
题目(Least Recently Used)
146. LRU 缓存机制
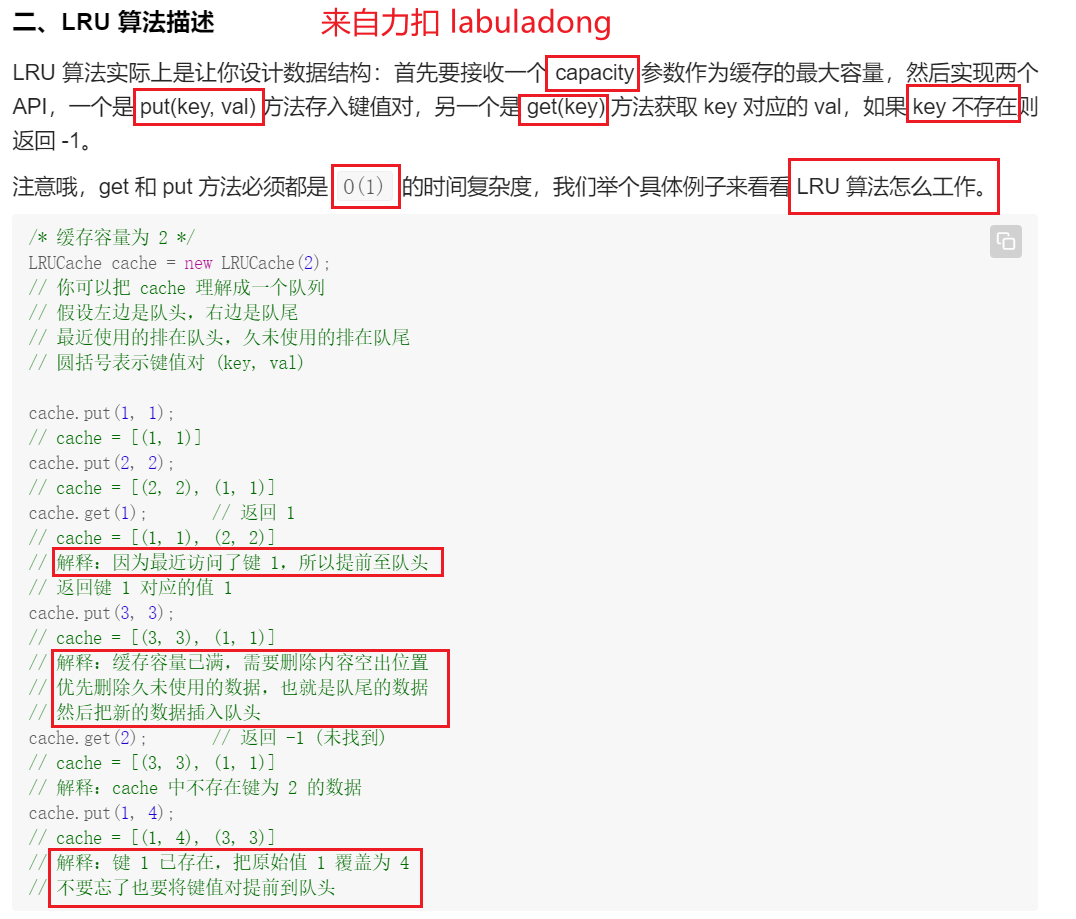
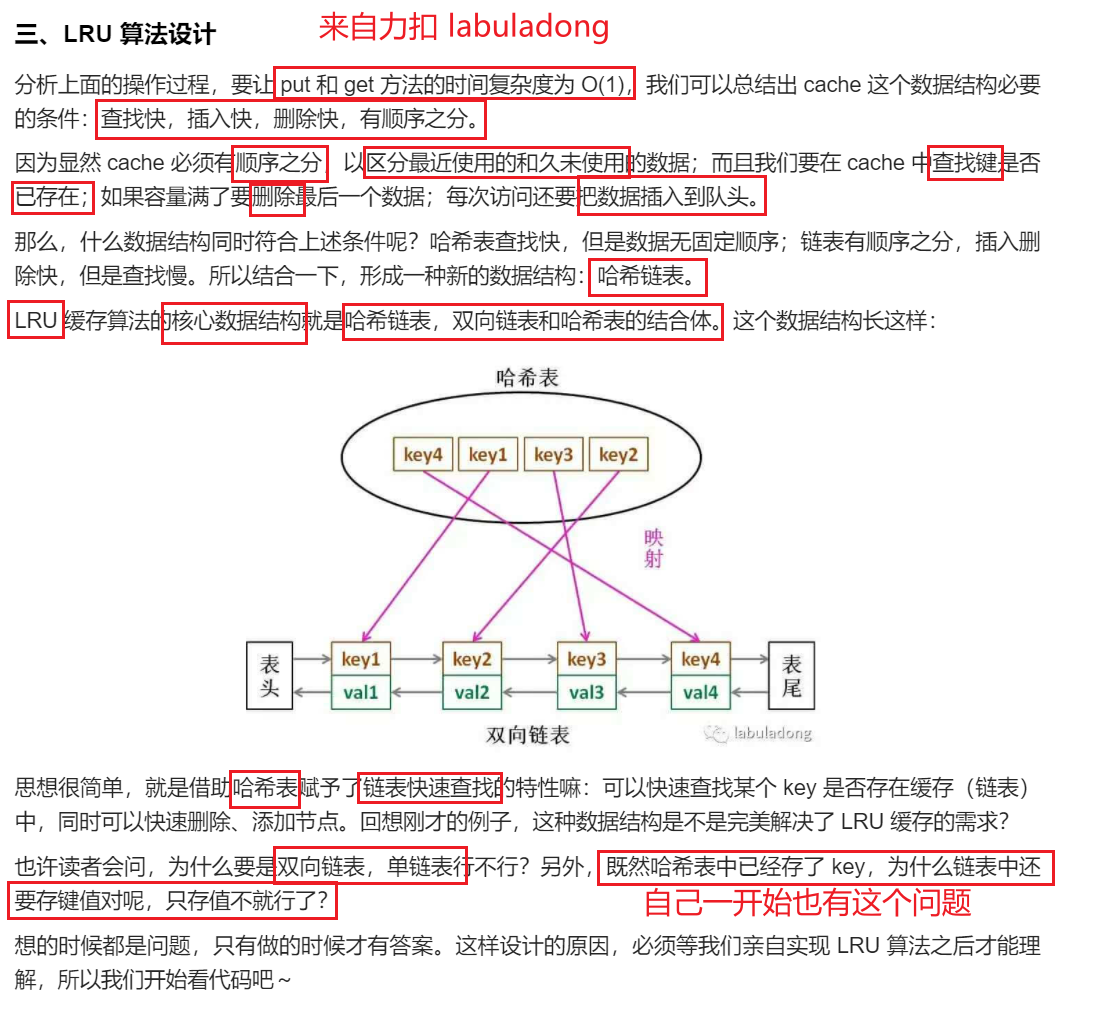
思路
- hash表:
unordered_map<int, Node*> hash; 双向链表用来 将Node根据使用时间进行排序。靠近左端表示最近使用,靠近右端表示较长时间没有使用。


代码
// y 总代码
class LRUCache {
public:
struct Node { // 注意结尾处有分号 ';'
int key, val;
Node *prev, *next; // 下一行 是 构造函数, 注意结尾 没有分号 ';'
Node(int _key, int _val): key(_key), val(_val), prev(nullptr), next(nullptr) {}
}*L, *R; // *L, *R 是 结构体变量, L 是双向链表的头, R 是双向链表的尾. L, R 是固定不动的.
