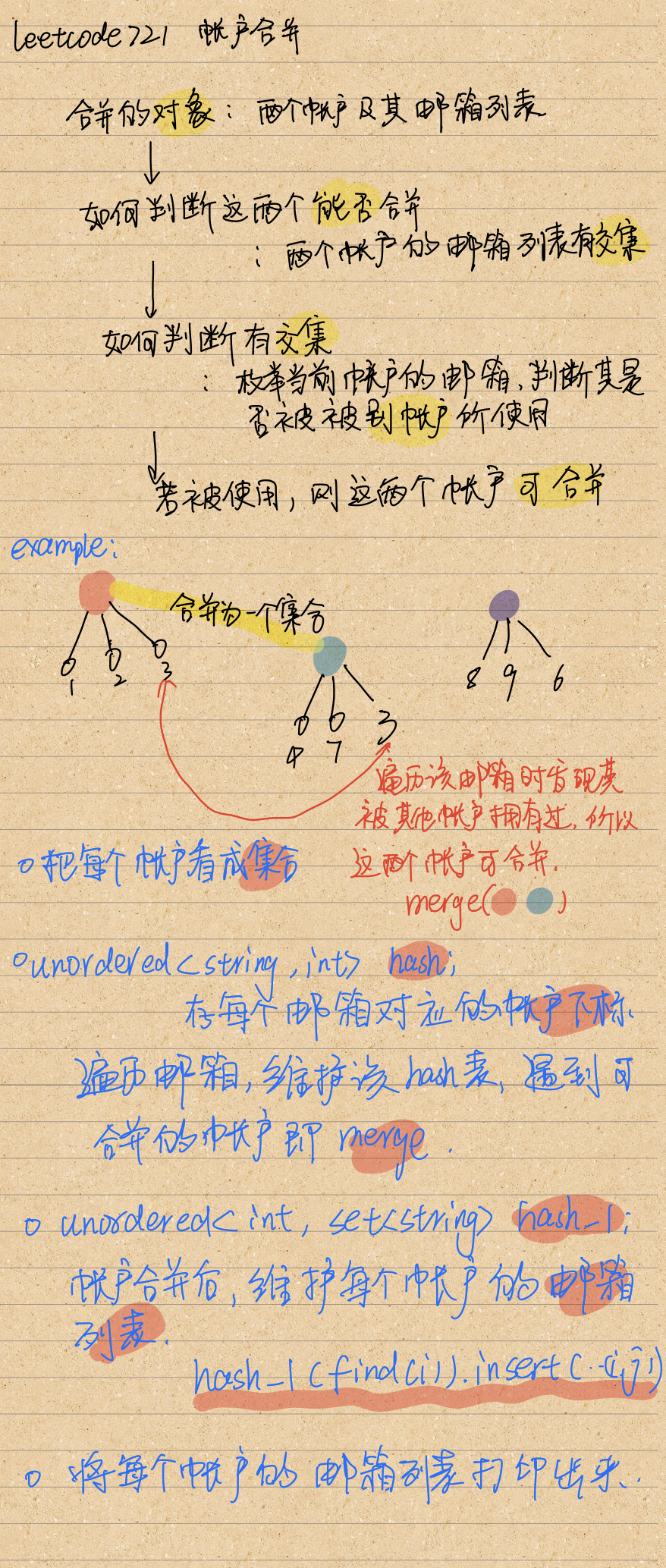
- 每个账户看成一个
集合 - 集合
合并的条件为, 两个集合有共同的邮箱- 因此,问题转为
如何判断其有共同的邮箱- 用哈希表存每个邮箱对应的账号,
- 维护该哈希表的时候,发现当前邮箱已经有账号在使用,那么
当前邮箱对应的账号和哈希表中该邮箱对应的账号可以合并
- 因此,问题转为
-
集合合并后,对应邮箱结果的输出
- 用哈希表来存合并后的
每个集合的邮箱列表,因为要求有序,所以用set<string>来存 - 遍历邮箱,维护该哈希表
- 用哈希表来存合并后的
-
账户直接用
string的话可能会重复,所以这里用下标索引来表示
时间复杂度
假设初始账号有n个,邮箱总数目为m个
并查集
- 查找 单次 $o(logn)$
- 在维护hash_1的时候查找祖先 $o(nlogn)$
- 合并 单次 $o(logn)$
- 在维护hash的时候需要合并,之多合并n-1次 $o((n-1)*logn)$
哈希表
- 维护hash的时候查找邮箱所属账户 $o(m)$
- 维护hash_1的时候set排序
- $o(n*(m/n)logn(m/n)$,
- 即 $o(m*logn(m/n))$
m/n每个账户的平均邮箱个数
时间复杂度 :$o((n-1)*logn+m+nlogn+m*log(m/n))$ -> $o(nlogn)$
空间复杂度 : $o(m)$ 每个邮箱对应的账号 + $o(m - 重复邮箱)$ 每个账户对应的邮箱
C++ 代码
class Solution {
public:
vector<int> p, cnt;
void init(int n){
for(int i = 0; i < n ; i ++){
p[i] = i;
cnt[i] = 1;
}
}
int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
void merge(int x, int y){
int a = find(x), b = find(y);
if(a != b){
if(cnt[a] < cnt[b]){
p[a] = b;
cnt[b] += cnt[a];
}else{
p[b] = a;
cnt[a] += cnt[b];
}
}
}
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
int n = accounts.size();
p.resize(n);
cnt.resize(n);
init(n);
unordered_map<string, int> hash; // 账户 -> 人(索引)
for(int i = 0; i < n; i ++)
for(int j = 1; j < accounts[i].size(); j ++){
if(hash.find(accounts[i][j]) == hash.end())
hash[accounts[i][j]] = i;
else
merge(hash[accounts[i][j]], i); // 这个账户被已经有主了,合并
// 两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。
}
unordered_map<int, set<string>> hash_1; // 人 -> 账户(去重 且 有序
for(int i = 0; i < n; i ++)
for(int j = 1; j < accounts[i].size(); j ++)
hash_1[find(i)].insert(accounts[i][j]);
vector<vector<string>> res;
for(auto &[id, emails] : hash_1)
{
vector<string> path;
path.push_back(accounts[id][0]);
for(auto &email : emails) path.push_back(email);
res.push_back(path);
}
return res;
}
};
