
分析
i为什么从n/2开始down?
首先要明确要进行down操作时必须满足左儿子和右儿子已经是个堆。
开始创建堆的时候,元素是随机插入的,所以不能从根节点开始down,而是要找到满足下面三个性质的结点:
1.左右儿子满足堆的性质。
2.下标最大(因为要往上遍历)
3.不是叶结点(叶节点一定满足堆的性质)
那这个点为什么时n/2?看图。
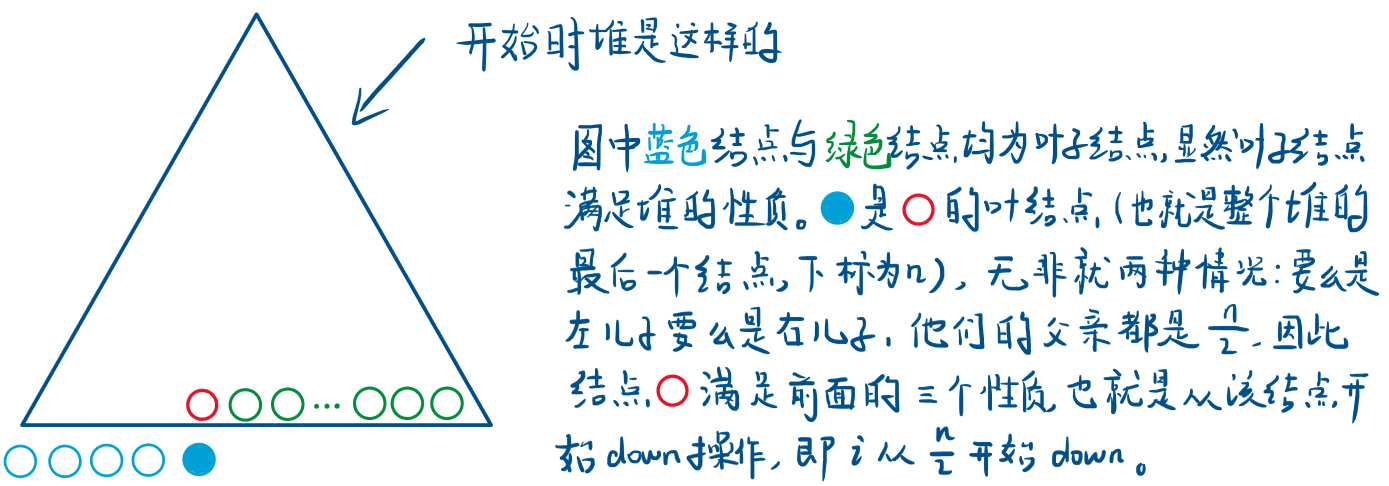
C++ 代码
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010;
int h[N], mySize;
int n, m;
void down(int u)
{
int t = u;
if (2 * u <= mySize && h[t] > h[2 * u])
t = 2 * u;
if (2 * u + 1 <= mySize && h[t] > h[2 * u + 1])
t = 2 * u + 1;
if (u != t)
{
swap(h[u], h[t]);
down(t);
}
}
int main()
{
cin >> n >> m;
mySize = n;
for (int i = 1; i <= n; i++)
scanf("%d", &h[i]);
for (int i = n / 2; i; i--)
down(i);
while (m--)
{
cout << h[1] << " ";
h[1] = h[mySize--];
down(1);
}
return 0;
}
//

我认为从n/2开始,还有一个角度可以理解,因为n是最大值,n/2是n的父节点,因为n是最大,所以n/2是最大的有子节点的父节点,所以从n/2往前遍历,就可以把整个数组遍历一遍
大佬,太棒了,orz,%%%%%%%!
666
卧槽这样理解简单好多!
见你好多次了
6啊
一下就理解了
一上来我就这么想的
你这个说法不成立吧,因为从1开始也可以遍历整个数组啊;真正的原因还是为了满足性质一
大佬 orz!!!
这个理解方式确实通俗易懂,而且记得牢,哈哈哈太牛了
有子节点,只有左也可
那为什么(n+1)/2不行
看到你这条秒懂!