// 注意: *L, *R 在这声明是全局变量, 在 LRUCache()函数内声明定义再初始化,则不是全局变量
// *L, *R 在这里只是声明定义, 在 LRUCache() 函数内 还要初始化 L = new Node(-1, -1)
// 注意 一共 4个全局变量: L, R, hash, n. 可以 找一下 分别在哪用到了
// 注意 hash 的 val 是 Node* 型, 一开始顺手写成 <char,int> 了...
unordered_map<int, Node*> hash; // 这行 要定义在 struct Node后面, 否则 不知道 Node*
int n; // 全局变量
void delete_node(Node *p){ // 在链表 后端 删除. 一开始 写成了 (*p), 忘记加 Node 了
p->prev->next = p->next, p->next->prev = p->prev;
}
void insert_node(Node *p){ // 在链表 前端 插入, 一开始 写成了 (*p), 忘记加 Node 了
p->next = L->next, L->next->prev = p; // 在这里 用到了全局变量 L
p->prev = L, L->next = p;
// 这两行的顺序 要注意一下, 这里涉及 3个结点的连接关系, 建立连接之前 从左到右 分别是 L, p, L->next,
// --- 因为 L->next 是 依赖于 L 来索引的, 一旦 L 的next发生变化, L->next 结点就索引不到了, 因此,
// --- 1. 就要先处理 L->next 结点的连接关系, L->next 结点相关的连接 就是 和 p 之间的 两条线,
// --- p->next = L->next, L->next->prev = p; 这两个 互换 也 没关系.
// --- 2. 然后处理 L 和 p 之间的 连接关系,
// --- p->prev = L, L->next = p; 这两个 互换 也 没关系.
//
// 其实不一定按照 先 1 后 2 的顺序, 只要保证 L->next = p 在 最后, 就必定不会出错.
// 再宽松一点, 只要 L->next = p 在 1.(p->next = L->next, l->next->prev = p 这俩可以互换)之后,
// 即 只要 L->next = p 在 L->next结点的连接关系处理完之后, 就必定不会出错.
}
LRUCache(int capacity) { // 初始化 全局变量 n, 同时将 L 和 R 的 连接关系处理好
n = capacity;
// Node L = new Node(-1, -1), R = new Node(-1, -1); // 在这里定义的话 不是 全局变量
L = new Node(-1, -1), R = new Node(-1, -1); // 上面声明定义成全局变量, 这里要用 new 初始化 !!! 否则报错 !!!!!!!!!!!!!!!!!!!!
L->next = R, R->prev = L;
}
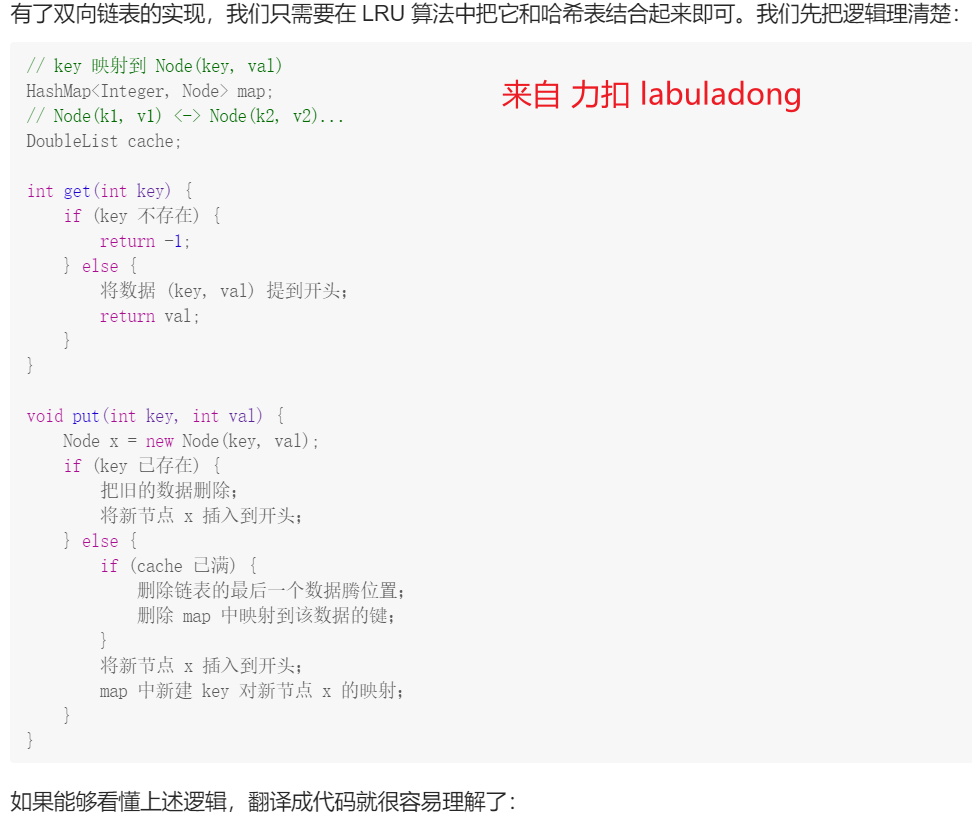
int get(int key) { // 判断hash里有没有这个key. 没有return -1; 有就 将 hash[key] 这个node 提前
if (!hash.count(key)) return -1;
else{
auto p = hash[key]; // 注意 加 auto
delete_node(p);
insert_node(p);
return p->val;
}
}
// 判断hash里 有没有这个key.
