
#include<bits/stdc++.h>
using namespace std;
const int N=110;
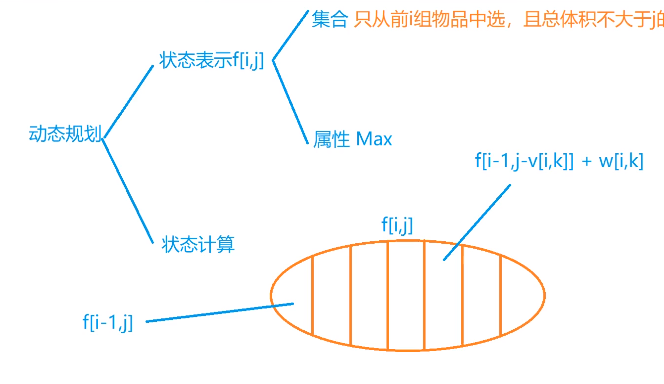
int f[N][N]; //只从前i组物品中选,当前体积小于等于j的最大值
int v[N][N],w[N][N],s[N]; //v为体积,w为价值,s代表第i组物品的个数
int n,m,k;
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>s[i];
for(int j=0;j<s[i];j++){
cin>>v[i][j]>>w[i][j]; //读入
}
}
for(int i=1;i<=n;i++){
for(int j=0;j<=m;j++){
f[i][j]=f[i-1][j]; //不选
for(int k=0;k<s[i];k++){
if(j>=v[i][k]) f[i][j]=max(f[i][j],f[i-1][j-v[i][k]]+w[i][k]);
}
}
}
cout<<f[n][m]<<endl;
}
因为只用到了第i-1列,所以可以仿照01背包的套路逆向枚举体积
#include<bits/stdc++.h>
using namespace std;
const int N=110;
int f[N];
int v[N][N],w[N][N],s[N];
int n,m,k;
int main(){
cin>>n>>m;
for(int i=0;i<n;i++){
cin>>s[i];
for(int j=0;j<s[i];j++){
cin>>v[i][j]>>w[i][j];
}
}
for(int i=0;i<n;i++){
for(int j=m;j>=0;j--){
for(int k=0;k<s[i];k++){ //for(int k=s[i];k>=1;k--)也可以
if(j>=v[i][k]) f[j]=max(f[j],f[j-v[i][k]]+w[i][k]);
}
}
}
cout<<f[m]<<endl;
}

我想问一下大家,为什么不能先将物品枚举完再进入j=m;j>=0;j–这个循环中,而是这个循环后面才是接着枚举物品
我想了半个小时相通了。首先如果是不优化第一维坐标 用f[i][j] 先枚举物品 再进行(j=m;j>=0;j–)这层循环是可以的 因为i j不会混淆 。但是如果优化了第一维坐标只用f[j]的话 正常顺序先遍历j再枚举物品时 只会修改当前这个j 意思是枚举物品这一层循环不会互相影响 但是如果先枚举物品k = k1时进入j循环 修改了f[j-v[i][k1] 然后枚举下一个物品k = k2时 用到的f[j-v[i][k2]]可能跟f[j-v[i][k1]]相等,也就是被k1修改过了 而分组背包每一组最多选一个,理论上是不会互相影响的。
eg i = 1 k = 1 第一组第一个物品 v[i][k] = 1 w[i][k] = 100 把dp[1]更新成100 i = 1 k = 2 第一组第二个物品 v[i][k] = 1 w[i][k] = 1
当进入k = 2循环 j = 2 循环时 dp[2] = max(0,dp[1] + 1) = 101
这里dp[2]的结果实际上第一组的第一个和第二个物品都选了 违反了分组背包每组只能选一个的原则。
可以看一下我在题目讨论里写的内容 写的很清楚。
可以类比一下朴素版本的完全背包
很不错的问题
用二维数组就能实现你的想法,但是这样做不能用滚动数组降维
其实可以这样想,如果k循环放在j循环外面的话,就相当于每组里面的挑选变成了一个01背包问题,但是实际上不是的,01背包并没有要求只可以挑选一个物品,而是每个物品只能挑选一个,与原意不符合,所以只能放在里面
背包问题在优化完空间之后,循环顺序必须是物品、体积、决策。这里的第三维虽然看似是在循环物品,但其实是循环当前物品组中的决策:我是选第1个物品呢,还是选第2个物品呢,还是选第3个物品呢,以此类推。
