
匈牙利算法**
-
思路
二分图的匹配:给定一个二分图 GG,在 GG 的一个子图 MM 中,MM 的边集 {E}{E} 中的任意两条边都不依附于同一个顶点,则称 MM 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
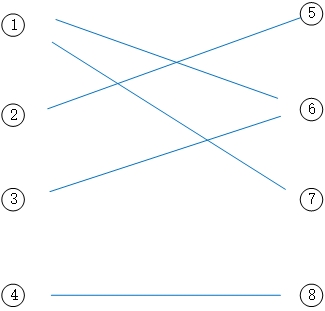
如图,节点 $1$ 与节点 $6$ 匹配成功,但节点 $3$ 也需要且只能与节点 $6$ 进行匹配,这时我们可以将节点 $1$ 更改为与节点 $7$ 进行匹配,这时候我们就可以得到该二分图的最大匹配数为4。
我们可以用一个数组match来记录右半部分节点与左半部分节点匹配的节点,每次将左半部分节点进行遍历,查找能够匹配的节点(即边),如果查找并匹配成功,就将右边那个节点的 $match$ 值进行记录。如果需要匹配的右边那个节点已经被占用,就通过当前占用的那个节点再进行查找,若成功找到该节点能够与另一个节点进行匹配,就取消占用,并占用另一个可以匹配的节点。最终我们就能得到该二分图的最大匹配。
-
步骤
-
对所有节点和边进行初始化,使用邻接表存储。
- 对左半部分节点进行遍历,并在每次遍历中将 $st$ 数组初始化为false,表示为该节点还未尝试匹配的节点的集合,然后查找该节点的所有邻接边。
- 遍历该节点 $i$ 的所有邻接边,如果该边的节点 $j$ 未尝试匹配过,就查找该节点 $j$ 是否被占用,如果没有被占用或者通过对占用该节点的节点(即当前 $match[j]$ 中记录的节点)进行查找匹配能够成功,就将 $match[j]$ 记录为节点 $i$ ,并返回 $true$ 。如果该边的节点 $j$ 已经尝试匹配过或者该节点 $j$ 已经被另一个结点匹配且无法更改,那就继续查看下一条邻接边。
-
如果所有的边都无法满足匹配,将结果返回 $false$ 。
-
例题
给定一个二分图,其中左半部包含 $n_1$ 个点(编号 $1∼n_1$ ),右半部包含 $n2$ 个点(编号 $1∼n_2$),二分图共包含 $m$ 条边。
数据保证任意一条边的两个端点都不可能在同一部分中。
请你求出二分图的最大匹配数。
二分图的匹配:给定一个二分图 $G$,在 $G$ 的一个子图 $M$ 中,$M$ 的边集 $\left\{E\right\}$ 中的任意两条边都不依附于同一个顶点,则称 $M$ 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
输入格式
第一行包含三个整数 $n_1$、 $n_2$ 和 $m$。
接下来 $m$ 行,每行包含两个整数 $u$ 和 $v$,表示左半部点集中的点 $u$ 和右半部点集中的点 $v$ 之间存在一条边。
输出格式
输出一个整数,表示二分图的最大匹配数。
数据范围
$1≤n_1,n_2≤500$,
$1≤u≤n_1$,
$1≤v≤n_2$,
$1≤m≤10^5$
输入样例:
2 2 4
1 1
1 2
2 1
2 2
输出样例:
2
-
代码
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, M = 1e5+10;
int h[N], e[M], ne[M], idx;
int match[N], n1, n2, m;
bool st[N];
void add(int a, int b)
{
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
bool find(int ver)
{
for(int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if(!st[j])
{
st[j] = true;
if(match[j] == 0 || find(match[j]))
{
match[j] = ver;
return true;
}
}
}
return false;
}
int main()
{
cin >> n1 >> n2 >> m;
memset(h, -1, sizeof(h));
while(m--)
{
int a, b;
cin >> a >> b;
add(a,b);
}
int res = 0;
for(int i = 1; i <= n1; i++)
{
memset(st, false, sizeof(st));
if(find(i)) res++;
}
cout << res <<endl;
return 0;
}
