


双向搜索代码
/*
* File: 01_送礼物.cpp
* Project: 0x25_双向搜索
* File Created: Sunday, 10th March 2021 8:09:48 pm
* Author: Bug-Free
* Problem: AcWing 171. 送礼物
*/
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
typedef long long LL;
const int N = 1 << 25; // k最大是25, 因此最多可能有2^25种方案
int n, m, k;
int g[50]; // 存储所有物品的重量
int weights[N]; // weights存储能凑出来的所有的重量
int cnt = 0;
int ans; // 用ans来记录一个全局最大值
// u表示当前枚举到哪个数了, s表示当前的和
void dfs(int u, int s)
{
// 如果我们当前已经枚举完第k个数(下标从0开始的)了, 就把当前的s, 加到weights中去
if (u == k) {
weights[cnt++] = s;
return;
}
// 枚举当前不选这个物品
dfs(u + 1, s);
// 选这个物品, 做一个可行性剪枝
if ((LL)s + g[u] <= m) { //计算和的时候转成long long防止溢出
dfs(u + 1, s + g[u]);
}
}
void dfs2(int u, int s)
{
if (u == n) { // 如果已经找完了n个节点, 那么需要二分一下
int l = 0, r = cnt - 1;
while (l < r) {
int mid = (l + r + 1) >> 1;
if (weights[mid] <= m - s)
l = mid;
else
r = mid - 1;
}
ans = max(ans, weights[l] + s);
return;
}
// 不选择当前这个物品
dfs2(u + 1, s);
// 选择当前这个物品
if ((LL)s + g[u] <= m)
dfs2(u + 1, s + g[u]);
}
int main()
{
cin >> m >> n;
for (int i = 0; i < n; i++)
cin >> g[i];
// 优化搜索顺序(从大到小)
sort(g, g + n);
reverse(g, g + n);
// 把前k个物品的重量打一个表
k = n >> 1;
dfs(0, 0);
// 做完之后, 把weights数组从小到大排序
sort(weights, weights + cnt);
// 判重
int t = 1;
for (int i = 1; i < cnt; i++)
if (weights[i] != weights[i - 1])
weights[t++] = weights[i];
cnt = t;
// 从k开始, 当前的和是0
dfs2(k, 0);
cout << ans << endl;
return 0;
}

我感觉倒序是不会影响dfs的运行效率的,因为所有合法的操作都会到叶子结点,不会因在快速搜到部分结果有更好的剪枝方案。只要保证前面半个dfs所在的数据集是较大的一部分数据从而得到weights数组,那么前后两个dfs内部是否是按照从大到小枚举是没影响的,测试时间一样,也就是说从大到小遍历主要是影响进行二叉搜索的weights数组的大小从而影响二叉搜索的复杂度。
实际测试了一下,甚至你不排序,不倒序这两个操作, 直接分为前半dfs1后半dfs2,虽然这样得到的weight数组会稍微大些,但实际效率也就差个百分之4,而如果前半dfs2后半dfs1效率甚至是和选取较大数据作为dfs1相差无几的,这可能和测试样例的分布倾向有关。
各位大佬,记得y总之前说过背包问题本质就是一种组合问题
那么这样来枚举的话为什么会超时,按照选或不选来枚举时间复杂度是容易的就是n2^23
但是如果按照我这样枚举的话那么时间复杂度就应该是一个组合问题也就是相当于C(n,n)+C(n,n-1)+…+C(n,1)+C(n,0)根据二项式定理也可以写为n2^(n/2)
想不明白为什么会超时,哪位大佬可以告诉我重复枚举了哪些状态空间吗?谢谢大佬了
我明白了这样也是可以的只不过常数又点大,当我把函数分成两个写参数写为2个的时候过掉了
代码如下:
如果合成一个函数写,写选或不选的做法也过不掉,很玄学
但是分开写参数两个就可以过掉三个参数也过不掉
各位佬儿,这个代码MLE是怎么回事儿呢
y总说过了啊, k = n / 2 + 2;会导致死循环,修改为k=n>>1;
1、修改成k=n>>1,时间复杂度是O(2^(n/2) * log(2^(n/2))=192,937,984 会不会超时
2、k = n / 2 + 2;会导致死循环为什么改成k =min( n / 2 + 2,n)也通不过
特殊数据 你可以算一下 1,2,3,4,5 就会发生数组越界 MLE
请问一下,dfs_2为啥不是从k+ 1开始的呢,为什么是从k开始?
第一个dfs枚举第0到k-1个,第二个枚举第k到n-1个
为什么我用vector存数据来存数据,是超时的??
