
思路
采用并査集,但是维护多一个数组 d,用来计算当前节点到父节点的 距离,初始化为 0(因为自身到自身的距离为 0)。根据当前节点到 root 节点的距离(root 节点只能存在一个,其他节点都是 root 节点的子节点)。这个距离算出来只能出现三种情况:0, 1, 2(距离大于或者等于3,取模处理)
路径压缩:
假设并査集当前的状态如下:
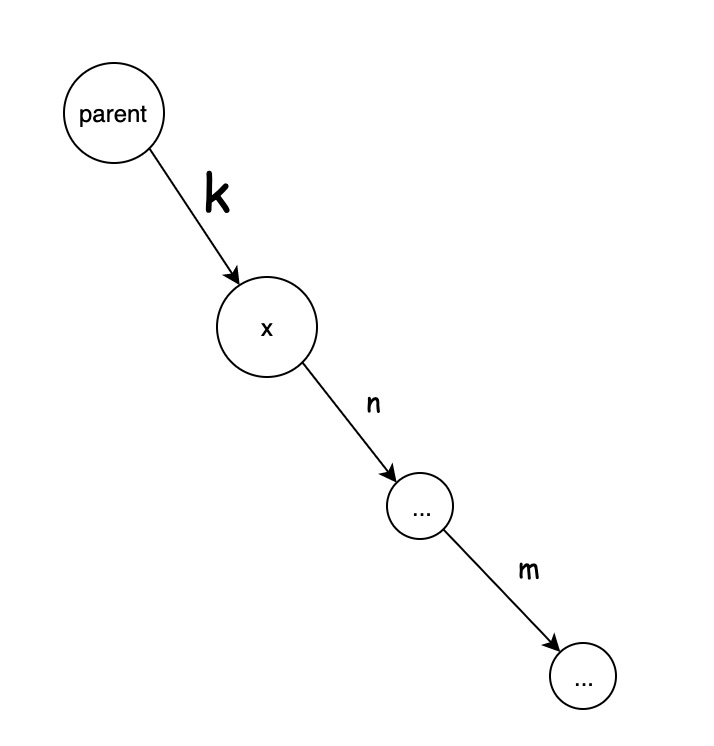
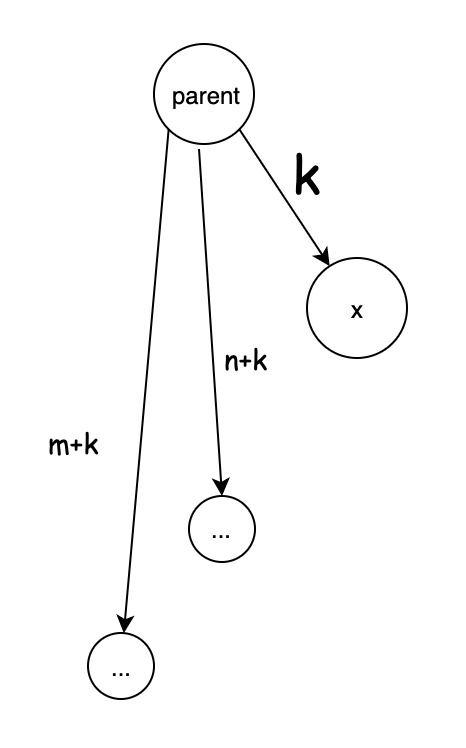
压缩后的状态应该如下:
路径压缩的代码如下(这题一定要用路径压缩,不使用路径压缩很难更新子节点的路径长度):
const int M = 3;
int find(int x) {
if (x != parent[x]) {
int oldParent = parent[x];
parent[x] = find(parent[x]);
d[x] = (d[x] + d[oldParent]) % M; // 注意这里一定要取模,不然这个距离可能会大于 M
}
return parent[x];
}
x 和 y 同类的情况
判断 x 和 y 是否是同类
1. 首先判断 x 和 y 是否都在同一个 root 节点上
1.1 如果 x 和 y 的父节点(p1, p2)在同一个 root 节点上(说明 p1 和 p2 已经处理过关系了),判断距离是否相等 (d[x] % M == d[y] % M)
1.2 如果 p1 != p2,说明 x 和 y 还没有关系,可以进行合并
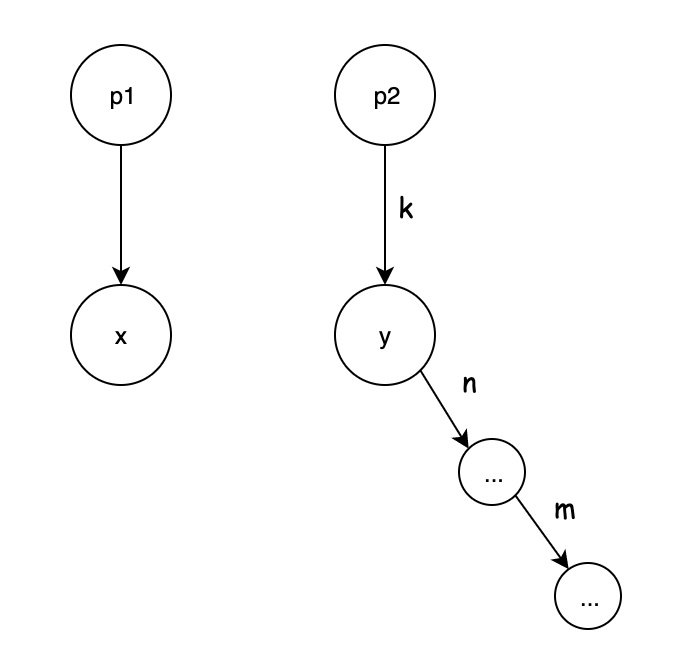
合并的过程如下:
1. 合并前的状态
- 合并后的状态
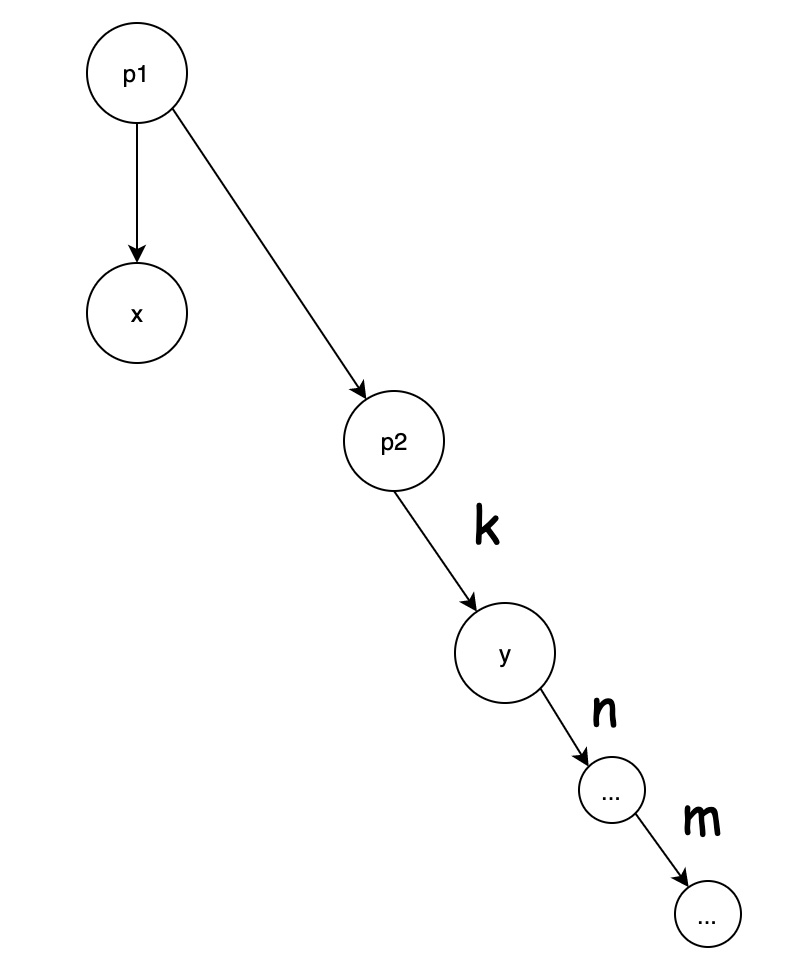
合并的代码如下:
parent[p2] = p1;
d[p2] = ((d[x] - d[y]) + M) % M; // 使用 +M 防止 d[x]-d[y] 为负数
合并的时候,只需要计算 d[p2] 的路径。为了满足 x 和 y 在同一类上,d[p2] 的路径应该满足:
