
代码
#include <algorithm>
#include <cstring>
#include <iostream>
using namespace std;
const int N = 1e1 + 5, M = 1e3 + 10;
int n, m;
char str[M][N];
int dp[N][N];
int edit_distance(char a[], char b[])
{
int la = strlen(a + 1), lb = strlen(b + 1);
for (int i = 0; i <= lb; i++) {
dp[0][i] = i;
}
for (int i = 0; i <= la; i++) {
dp[i][0] = i;
}
for (int i = 1; i <= la; i++) {
for (int j = 1; j <= lb; j++) {
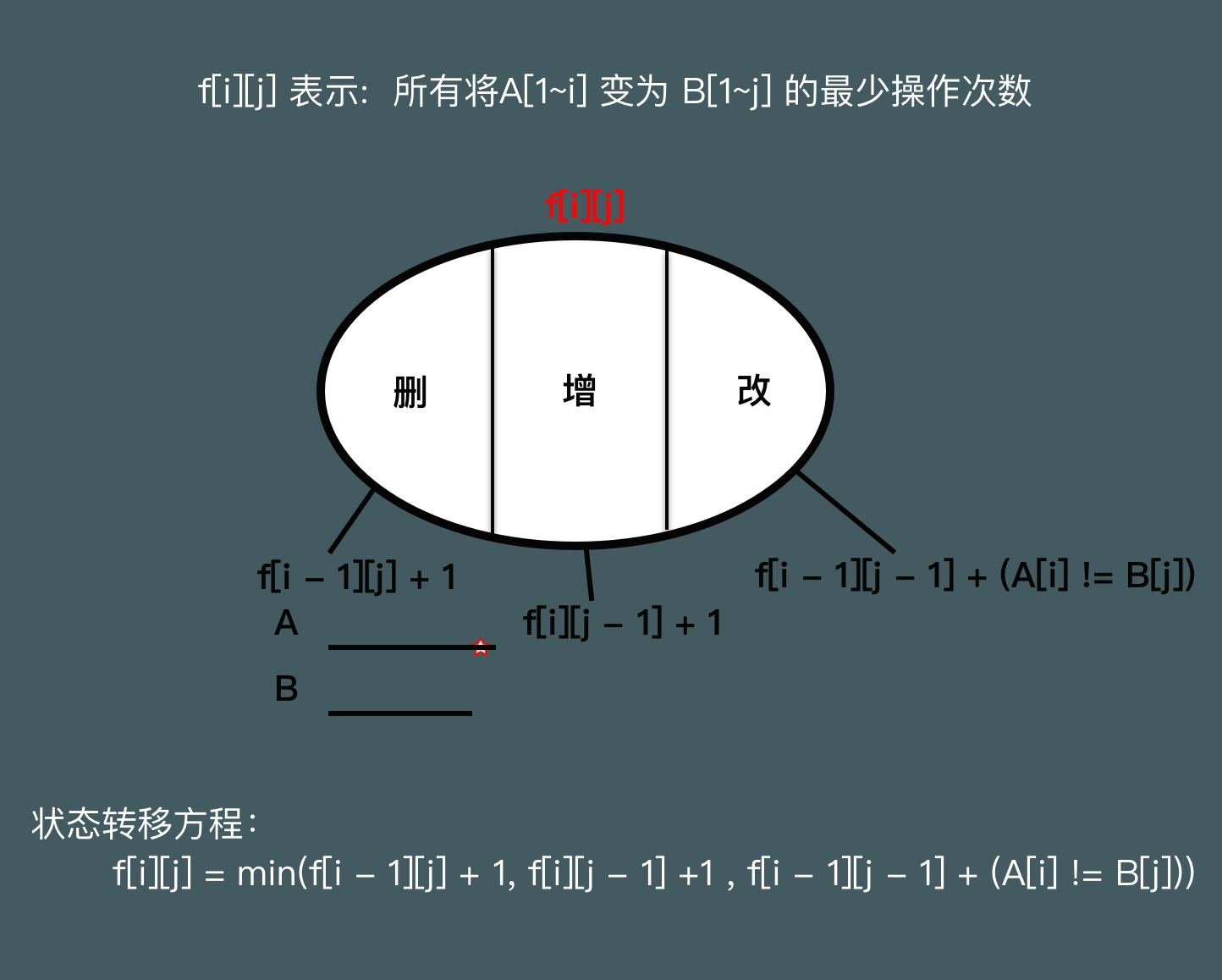
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
dp[i][j] = min(dp[i][j], dp[i - 1][j - 1] + (a[i] != b[j]));
}
}
return dp[la][lb];
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i++) {
cin >> (str[i] + 1);
}
while (m--) {
int res = 0;
char s[N];
int limit;
cin >> (s + 1) >> limit;
for (int i = 0; i < n; i++) {
if (edit_distance(str[i], s) <= limit) {
res++;
}
}
cout << res << endl;
}
return 0;
}
如果edit_distance传入参数写成 (str[j] + 1, pat + 1) ,然后再在函数内部直接使用 strlen 计算字符串长度,答案会出错,会有几个样例出现WA,这是为什么呢?
也遇到了同样的问题,想明白了,问题在于 “下标”。
我们传入的完整的字符串下标是从0开始的,而后面dp是从1开始的,所以dp过程中遍历的两个字符字符串是不完整的字符串,两个字符串中0位置的字符被我们忽略了。
所以要对应dp的话,传入的字符串应该保证第一个字符 “下标”对应是1,而不是0,所以要传入 (str[j] + 1, pat + 1)。
如果按照 0 传入的话也可以 把a[i] != b[j] 改成a[i-1] != b[j-1] 即可 但是感觉没有以前好理解
二维数组在逻辑上是分行分列的,但存储结构却是连续的。 字符串 “A的长度为 5,加上结束符 “0” 共 N+1 个字符,前 N个字符分别从 c 行的首元素 c 开始存放,到 c ,第 N+1 个字符 ‘0’ 只能保存到 下一行的首位置
(a[i]!=b[j])有无大佬可以解释。
如果
a[i] == b[j],那么从f[i-1][j-1]到f[i][j]不需要做任何修改,也就是f[i][j] = f[i-1][j-1]否则需要一次操作修改·a[i]为b[j],也就是f[i][j] = f[i-1][j-1] + 1。而a[i] != b[j]的值在上述两种情况恰好也一定就是0/1。true和false和整形运算会自动类型转换成1和0
为什么要用f[M][N]呢,一维数组为什么不行呢
判断函数中为什么用strlen(a+1)而不是strlen(a)
因为作者用到的字符串都是下标从1开始存储的,计算数组长度时也要从1开始计算
strlen是for循环判断a[i]是否==’\0’,如果不从a + 1开始,那么strlen只会是0
请问一下这个画图软件是啥呀
sketch
好的,谢谢
f[i][j] = INF;这句不需要定义么
请问一下,在输入str时候我把他改成了 for(int i=1;i<=n;i++)cin>>a[i]; 在主函数里调用的时候也是从1开始,为什么答案就会差1?
cin读字符串有可能会读入一些奇怪的东西吧,不是很清楚hh
字符串末尾没有补0
这里是输入一个二维的字符串,每个字符串从i = 0~n -1,str[i][1]开始存,你这个是完全不一样的i = 1~n,str[i][0]开始存
你是对的