本届评论冠军给予我们的妙脆角同学。
orz
认同
orz
赞同,因为down操作的前提是下标以后的树都需要满足堆的性质
不一定吧,右儿子节点又不一定大于左儿子节点
正解!
我是这样理解的:
首先,n是整个堆的长度,i = n / 2之后我们可以保证在当前 i 这个节点上,必定是有左右两个子节点的,因此满足了down的使用前提。
其次,我们自下向上的顺序处理的话,我们往上走的过程中,由于前面已经将底下的叶子节点排序完成,因此down操作不会向下过深,因此极大的节省了时间,降低了时间的复杂度。
最后,我只想说y总牛逼
本题我的两个疑惑以及对应思考:
1.n/2:就是从最后一个有儿子节点的父节点向前遍历,依次让每个结点找到其合适的位置
2.down(x)是一个递归函数,其含义是为一个相对‘大’的数向下找到其在树中合适的位置,递归式理解的关键
牛币兄弟 我第一次评论题解给你了 搞了好久没懂为啥从2/n开始down 你这个图我看明白了
堆的性质是啥orz…
%%%%%%%%
学完数据结构就明白了
为什么在
for (int i = n / 2; i; i–)
down(i);
这里加个up(),结果反而错了?
我觉得关于i=n/2 开始fdown,可以理解成把堆最下面的一排跳过,转而从倒数第二排开始down。因为每层的个数都是2的n次幂,第一排为一个,第二排为两个,第三排为四个,以此类推
为什么不从(n+1)/2开始呢
最后一个儿子节点如果是右节点,那么它的父节点不应该是(n+1)/2吗
就拿y总举例的那个满二叉树有四层总共是15个节点,所以最后一个儿子节点的下标为15,而第三层的最后一个节点的下标为7,c++的整除会下取整,15/2=7
你确定你的这个父节点的两倍+1还是n吗
妙啊!
为什么必须要有子结点才能down啊?
应该也可以不过没必要吧,down操作是把当前节点与它的左右孩子节点作比较,每次把最小的那个与该节点互换,如果本身就是叶子节点,那就没有左右孩子,也即下面没有比它更大的节点了
h[t]>h[u2]
为什么不能改成 h[u]>h[u2]
兄弟,你明白了嘛,我今天刚开始看,也是这里不懂
因为如果左儿子小于根,则t=u2,在判断h[t]>h[u2+1],是左右儿子比较大小,如果用u,u值不变,还是根和右儿子比较大小,无法判断左右儿子大小,我们需要找到左右儿子及跟根节点最大值。
一直都对这板子印象很模糊,感觉是没理解透彻,看到性质一茅塞顿开
tql大佬 orz
第一条性质让我恍然大悟,谢谢
请问为什么是在比较的时候写的是h[t]和h[2u]比较,写成h[u]和h[2u]比较就错了呢?h[t]和h[u]不是一样的吗?
这个还是不一样的,哈哈,int t = u;
第一个if的时候h[t]和h[u]是一样的,但是第二次if的时候,就不一定了,这个时候有可能第一次if成立,然后t=2*u了,这个t存的是三个数里面最小值得下标,先和左儿子比,如果左儿子小,那么t的下标就存左儿子下标,然后再和右儿子比。 哈哈哈,我也是写错了,看了半个多小时
如果判断的时候不用
h[t],用h[u],像这样:其存在的问题是,只要右儿子值小于本节点,就把
t换成右儿子下标,即使左儿子值比右儿子更小也不行,因为第二个if顺序比第一个if靠后。而我们需要的是本节点、左、右儿子这三个的最小值,如果左儿子比本节点值小,
就应该继续比较左、右儿子哪个小,而不是再用本节点和右儿子去比,这也是为何要用h[t]不用h[u]的原因
down(1)是什么意思啊,不太懂。。
从头结点重新排列一遍,确保下标是1的值,是最小的,然后输出出来,然后删除,依次输出当前堆里面最小的值
$\color{#222}{懂了,谢谢大佬!}$
有绿色节点吗?我怎么看不到
啊,那不是红色节点嘛。hh
我色弱
在红色节点右边(摸摸头)
谢谢 Orz
### momoda
醍醐灌顶