// 1. 要是 没有这个 key, 要先判断 Cache 是不是满了, (1) 满的话, 要将 链表最后的node 删掉,
// --- 同时根据node->key 将 hash的key删掉. (2) 没满的话, 直接 插在链表头, 并在hash里加入这个key
// 2. 要是 有这个 key, 就不用判断 Cache 是不是满了, 因为 本来已经有这个 key 了, 现在 只是替换 node,
// --- 需要将 hash[key] 这个node 先 从链表尾 删掉, 再将 hash[key] 插在 链表头, 并将val更新为 value.
void put(int key, int value) {
if(!hash.count(key)) { // hash 里 没有这个 key
if (hash.size() == n){ // 先判断 Cache 满了没. 在这里 用到了全局变量 n = capacity
auto p = R->prev; // 在这里 用到了全局变量 R
delete_node(p);
hash.erase(p->key); // 根据node的key,删除hash中key
}
auto p = new Node(key, value); // 没有 就 new一个. 注意 此处写法
hash[key] = p;
insert_node(p);
// delete p; // 脑残了, 注意 这里不能 delete ......
}
else{ // hash 里有这个 key
auto p = hash[key]; // 注意 加 auto
p->val = value;
delete_node(p);
insert_node(p);
}
}
};
知识点:
1. unordered_map 用法:
参考来源:详细介绍C++STL:unordered_map。
这里记录 unordered_map 几个常用的 用法,设 unordered_map<int, Node*> hash;
Capacity 容量:- 判断是否
为空:hash.empty() - 返回有效元素
个数:hash.size()
- 判断是否
元素修改:- 删除元素:hash.
erase(key) - 插入元素 :hash.
insert(key)。可以直接用 hash[key] =val。
- 删除元素:hash.
查找,判断 给定 key是否存在:- 返回 匹配给定 key 的元素的个数 :hash.
count(key) - 通过给定 key 查找元素:
不存在,hash.find(key)==hash.end();找到了 hash.find(key)!=hash.end()
- 返回 匹配给定 key 的元素的个数 :hash.