d[x] % M == (d[y] + d[p2]) % M ==> d[p2] = ((d[x] - d[y]) + M) % M
只需要,更新 d[p2] 的路径,下次计算 d[y] 的路径在下次 “路径压缩” 的时候会被自动计算(这也是为什么这题只能使用路径压缩来做,如果不是路径压缩,那么计算完 d[p2],还要更新 p2 所有子节点的路径)
x 吃 y 的情况
x 吃 y 的分析和 x 和 y 同类是一样的,懒得画了
int p1 = find(x);
int p2 = find(y);
// 如果 x 和 y 已经处理过了
if (p1 == p2) {
return d[x] % M == (d[y]+1) % M;
}
parent[p2] = p1;
d[p2] = ((d[x]-d[y]-1) + M) % M;
C++ 代码
// CreateTime: 2019-11-10 15:54:36
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <queue>
#include <vector>
#include <stack>
#include <map>
#include <set>
using namespace std;
int n;
int k;
int D;
int x;
int y;
const int N = 5e4 + 10;
const int M = 3;
int parent[N];
int d[N];
void init() {
for (int i = 0; i <= n; i++) {
parent[i] = i;
d[i] = 0;
}
}
int find(int x) {
if (x != parent[x]) {
int oldParent = parent[x];
parent[x] = find(parent[x]);
d[x] = (d[x] + d[oldParent]) % M;
}
return parent[x];
}
bool D1(int x, int y) {
int p1 = find(x);
int p2 = find(y);
