
题目描述
在与联盟的战斗中屡战屡败后,帝国撤退到了最后一个据点。
依靠其强大的防御系统,帝国击退了联盟的六波猛烈进攻。
经过几天的苦思冥想,联盟将军亚瑟终于注意到帝国防御系统唯一的弱点就是能源供应。
该系统由N个核电站供应能源,其中任何一个被摧毁都会使防御系统失效。
将军派出了N个特工进入据点之中,打算对能源站展开一次突袭。
不幸的是,由于受到了帝国空军的袭击,他们未能降落在预期位置。
作为一名经验丰富的将军,亚瑟很快意识到他需要重新安排突袭计划。
他现在最想知道的事情就是哪个特工距离其中任意一个发电站的距离最短。
你能帮他算出来这最短的距离是多少吗?
输入格式
输入中包含多组测试用例。
第一行输入整数T,代表测试用例的数量。
对于每个测试用例,第一行输入整数N。
接下来N行,每行输入两个整数X和Y,代表每个核电站的位置的X,Y坐标。
在接下来N行,每行输入两个整数X和Y,代表每名特工的位置的X,Y坐标。
输出格式
每个测试用例,输出一个最短距离值,结果保留三位小数。
每个输出结果占一行。
数据范围
1≤N≤100000
0≤X,Y≤1000000000
样例
输入样例:
2
4
0 0
0 1
1 0
1 1
2 2
2 3
3 2
3 3
4
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
输出样例:
1.414
0.000
正解
分治+二分(最近点对问题)
算法分析:这是一道经典的最近点对问题的模板,这里略微讲述一下这种问题的解法,首先呢,我们将这些点的x坐标,为第一关键字,y坐标为第二关键字,从小到大排序,接着我们取一个中点mid点,将mid点左边的点,统统归为平面d1,然后mid点右边的点统统归为平面d2如下图所示,图有点丑,不要在意。。。
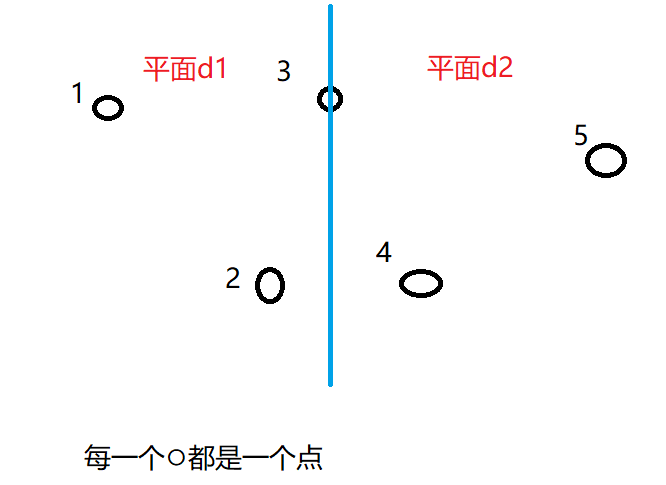
至于mid点可以随便放到一个平面即可,然后我们设ans1为平面d1的最近距离,ans2为平面d2的最近距离,那么最终答案就为ans=min(ans1,ans2),看上取很合理,但是实际上还有一种情况,那就是比如说上图中的2和4,是不是距离更近呢,所以我们还要考虑一种非常恶心的方案,就是左边一个点,右边一个点,而且这两个点距离可能是最小的方案。
最难点就是这个方案,因为有很多高大上的优化,但是实际上玄学优化,就可以让我们很容易地理解这种方法,而且时间复杂度不是很高,满足一般用法。
我们知道,当前局部最优解为ans,那么最终全局的答案肯定是<=ans,这一点很明确,既然如此,那么最终答案的点对,就只可能在下图中的区域里面出现,因为如果不在这个区域,那么肯定是大于ans的。
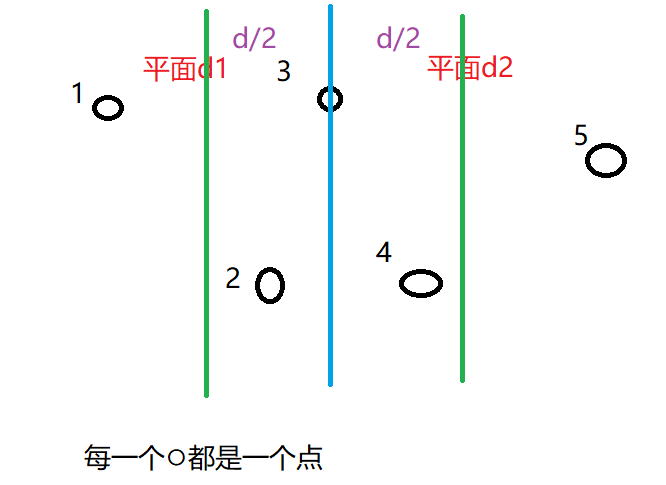
既然如此,那么我们就可以只需要在这个区域里面寻找答案即可,至于寻找的过程,我们还要注意一点,那就是我们需要将这个区间里面的数,将y坐标排序,从小到大,这样便于我们接下来的break剪枝,具体实现看代码。
C++ 代码
#include <cstdio>
#include <algorithm>
#include <iostream>
#include <cmath>
#include <cstring>
using namespace std;
const int N=100100;
struct node
{
double x,y;
int f;
} a[N<<1],t[N<<1];
int n,m,i,j,k;
#define INF 1e8
int cmp(node a,node b)
{
if (a.x==b.x)
return a.y<b.y;
return a.x<b.x;
}
int cmp2(node a,node b)
{
if (a.y==b.y)
return a.x<b.x;
return a.y<b.y;
}
double dist(node a,node b)
{
if (a.f==b.f)
return INF;
double dx=(a.x-b.x),dy=(a.y-b.y);
return sqrt(dx*dx+dy*dy);
}
double work(int l,int r)
{
int mid=(l+r)>>1;
if (r-l==0)
return INF;
if (r-l==1)
return dist(a[l],a[r]);
double ans=min(work(l,mid),work(mid+1,r));
int cnt=0;
for (int i=l;i<=r;i++)
if (a[i].x>=a[mid].x-ans && a[i].x<=a[mid].x+ans)
t[++cnt]=a[i];
sort(t+1,t+1+cnt,cmp2);
for (int i=1;i<=cnt;i++)
for (int j=i+1;j<=cnt;j++)
{
if (t[j].y>=t[i].y+ans)
break;
ans=min(ans,dist(t[i],t[j]));
}
return ans;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
for (i=1; i<=n; i++)
{
scanf("%lf%lf",&a[i].x,&a[i].y);
a[i].f=0;
}
for (i=n+1; i<=n<<1; i++)
{
scanf("%lf%lf",&a[i].x,&a[i].y);