2. c++ 声明、定义、初始化与赋值
参考来源:c++ 声明、定义、初始化与赋值(参考文献:《C++ primer》 5th 中文版),C++ 声明,定义与初始化的基本概念。
同一个文件下:
对于变量而言,在同一个文件里面,很少使用声明这个说法,一般没有人去说我要声明一个变量,然后定义这个变量。或者说,声明与定义没有明显的区别。就好比 int a;我们可以说这是一个声明,也可以说这是一个定义,因为当程序执行到这句话的时候就完成了内存分配。数据类型,变量名,对应的内存单元就已经明确了。多个文件下:
在同一个工程,在多个文件中变量的声明和定义才有区别(比如说在first.c文件中先定义了一个int a;我在second.c中要访问这个a,这时我们需要在second.c这个文件中声明一下);declaration声明:
声明 说明了变量的名字和类型,但并不分配存储空间。definition定义:
定义 也说明了变量的名字和类型,而且还为它分配了存储空间。并不一定要填充初始值initialization初始化:
初始化 是一种特殊的定义,初始化 = 定义的同时并赋初始值。assignment赋值:
将某一个数值 赋值 给一个变量的过程,赋值只针对于已分配存储空间的的变量而言。可以多次进行。在对类成员变量在构造函数内部赋值和在初始值列表中初始化而言,二者具有一些差异,这会影响程序的效率。- 变量能且只能被定义一次,但是可以被多次声明。
- 任何包含了 显示初始化 的 声明 即成为了定义。如果想对一个变量进行声明那么就在变量前加extern关键字,而且不要显示的初始化变量。
3. 注意 结构体变量的 声明定义方式:
struct 结构体名称{
数据类型 member1;
数据类型 member2;
}结构体变量;
