
题目描述
给定一个字符串 s 和一些长度相同的单词 words。
找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
算法1
做了几个表 代码比较简洁 但是效率较低
做了一个数组每个位置开头能够对应字典中的那个单词的表格 加速查询
然后遍历数组 尝试每个位置开头能否有连续的包含字典全部单词的可能
频繁的使用了STL中的数据结构 效率一般

C++ 代码
class Solution {
public:
string strArr[10010];
unordered_map<string, int> mm;
bool Check(const string& s, int idx, const vector<string>& words)
{
int l = idx; int count = words.size();
int needLen = count * words[0].size();
unordered_map<string, int> mmCopy = mm;
while (l <s.size()) {
string curr = strArr[l];
mmCopy[curr]--; count--;
if (mmCopy[curr] < 0) return false;
if (count == 0) return true;
l = l + words[0].size();
}
return count==0;
}
vector<int> findSubstring(string s, vector<string>& words) {
int len = words[0].size();
vector<int> ans;
if (len > s.size()) return ans;
for (int i = 0; i < words.size(); i++) {
mm[words[i]] ++;
}
for (int i = 0; i <= s.size() - len; i++) {
string subS = s.substr(i, len);
if (mm.count(subS) != 0) {
strArr[i] = subS;
}
}
for (int i = 0; i <= s.size() - len; i++) {
if (!strArr[i].empty()) {
if (Check(s, i, words)) ans.push_back(i);
}
}
return ans;
}
};
算法2
第二种方法是双指针 但是计算的跨越的长度是单个单词的长度。
同之前的双指针记录区间内多少个字母的哈希是一样的思路
但是这里记录的是多少个单词的哈希
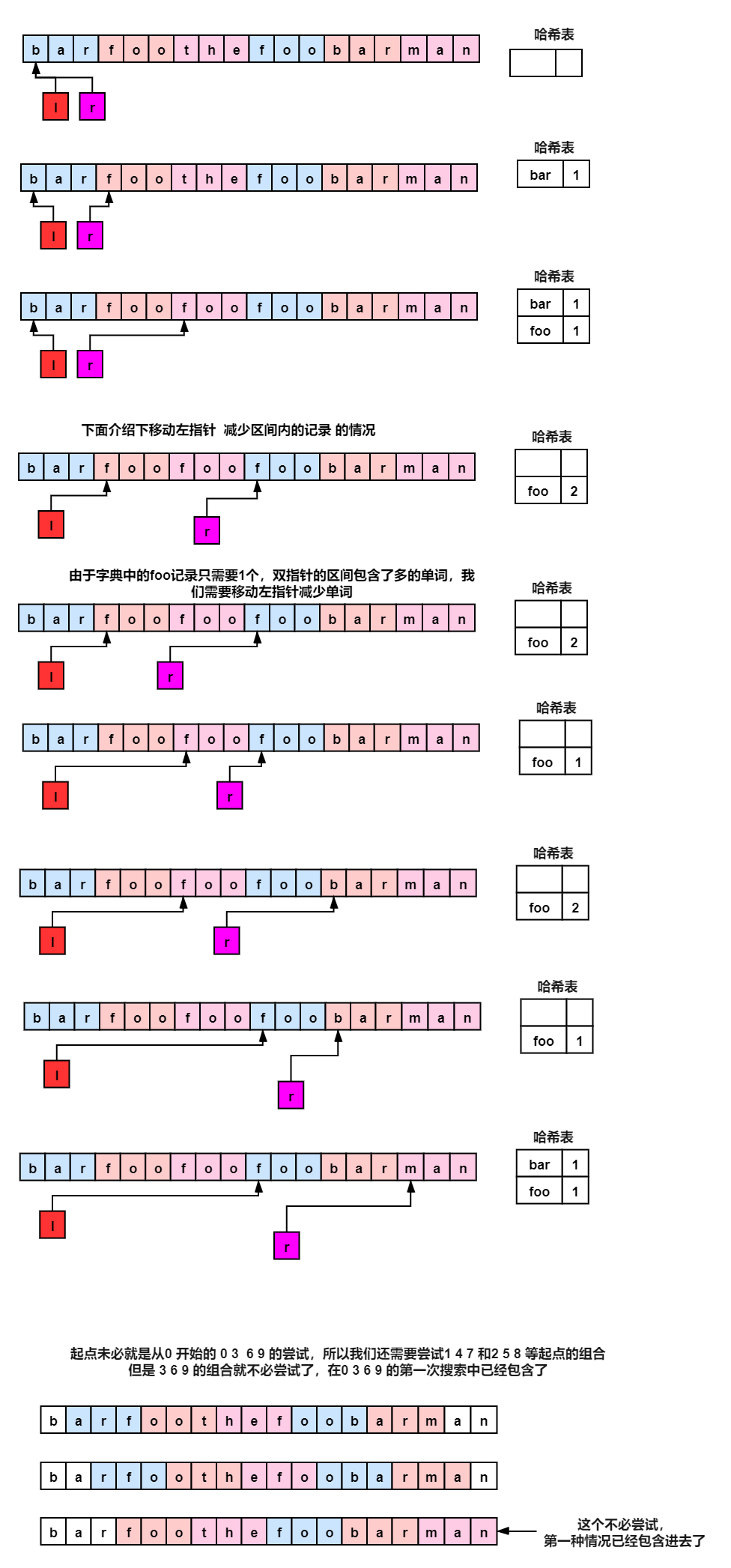
C++ 代码
class Solution {
public:
vector<int> ans;
unordered_map<string, int> mm;
void Check(const string& s, const vector<string>& words, int idx) {
int len = words[0].size();
int l = idx; int r = idx;
unordered_map<string, int> currM;
while (l < s.size() && r < s.size() && l <= r) {
string w = s.substr(r, len);
r += len;
if (mm.count(w) != 0) {
currM[w]++;
while (currM[w] > mm[w] && l<r) {
string remove = s.substr(l, len);
currM[remove]--; l += len;
}
if (currM[w] == mm[w]) {
int find = 1;
for (auto& e : mm) {
if (e.second != currM[e.first]) { find = 0; break; }
}
if (find == 1) {
ans.push_back(l);
}
}
}
else {
l = r; currM.clear();
}
}
}
vector<int> findSubstring(string s, vector<string>& words) {
for (auto& e : words) { mm[e]++; }
int len = words[0].size();
if (s.size() < words.size()*len) return ans;
for (int i = 0; i < words[0].size(); i++) {
Check(s,words,i);
}
return ans;
}
};