还不懂背包问题的朋友们可以看看这篇博客,感觉很详细:https://blog.csdn.net/raelum/article/details/128996521
我自己第一次写也是将物品放在了容量循环的外面,然后一直wa,思考了半小时才想到:
将物品放在外层的话,组内每个物品都会更新一次 dp[i][0]到dp[i][v] ,在压缩空间到一维这样没办法取得上一层的状态。
要这样做的话需要将开二维空间,还需要注意将上一层的最大值更新到当前层,我因为这一点debug了好久。
下面是我将物品放在外层的ac代码
但是由于将物品放在内层需要提前读入数据,存储数据的空间大于dp的空间,所以放外层的方法反而能省更多空间hh(QaQ
可以用个last存储上一轮的dp,这样既保证在线处理输入又能不开二维dp
好代码,省空间,很优美!!
为啥要用last保存呀,k不是从后往前吗
因为每组内至多选择一个物品,如果把 k 放在 j 的外层,就会变成多重背包问题,每组物品在数组 f 数组上的状态转移会累积,导致一个物品多次选择
y总没有总结背包问题模板,需要模板的可以去看看这个博客: https://blog.csdn.net/m0_61654975/article/details/141210427
第一篇的f[i][j]=max(f[i][j]…)为什么有的题解是f[i][j]=max(f[i-1][j]…)?有什么区别?
哪里?
我是这样想的:i 是指物品种类,第一种 f [i] [j]: 这类问题通常一种物品可以选多个,如:多重背包问题,完全背包问题,一种物品可以选多个,所以当前最大值并不依赖上一种物品在容量相同时的最大价值,而是需要在同种物品中的多种选择中选出最大值,所以是 i,而非 i - 1.
第二种 i - 1: 由于并不选当前 i ,所以 当前容量的最大价值依赖于相同容量的前一种物品所得的最大价值。
我的理解是:第一种相当于横向迭代,而第二种相当于纵向迭代
兄弟牛好理解
还不懂背包问题的朋友们可以看看这篇博客,感觉很详细:https://blog.csdn.net/raelum/article/details/128996521
为什么一维01背包不要if判断,这个又要了呢
体积的循环条件不一样,一个最小是0,一个最小是v[i]
这是为啥呀老哥
因为我们需要判断组里的每一种东西的体积时,都要j>v[i][k]开始,但是确定k的时机是在确定j下面,所以限制条件还是在循环最里面
01背包是倒序循环的,设置的条件就是j >= v,所以不需要判断
为什么01背包for(int j = m;j >= v[i];j –)
而分组背包 for(int j=m;j>=0;j–)
因为分组不知道在第i组中,物体的体积最小值吧,
理论来说只要知道该组物体的体积最小是多少也可以 , j >= min(v[i][k])
在01背包中一次只考虑选不选第i个物体, 即 j >= v[i]
谢谢大佬
第一个代码是怎么保证每组里面只能选一个物品的呀
你想想,max可能更新了好几次,但最后只有一次更新被保留
只记录最大值
一级一级更新,上层决定下层,本层的数不会更新本层的数
这个优化没有提高运行速度,不过节省了一些存储空间
好开心,看懂啦!!!😘😍😍
呦西 very good 嘎嘎赞
二维dp先循环组然后先循环背包空间或者物品都可以,但是一维dp必须组{背包空间{物品{}}},这个点弄半天才明白。
大家有用交替滚动写的代码吗
🐂
k 是不是应该 可以等于s[i] 的
这个K只是表示每组里面的物品序号,可以改为for(int k=1;k<=s[i];k);
上面的读入也要给为for(int j=1;j<=s[i];j)才行
可以不用二维数组
题解给了
他说的应该是这种
诶诶那个不选是表示不选第i个物品吗
不选表示不选第 $ i $ 组物品的所有物品,只从前 $ i-1$组物品里面选
看懂了兄弟,谢谢
应该是不选第i组的物品,而不是不选第i组的所有物品。
有什么区别吗?