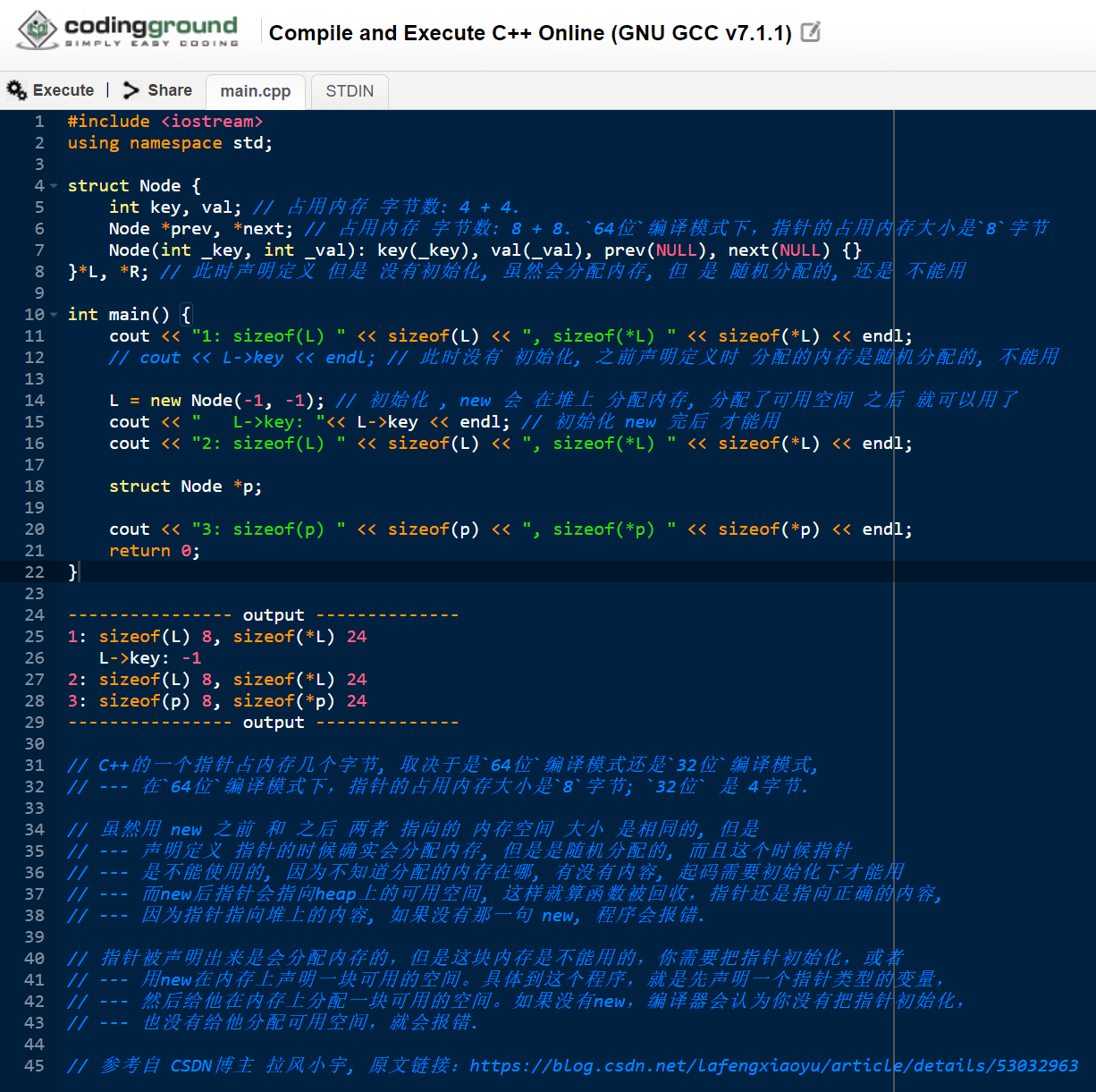
4. C++的一个指针占内存几个字节?
结论: 取决于是64位编译模式还是32位编译模式(注意,和机器位数没有直接关系)
- 在
64位编译模式下,指针的占用内存大小是8字节 - 在
32位编译模式下,指针占用内存大小是4字节
5. 定义 结构体 与 分配 内存
#include <iostream>
using namespace std;
struct Node {
int key, val; // 占用内存 字节数: 4 + 4.
Node *prev, *next; // 占用内存 字节数: 8 + 8. `64位`编译模式下,指针的占用内存大小是`8`字节
Node(int _key, int _val): key(_key), val(_val), prev(NULL), next(NULL) {}
}*L, *R; // 此时声明定义 但是 没有初始化, 虽然会分配内存, 但 是 随机分配的, 还是 不能用
int main() {
cout << "1: sizeof(L) " << sizeof(L) << ", sizeof(*L) " << sizeof(*L) << endl;
// cout << L->key << endl; // 此时没有 初始化, 之前声明定义时 分配的内存是随机分配的, 不能用
L = new Node(-1, -1); // 初始化 , new 会 在堆上 分配内存, 分配了可用空间 之后 就可以用了
cout << " L->key: "<< L->key << endl; // 初始化 new 完后 才能用
cout << "2: sizeof(L) " << sizeof(L) << ", sizeof(*L) " << sizeof(*L) << endl;
struct Node *p;
cout << "3: sizeof(p) " << sizeof(p) << ", sizeof(*p) " << sizeof(*p) << endl;
return 0;
}
---------------- output --------------
1: sizeof(L) 8, sizeof(*L) 24
L->key: -1
2: sizeof(L) 8, sizeof(*L) 24
3: sizeof(p) 8, sizeof(*p) 24
---------------- output --------------
// C++的一个指针占内存几个字节, 取决于是`64位`编译模式还是`32位`编译模式,
// --- 在`64位`编译模式下,指针的占用内存大小是`8`字节; `32位` 是 4字节.
// 虽然用 new 之前 和 之后 两者 指向的 内存空间 大小 是相同的, 但是
// --- 声明定义 指针的时候确实会分配内存, 但是是随机分配的, 而且这个时候指针
// --- 是不能使用的, 因为不知道分配的内存在哪, 有没有内容, 起码需要初始化下才能用
// --- 而new后指针会指向heap上的可用空间, 这样就算函数被回收,指针还是指向正确的内容,
// --- 因为指针指向堆上的内容, 如果没有那一句 new, 程序会报错.
// 指针被声明出来是会分配内存的,但是这块内存是不能用的,你需要把指针初始化,或者
// --- 用new在内存上声明一块可用的空间。具体到这个程序,就是先声明一个指针类型的变量,
// --- 然后给他在内存上分配一块可用的空间。如果没有new,编译器会认为你没有把指针初始化,
// --- 也没有给他分配可用空间,就会报错.
// 参考自 CSDN博主 拉风小宇, 原文链接:https://blog.csdn.net/lafengxiaoyu/article/details/53032963

tql
感谢!!
谢谢总结,复制粘贴该帖子y总到代码不知道为什么在LeetCode复制粘贴会超时。如果知道的话可以麻烦说一下吗?感觉思路跟y总的一模一样。y总的相关代码链接:https://www.acwing.com/activity/content/code/content/405014/
感谢!!!
感谢!!