// 如果 x 和 y 已经处理过了
if (p1 == p2) {
return d[x] % M == d[y] % M;
}
parent[p2] = p1;
d[p2] = ((d[x] - d[y]) + M) % M;
return true;
}
bool D2(int x, int y) {
int p1 = find(x);
int p2 = find(y);
// 如果 x 和 y 已经处理过了
if (p1 == p2) {
return d[x] % M == (d[y]+1) % M;
}
parent[p2] = p1;
d[p2] = ((d[x]-d[y]-1) + M) % M;
return true;
}
int main(void) {
int res = 0;
cin >> n;
init();
cin >> k;
while (k--) {
cin >> D >> x >> y;
if (x > n || y > n) {
res += 1;
} else {
if (D == 1) {
if (D1(x, y) == false) {
res += 1;
}
}
if (D == 2) {
if (D2(x, y) == false) {
res += 1;
}
}
}
}
cout << res << endl;
return 0;
}

为什么find函数里的%M不能省略啊,y总的find函数里没有%M欸
同问
个人感觉,取模后,主函数处理就不用再次取模了,也就是换了一个地方取模,在find函数直接把d[x]更新成0,1,2,直接用来表示种类了
请问下第一张图路径压缩后,最左侧距离应该更新成 n+m+k 吧?
不错(错误很误导人)
是的 - -
很清晰!佩服大佬
tql,自己想了好久最清晰, 没有之一
太清晰了
%%%
d[p2] = ((d[x] - d[y]) + M) % M; // 使用 +M 防止 d[x]-d[y] 为负数
为什么不写成((d[x] - d[y]) %M+M)%M呢。第一次接触不太明白
写的真好
思路清晰,dalao爱了!
思路清晰 赞
真好!!!
厉害厉害 大佬佩服
%%%