//for(int k=s[i];k>=1;k–)也可以 不太对吧
for(int j=0;j[HTML_REMOVED]>v[i][j]>>w[i][j];
}
比如说,s[i] = 5,v[i][0-4],w[i][0-4] k = s[i]=5, v[i][5]超出界限
复杂度On3吗
nms 10的6次方左右
#include[HTML_REMOVED]
using namespace std;
const int N = 110,V=111;
int dp[N][V]={0};
int n,v,s,a,b;
int main()
{
cin>>n>>v;
for(int k=1;k<=n;k){
cin>>s;
for (int i = 0; i < s; i ){
cin>>a>>b;
for (int j = a; j <=v; j ++){
int t=max(dp[k-1][j],dp[k-1][j-a]+b);
dp[k][j]=max(dp[k][j],t);
}
}
}
cout<<dp[n][v];
return 0;
}
我这种先遍历物品 再遍历体积的方法哪里不对呢 求指导
如果先遍历物品再遍历体积,举个例子:dp[k][j]表示k组容量j;最底层循环先求出dp[k]在dp[k-1]的基础上拿第一个物品的结果,接下来求第二个物品,但是第二个物品表达式为 dp[k][j] = max(dp[k - 1][j], dp[k - 1][j - v[k][i]] + w[k][i]);
仍是根据dp[k-1]求的最优解,无法和取第一个物品的结果相比较,所以不对
f[i][j]=f[i-1][j]; //不选
for(int k=0;k[HTML_REMOVED]=v[i][k]) f[i][j]=max(f[i][j],f[i-1][j-v[i][k]]+w[i][k]);
为什么f[i][j] 这句要在k层循环外面
因为如果第三重循环有更新
f[i][j]的话,会被这句话覆盖掉k层循环是一个更新,因为这一组k个物品只选1个
因为在第三个for循环里,我们第一个max里参数要为f[i][j]去比较不断更新的数,所以我们无法在这个嵌套里得到不选时的数,所以我们需要for循环外给f[i][j]赋上一个不选时的初值,让其与选了之后值进行对比。
大佬说的很透彻 我补充个例子帮助大家理解 假如s[1]=2,那么会执行两次循环,进入for循环后,执行一次f[i][j]=f[i-1][j],然后执行一次f[i][j]=max(f[i][j],f[i-1][j-v[i][k]]+w[i][k])获得max值,再进入for循环后之前的max值就会被f[i-1][j]更新,结果错误.
请问什么时候k从前面遍历,什么时候k从后面遍历呀
我是这么理解的
完全背包( 由于物体个数不限)从前往后枚举体积
01背包(由于物体个数只有一个) 从后往前枚举体积
当然这都是在优化成一维的情况下的写法 不优化空间的话怎么遍历都行
你说的k的含义应该是容积吧,当用到i-1层时,从后面遍历,当用到第i层时,从前面遍历
大佬,想问一下,每组只选一个 是怎么体现的呢?
同问
for(int j=m;j>=0;j++)//逆序枚举同,01背包只能取一次
因为对重新计算第i次来说f[j]中保存的是上一次计算好的f[i-1]的值
而顺序枚举会覆盖原来的值
又没得每组只选一个的代码呀,求代码
我的理解 :因为f(m)→f(0)的状态更新用的是上一层的数据,所以在本层的更新过程中,i组内k个物品只会变成相互竞争能者居之的状态而不是同时选上从而叠加价值的状态
是因为你的状态方程里面没有k,所以你遍历组里的每一个物品,用最大值来覆盖。
字母i就代表组