a[i].f=1;
}
n<<=1;
sort(a+1,a+1+n,cmp);
printf("%0.3lf\n",work(1,n));
}
}

请问一下这样写常数有多大呢QAQ
不是很大啊,估计小于2
常数不是应该在6左右吗?
###这份代码TLE了
if (a.f==b.f)
return INF;
妙啊
巨佬,这个解法的时间复杂度是多少a?是 O(nlogn) 还是 O(nlog2n) 鸭?
你这个 做法 不对 ,复杂度最坏会超过 n^2 ,
比如
1
100000
1 1
1 2
.....
.....
1 100000
3 1
3 2
3 3
…
.....
3 100000
这组数据就跑过了
https://paste.ubuntu.com/p/gDr6CYDnGd/
看看我这个,排序占了总时间的90%
也一样没有用,数据集刁钻的话最坏有n*n复杂度,这题感觉没这么简单,要适配所有数据集的话估计得写很麻烦
大佬,为什么这道题在这里能过,在poj上会wa啊qwq
您发一下POJ连接?
http://poj.org/problem?id=3714
收到,正在上算法提高班
大佬 为什么我这份代码在CH上能过 但是在这里过不了呀 在这里会超时。望看下。
#include"stdio.h" #include"string.h" #include"math.h" #include"algorithm" using namespace std; #define INF 10001010 typedef struct Node { int x,y; int id; }Node; int T,n; Node node[200010]; Node cnt[200010]; int cmp1(Node a,Node b) { if(a.x == b.x) return a.y < b.y; return a.x < b.x; } double dist(int x,int y) { if(node[x].id == node[y].id) return INF; return sqrt((node[x].x - node[y].x) * (node[x].x - node[y].x) + (node[x].y - node[y].y) *(node[x].y - node[y].y) ); } int cmp2(Node a,Node b) { if(a.y == b.y) return a.x < b.x; return a.y < b.y; } double dist1(int x,int y) { if(cnt[x].id == cnt[y].id) return INF; return sqrt((cnt[x].x - cnt[y].x) * (cnt[x].x - cnt[y].x) + (cnt[x].y - cnt[y].y) *(cnt[x].y - cnt[y].y) ); } double work(int left,int right) { double ans; int mid = (left + right) >> 1; if(left == right) return INF; if(left + 1 == right) return dist(left,right); ans = min(work(left,mid),work(mid + 1,right)); int k = 0; for(int i = 1; i <= n; i ++) { if(node[i].x >= node[mid].x - ans && node[i].x <= node[mid].x + ans) cnt[k ++]= node[i]; } sort(cnt,cnt + k,cmp2); for(int i = 0; i < k - 1; i ++) for(int j = i + 1; j < k; j ++) if(cnt[j].y > cnt[i].y + ans) break; else ans = min(ans,dist1(i,j)); return ans; } int main() { scanf("%d",&T); while(T --) { scanf("%d",&n); for(int i = 1; i <= n; i ++) { scanf("%d%d",&node[i].x,&node[i].y); node[i].id = 0; } for(int i = n + 1;i <= n << 1; i ++) { scanf("%d%d",&node[i].x,&node[i].y); node[i].id = 1; } n = n << 1; sort(node + 1,node + 1 + n,cmp1); double ans = work(1,n); printf("%.3lf\n",ans); } }CH和Acwing都是同样的数据点,按理说不会出这种TLE的BUG的.因此我推测可能是常数问题,建议开O2测试一下.
大佬 能说下开O2是什么测试方法吗 有点菜
开头处打.
#pragma GCC optimize(2) #pragma G++ optimize(2)大佬 我改了一下 一开始代码有点小问题。 然后加了两个语句。这个有tle变wa了 。但是在ch上还是能过~~~
emm,这你把代码发给我一下,我看看吧.Ch什么时候这么弱了.......