为啥最后一组数据超时呢
为啥最后一组数据超时呢
送礼物这道题的终态是什么
sort(weights, weights + cnt); O(nlogn) cnt最大是2^23=810^6 232^23=1.6*10^8不超时吗
大佬,我交了一下你的代码,爆栈了,不知道是不是数据加强了
有个数据是n = 1,此时k = 2,搜索的时候到不了边界了www,改成k = n >> 1就行
然而k = n / 2 + 2居然比k = n >> 1快,这数据真是太玄学了
不玄学,y 总的课里讲了,更均衡一些
k=n/2+2会sf,我改成n/2+1结果tle,改成n/2结果还过了。。。
我觉得原文说用n / 2 + 2 更均衡不完全对,排除特殊情况n = 1 造成的内存溢出问题外。由于加大k是为了平衡后半dfs二分时的系数, 但是这个系数只会在叶子结点出现,由于剪枝的存在,这些点的二分并不一定能使整个dfs时间明显变得更大,这种情况下k加大2反而影响了前半和后半的平衡
$dalao$我想问一下为什么我把二分的左边界设置为$1$就过不了呢?$weight$数组不是从$1$开始的吗?
把你的代码中的$l$改成从$1$开始也不行
这里有一个死循环,k = n >>1比较好
weights数组是从 $0$ 开始的呀666
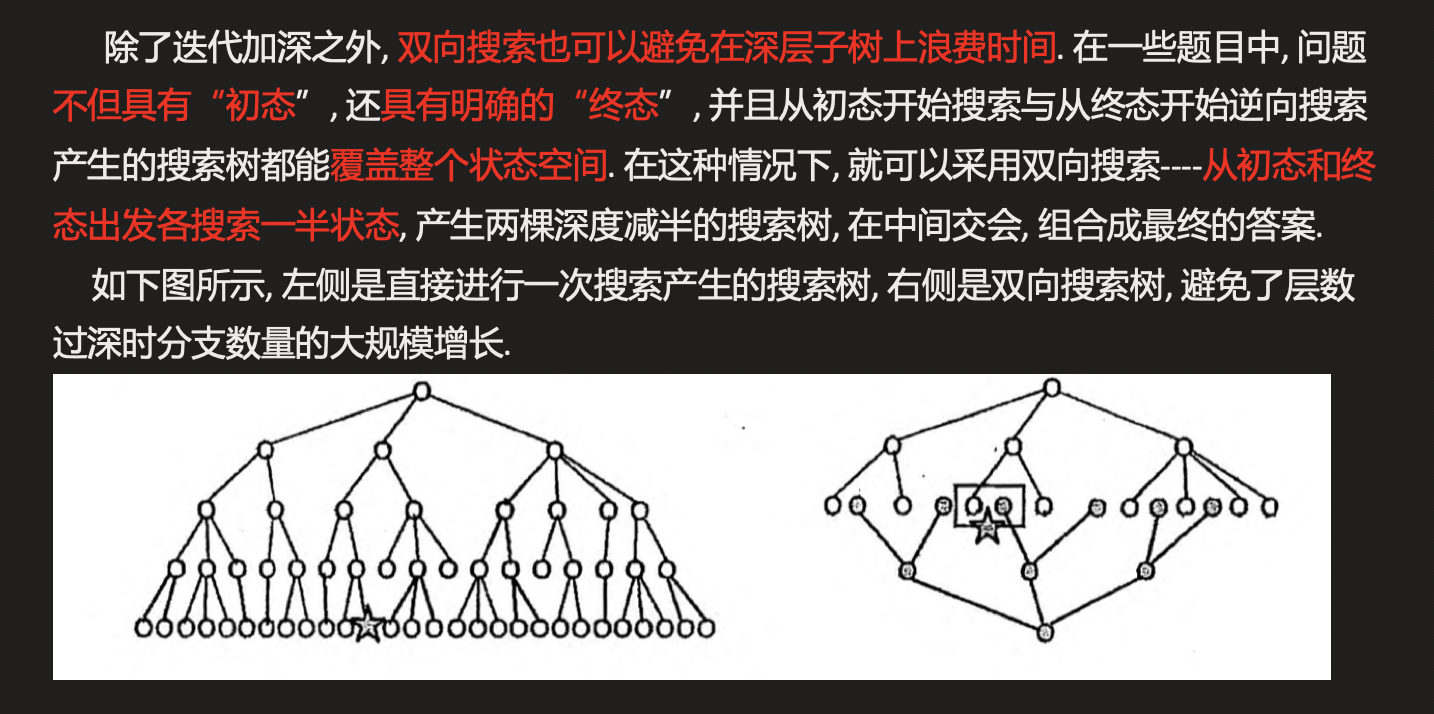
有图好评
图片好评
楼主好棒