
1414. 牛异或 【01字典树】(C++版本)
标准字典树

01字典树
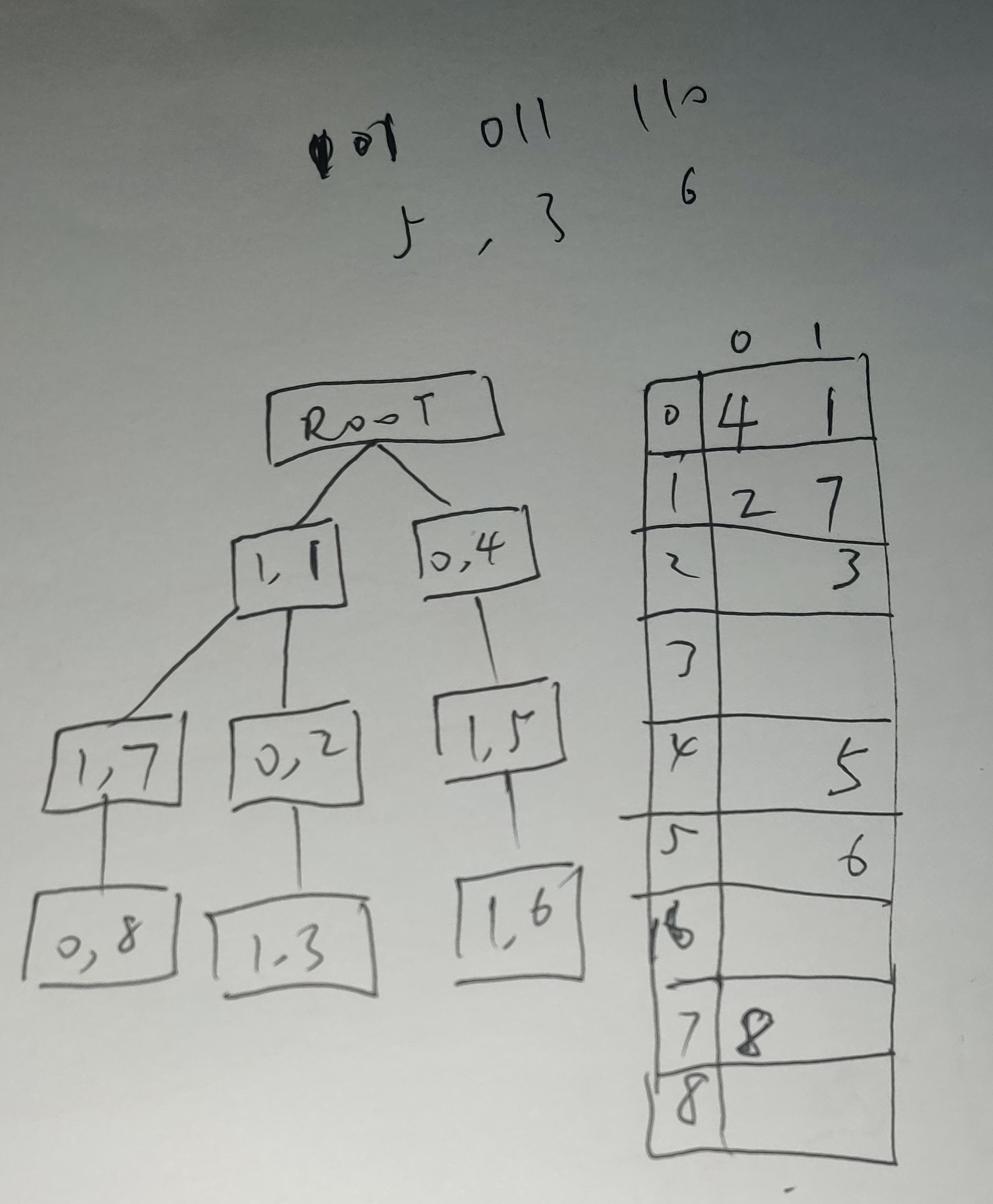
01字典树前缀和过程
核心要点
1. 思路:区间异或最大值 <– 前缀和中找两个最大
2. 时间复杂度【O(n)】
-
单趟遍历建树:O(n * h),h是建树高度,由于数据小于$2^{21}-1$,所以树高可以设置为21。
-
每个结点根据01字典树查找最大的异或值,O(n*h)。
-
所以总共时间复杂度就是O(n)。
3. 代码细节
- 【边界处理】需要处理一下边界情况,即只有1个数的时候,异或值等于它自身,本题没有使用哨兵,所以在
getMaxXOR函数中单独处理了一下。 - 【区间记录】标准的字典树需要一个
flags[N]数组,以记录结点是否为字符串的末尾,或是记录该字符串的重复个数。本题需要判断区间的大小信息,所以需要在求最大值的同时维护相关信息。虽然可以将输入的数字全部转化为等长的21位(也就不需要flags[N]数组),但是可以设置一个ids[N]数组以记录每个结点在原输入数据中的下标。并且让它允许覆盖,这样是吻合“末端最大,长度最短”的题意的,如果想不通,可以多想一想。
代码部分
//
// Created by 南川 on 2021/1/28.
//
#include "fstream"
#include "iostream"
#include "vector"
#include "queue"
#include "cstring"
using namespace std;
typedef std::vector<int> vi;
typedef std::vector<vi> vvi;
// -------------------------
const int N = 1e5; // N is the size of input data
const int H = 21; // (H)eights for the layers, max is (32-1-1=30), the first bit // for +/-
const int K = 2; // K is the choices of 0 / 1
const int Nodes = N * H; // Nodes is the possible max
int nodes = 0; // nodes is the real count
int dfa[Nodes][K] = {0}; // (N)odes for the max num of nodes
int ids[Nodes] = {0}; // mark node with id
int Left=0, Right=Nodes, Max=0;
void insert(int pos, int val)
{
int id = 0;
for(int i=H-1; i>-1; i--)
{
int k = val >> i & 1;
if(!dfa[id][k])
dfa[id][k] = ++nodes;
id = dfa[id][k];
}
ids[id] = pos;
}
void getMaxXOR(int pos, int val) // 贪心获取最大的异或值
{
if(pos == 1) {Left = Right = 1, Max = val; return;}
int id = 0, Sum = 0;
for(int i=H-1; i>-1; i--)
{
int k = val >> i & 1;
if(dfa[id][!k]) Sum += 1 << i, id = dfa[id][!k];
else id = dfa[id][k];
}
if(Sum>Max || Sum==Max && (pos < Right || pos == Right && pos - ids[id] < Right - Left))
Max = Sum, Left = ids[id], Right = pos;
// cout << "Sum: " << Sum << ", Left: " << ids[id] << ", Right: " << pos << endl;
}
template <typename T>
void run(T & cin)
{
int n, v, temp = 0;
cin >> n;
for(int i=1; i<=n; i++)
{
cin >> v;
insert(i, temp ^= v);
getMaxXOR(i, temp); // 只与前面的前缀和比较,防止重复
}
cout << Max << " " << (Right>Left ? ++Left : Left) << " " << Right;
}
int main()
{
// speed up IO
std::ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
// read from local case if possible, otherwise from console
ifstream fin("/Users/mark/MarkLearningCPP/Acwing/1414. 牛异或/case2.txt");
run(fin.good() ? fin : cin);
}
致谢
感谢912大佬们!从零到一速成了字典树,没有你们的启发和支持我是做不到的,也感谢y总精挑细选这么好的题目。
最后再来一版暴力解法。
暴力版代码(被最后两个测例卡了,复杂度O(n^2))
//
// Created by 南川 on 2021/1/28.
//
#include <cstdio>
const int N = 1e5 + 1;
int dta1[N], dta2[N];
int main()
{
int n; scanf("%d", &n);
for(int i=1; i<=n; i++)
scanf("%d", &dta1[i]);
int Max = 0, Left = 0, Right = N;
for(int delta=0; delta<n; delta++) // 遍历n趟,第一趟单位为1,有n个单位;第n趟单位为n,有1个单位
for(int start=1, end=start+delta; end<=n; ++start, ++end)
{ // dta2[start]记录区间[start, end]的异或和,并不断维护满足题意的最大值相关信息
dta2[start] ^= dta1[end];
if(dta2[start] > Max || dta2[start] == Max && (end < Right || end == Right && delta<Right-Left))
Max = dta2[start], Left = start, Right = end;
}
printf("%d %d %d", Max, Left, Right);
}
现在数据好像加强了
我O(n^2)只过了7个点!!!
>:-(我刚看了一下,确实我也是7个点,数据应该是没有加强的,是我预估错了。第7个点对应的数据达到了5万,是上限的一半,我以为就是倒数第二个测例了(忘了查提交记录的反馈了,233)